Migrating Buckets to Collections & Scopes via Eventing: Part 2
Again (as I did in Part 1) I want to point out an excellent blog written by Shivani Gupta, How to Migrate to Scopes & Collections in Couchbase 7.0, which covers in great detail other methods of migrating bucket-based documents to Scopes and Collections in Couchbase. I encourage you to also read about the multiple non-Eventing methods that Shivani touches upon.
Whether you’re new to Couchbase or a seasoned vet, you’ve likely heard about Scopes and Collections. If you’re ready to try them, this article helps you make it happen.
Scopes and Collections are a new feature introduced in Couchbase Server 7.0 that allows you to logically organize data within Couchbase. To learn more, read this introduction to Scopes and Collections.
You should take advantage of Scopes and Collections if you want to map your legacy RDBMS to a document database or if you’re trying to consolidate hundreds of microservices and/or tenants into a single Couchbase cluster (resulting in much lower TCO).
Using Eventing for Scopes & Collections Migration
In the prior article (Part 1), I discussed the mechanics of a high performance method to migrate from an older Couchbase version to Scopes and Collections in Couchbase 7.0 based on Eventing.
Just the Data Service (or KV) and the Eventing Service is required to migrate from buckets to collections. In a well-tuned, large Couchbase cluster, you can migrate over 1 million documents a second. Yes, no N1QL, and no index needed.
In this follow up article, I will provide a simple fully automated methodology to do large migrations with dozens (or even hundreds) of data types via a simple Perl script.
Recap of the final Eventing Function: ConvertBucketToCollections
In Part 1 we had the following settings for the Eventing Function. Note to each unique type, “beer” and “brewery” we had to add a Bucket binding alias to the target collection in “read+write” mode. In addition we had to create the target collections, in this case “bulk.data.beer” and “bulk.data.brewery“
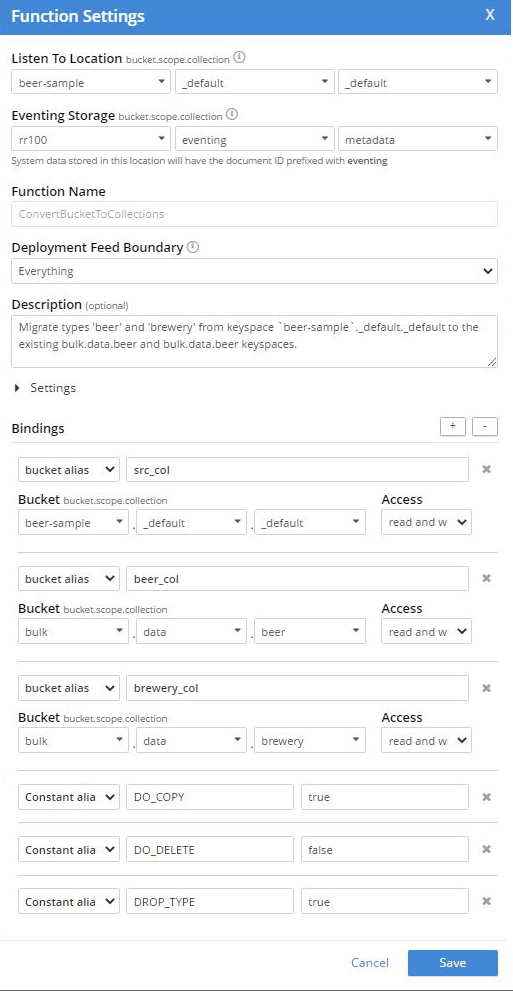
In Part 1 we had the following JavaScript code in our Eventing Function. Note to each unique type, “beer” and “brewery” we had to replicate a JavaScript code block and update reference the corresponding binding alias or target collection in the Couchbase Data Service.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
function OnUpdate(doc, meta) { if (!doc.type) return; var type = doc.type; if (DROP_TYPE) delete doc.type; if (type === 'beer') { if (DO_COPY) beer_col[meta.id] = doc; if (DO_DELETE) { if(!beer_col[meta.id]) { // safety check log("skip delete copy not found type=" + doc.type + ", meta.id=" + meta.id); } else { delete src_col[meta.id]; } } } if (type === 'brewery') { if (DO_COPY) brewery_col[meta.id] = doc; if (DO_DELETE) { if(!brewery_col[meta.id]) { // safety check log("skip delete copy not found type=" + doc.type + ", meta.id=" + meta.id); } else { delete src_col[meta.id]; } } } } |
The technique in Part 1 works but what if I have a lot of types?
Using Eventing can indeed do migrations as shown in Part 1, but it seems like a bit of work to set things up.
If you have 80 different types, it would be an incredible amount of error-prone effort to use this technique (both creating the Eventing Function and creating the needed keyspaces). If I had 80 types in a bucket to migrate and split, I wouldn’t want to do all the work described above by hand for each type.
Automate via CustomConvertBucketToCollections.pl
To solve this problem, I wrote a tiny Perl script, CustomConvertBucketToCollections.pl, that generates two files:
- CustomConvertBucketToCollections.json, is a complete Eventing Function which does all of the above work described in this post.
- MakeCustomKeyspaces.sh, is a shell file to build all the needed keyspaces and import the generated Eventing function.
You can find this script in GitHub at https://github.com/jon-strabala/cb-buckets-to-collections.
Note, the script CustomConvertBucketToCollections.pl requires that both Perl (practical extraction and report language) and also jq (a lightweight and flexible command-line JSON processor) are installed on your system.
Example: Migrate 250M Records with 80 Different Types
We have 250M documents in keyspace “input._default._default” with 80 different types and want to reorganize the data by type into collections under the scope “output.reorg” by the property type. We have an AWS cluster of three r5.2xlarge instances, all running the Data Service and the Evening Service.
The input bucket “input” in this example is configured with a memory quota of 16000 MB.
Below I use the CustomConvertBucketToCollections.pl Perl script from GitHub at https://github.com/jon-strabala/cb-buckets-to-collections. As you can see it can be trivial to do migrations using an automated script.
Step 1: One-time Setup
|
1 2 3 4 5 6 |
git clone https://github.com/jon-strabala/cb-buckets-to-collections cd cb-buckets-to-collections PATH=${PATH}:/opt/couchbase/bin cd cb-buckets-to-collections/ chmod +x CustomConvertBucketToCollections.pl big_data_test_gen.pl big_data_test_load.sh |
Step 2: Create 250M test documents
Running the interactive big_data_test_load.sh command:
|
1 |
./big_data_test_load.sh |
Input configuration parameters:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# This bash script, 'big_data_test_load.sh', will load <N> million test # documents into a <bucket>._default._default in 1 million chunks as # created by the perl script 'big_data_test_gen.pl'. The data will # have 80 different document type values evenly distributed. Enter the number of test docs to create in the millions 250 Enter the bucket (or target) to load test docs into input Enter the username:password to your cluster admin:jtester Enter the hostname or ip address of your cluster localhost Enter the number of threads for cbimport 8 Will load 2 million test docs into keyspace input._default._default (the default for bucket input) type ^C to abort, running in 5 sec. Running .... gen/cbimport block: 1 of 2, start at Mon 01 Nov 2021 11:06:01 AM PDT JSON `file://./data.json` imported to `couchbase://localhost` successfully Documents imported: 1000000 Documents failed: 0 ** removed 23 lines ** gen/cbimport block: 250 of 250, start at Mon 01 Nov 2021 11:24:05 AM PDT JSON `file://./data.json` imported to `couchbase://localhost` successfully Documents imported: 1000000 Documents failed: 0 |
There should now be 250M test documents in the keyspace input._default._default.
Step 3: Generate Eventing Function and Keyspace script
Running the interactive CustomConvertBucketToCollections.pl command:
|
1 |
./CustomConvertBucketToCollections.pl |
Input configuration parameters:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
Enter the bucket (or source) to convert to collections [travel-sample]: input Enter the username:password to your cluster [admin:jtester]: Enter the hostname or ip address of your cluster [localhost]: Enter the destination bucket.scope [mybucket.myscope]: output.reorg Enter the Eventing storage keyspace bucket.scope.collection [rr100.eventing.metadata]: Enter the number of workers (LTE # cores more is faster) [8]: Probe the bucket (or source) to determine the set of types [Y]: samples across the bucket (or source) to find types [20000]: 100000 maximum estimated # of types in the bucket (or source) [30]: 100 Scanning input for 'type' property this may take a few seconds curl -s -u Administrator:password http://localhost:8093/query/service -d \ 'statement=INFER `input`._default._default WITH {"sample_size": 100000, "num_sample_values": 100, "similarity_metric": 0.1}' \ | jq '.results[][].properties.type.samples | .[]' | sort -u TYPES FOUND: t01 t02 t03 t04 t05 t06 t07 t08 t09 t10 t11 t12 t13 t14 t15 t16 t17 t18 t19 t20 t21 t22 t23 t24 t25 t26 t27 t28 t29 t30 t31 t32 t33 t34 t35 t36 t37 t38 t39 t40 t41 t42 t43 t44 t45 t46 t47 t48 t49 t50 t51 t52 t53 t54 t55 t56 t57 t58 t59 t60 t61 t62 t63 t64 t65 t66 t67 t68 t69 t70 t71 t72 t73 t74 t75 t76 t77 t78 t79 t80 Generating Eventing Function: CustomConvertBucketToCollections.json Generating Keyspace commands: MakeCustomKeyspaces.sh |
In the interactive Perl script above, four of the above default choices were altered.
Step 3: Update the MakeCustomKeyspaces.sh (as needed)
You can just “vi MakeCustomKeyspaces.sh” and alter any needed values. I choose to use the Unix sed command to increase the RAM size of the bucket “output” from 100 to 1600
|
1 2 |
cat MakeCustomKeyspaces.sh | sed -e 's/\(^.*bucket=output.*ramsize=\)100 \(\.*\)/\116000 \2/' > tmp mv tmp MakeCustomKeyspaces.sh |
Step 4: Run the MakeCustomKeyspaces.sh script
|
1 |
sh ./MakeCustomKeyspaces.sh |
output below:
|
1 2 3 4 5 6 7 8 9 10 |
SUCCESS: Bucket created SUCCESS: Scope created SUCCESS: Collection created SUCCESS: Bucket created SUCCESS: Scope created SUCCESS: Collection created SUCCESS: Collection created ** removed 77 lines ** SUCCESS: Collection created SUCCESS: Events imported |
Step 5: Refresh your Couchbase UI on the Eventing Page
To find the new Eventing Function (or updated Function) in the Couchbase UI, go to the Eventing Page and refresh your web browser.
Step 6: Deploy CustomConvertBucketToCollections
In the Couchbase UI, go to the Eventing Page and deploy the Eventing Function “CustomConvertBucketToCollections“.
In about 45 minutes the reorganization should be completely done.
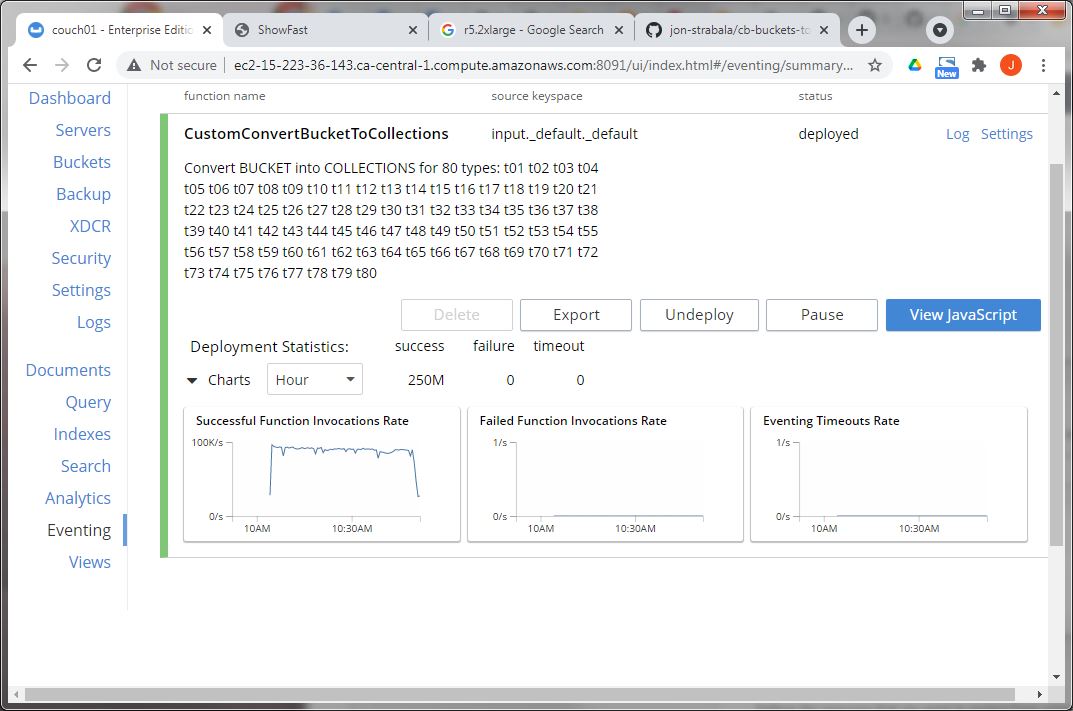
All the documents are indeed reorganized by type as collections. On this modest cluster, they were processed at 93K docs/sec.
Final Thoughts
If you found this article series helpful and are interested in continuing to learn about eventing – click here the Couchbase Eventing Service.
I hope you find the CustomConvertBucketToCollections.pl Perl script from GitHub at https://github.com/jon-strabala/cb-buckets-to-collections a valuable tool in your arsenal when you need to migrate a bucket with many types into a collections paradigm.
Feel free to improve the CustomConvertBucketToCollections.pl script to use an intermediate config file to the Eventing Perl tool where all the parameters could be adjusted. Then use the intermediate config file to create the Eventing Function and the setup shell script.
Example intermediate config file:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
[ { "src_ks": "input._default._default", "dst_ks": "output.myscope.t01", "create_dst_ks": true, "dst_copy": true, "src_del": true, "dst_remove_type": true }, { "src_ks": "input._default._default", "dst_ks": "output.myscope.t02", "create_dst_ks": true, "dst_copy": true, "src_del": true, "dst_remove_type": true }, { "src_ks": "input._default._default", "dst_ks": "output.myscope.t03", "create_dst_ks": true, "dst_copy": true, "src_del": true, "dst_remove_type": true } ] |
Resources
- Download: Download Couchbase Server 7.0
- Eventing Scriptlet: Function: ConvertBucketToCollections
- GitHub: Perl Tool: cb-buckets-to-collections.pl
References
- Couchbase Eventing documentation
- What’s New: Couchbase Server 7.0
- How to Migrate to Scopes & Collections in Couchbase 7.0
- Other Couchbase blogs on Eventing
I would love to hear from you on how you liked the capabilities of Couchbase and the Eventing service, and how they benefit your business going forward. Please share your feedback via the comments below or in the Couchbase forums.