- Desarrolladores
-
-
COMUNIDAD

Únase a la comunidad de desarrolladores
Explore los recursos para desarrolladores, embajadores y eventos de su zona.
Más información
-
-
Couchbase Multi-Dimensional Scaling es una innovadora tecnología de bases de datos que aumenta sustancialmente el rendimiento de las aplicaciones y reduce drásticamente los costes. Multi-Dimensional Scaling logra estas ganancias con la opción de separar, aislar y escalar servicios individuales de bases de datos - consultas, índices y datos - permitiéndole soportar más de un perfil de hardware para que los recursos puedan ser optimizados para un solo servicio. El resultado es que puede ejecutar consultas complejas, crear índices ilimitados y seguir escalando datos en muchos nodos sin preocuparse de que el rendimiento se resienta.
Otras bases de datos, como MongoDB, Oracle y Cassandra, tienen un enfoque limitante de escalado de talla única que obliga a ejecutar cada servicio de base de datos en cada nodo. Este enfoque conduce a la contención de recursos, un rendimiento más lento, capacidades de consulta limitadas, y el aprovisionamiento excesivo. Couchbase Server con Multi-dimensional Scaling elimina todas estas limitaciones, lo que resulta en un mayor rendimiento, a mayor escala, todo a un menor costo.
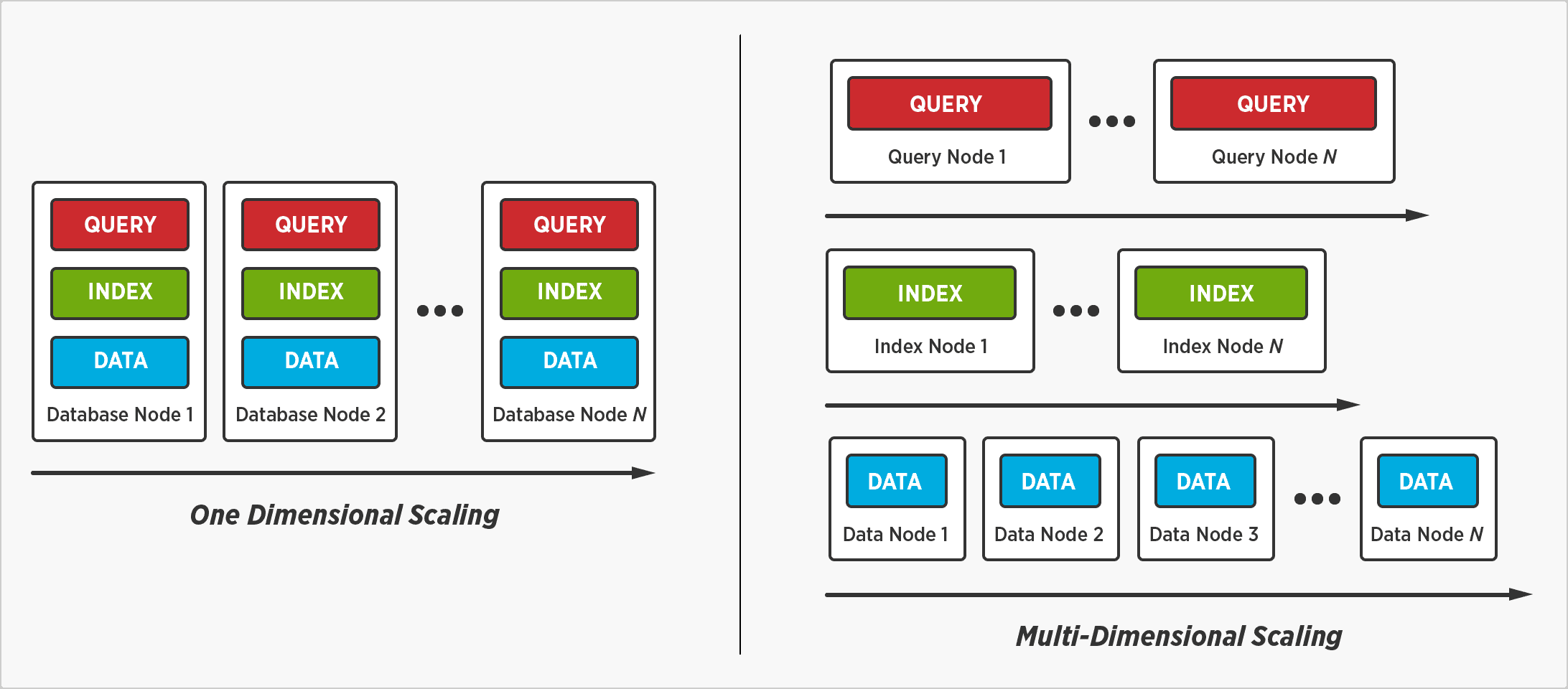
¿Por qué es necesaria la escala multidimensional?
En pocas palabras, el escalado de datos acelera las lecturas y escrituras, pero ralentiza las consultas, y la creación de índices acelera las consultas, pero ralentiza las escrituras. Por ejemplo, si escalas tu base de datos para soportar una cantidad masiva de datos, el rendimiento de las consultas se resentirá drásticamente porque cuantos más nodos participen en una consulta distribuida, peor será su rendimiento. Y la creación de muchos índices para mejorar el rendimiento de las consultas afectará negativamente al rendimiento de las escrituras, ya que éstas no se completan hasta que se han actualizado todos los índices. La conclusión es que el escalado, con cada servicio de base de datos ejecutándose en cada nodo, puede resultar en una gran caída de la eficiencia y el rendimiento.
¿Cómo se benefician los servicios de bases de datos del aislamiento?
Las consultas requieren procesadores rápidos
Si una consulta puede ser ejecutada por un solo nodo, o muchas consultas por muchos nodos, los resultados se devolverán más rápido, y no ralentizará las lecturas y escrituras monopolizando el tiempo de CPU.
Los índices requieren unidades SSD de alto rendimiento
Si un índice se puede almacenar en un solo nodo, o muchos índices en muchos nodos, se puede buscar más rápido, y no ralentizará las escrituras monopolizando la IO de disco.
Los datos son la razón de ser de una base de datos distribuida
Cuantos más nodos tenga, más datos podrá almacenar. Estos nodos se benefician de una mayor memoria, pero exigen menos a la CPU y al disco. Cuando los datos se aíslan de las consultas y los índices, el rendimiento de lectura y escritura no sólo mejora, sino que se mantiene constante.
Ventajas del aislamiento
| Consulta | Índice | Datos | |
|---|---|---|---|
| Optimización de recursos | Tratamiento | Almacenamiento | Memoria |
| Ventajas del aislamiento | Las consultas son más rápidas.
Las consultas no ralentizan las lecturas ni las escrituras. Escalar el servicio de consulta no obliga a reequilibrar los datos. No hay contención de CPU con los servicios de índices y datos.
|
Los índices se consultan más rápidamente. Los índices no ralentizan las escrituras. Escalar el servicio de índices no obliga a reequilibrar los datos. No hay contención de IO de disco con el servicio de datos. No hay límite en el número de índices.
|
Las lecturas y escrituras son más rápidas.
El escalado de datos no ralentiza las consultas ni las búsquedas de índices. Escalar el servicio de datos no obliga a reequilibrar los índices. No hay contención de recursos con los servicios de consulta e índice.
|
| Requisitos de hardware | Procesador rápido
Menos memoria HDD
|
Procesador básico
Menos memoria SSD
|
Procesador básico
Más memoria Disco duro o SSD
|
Cómo funciona el escalado multidimensional
El escalado multidimensional permite separar y aislar los servicios de base de datos -consulta, indexación y datos- para poder escalar y optimizar los recursos de cada uno en función de su propia carga de trabajo individual.
- Las consultas y los índices funcionarán mejor porque ya no necesitarán todos los nodos.
- Toda la aplicación funcionará mejor, ya que las lecturas, escrituras y consultas dejarán de competir por los recursos compartidos.
- Sus costes de hardware disminuirán, ya que podrá aplicar servidores más grandes para las consultas y los índices, y servidores más pequeños para los datos.
Los beneficios son impactantes e inmediatos.
Prestación técnica
- Mejora del rendimiento de las aplicaciones
- Estabilidad mejorada de la aplicación
- Mejor utilización de los recursos
- Mejora de la eficacia operativa
Beneficio empresarial
- Mejor experiencia del cliente
- Experiencia del cliente coherente
- Menores costes de hardware
- Reducción de los gastos administrativos