- Desarrolladores
-
-
COMUNIDAD

Únase a la comunidad de desarrolladores
Explore los recursos para desarrolladores, embajadores y eventos de su zona.
Más información
-
-
Visión general: Estructura y conceptos clave de NoSQL
Para entender mejor cómo funcionan las bases de datos NoSQL, esta página cubre:
¿Qué es una base de datos NoSQL?
Una base de datos NoSQL, abreviatura de "not only SQL (Structured Query Language)", es una base de datos no relacional diseñada para manejar estructuras de datos diversas y flexibles. La definición NoSQL se refiere a bases de datos que admiten múltiples modelos -incluidos almacenes de documentos, gráficos, clave-valor, columnas anchas y vectores- que ofrecen una mayor escalabilidad y adaptabilidad en comparación con las bases de datos SQL tradicionales, que se basan en tablas estructuradas y esquemas fijos.
El significado de NoSQL ha evolucionado con los avances en CPU, RAM, computación en la nube e interacciones de IA, lo que permite a las bases de datos modernas gestionar eficientemente grandes conjuntos de datos en tiempo real. Al priorizar escala horizontal y rendimiento, las bases de datos NoSQL garantizan una distribución fluida de los datos en múltiples nodos, lo que las convierte en la opción preferida para la IA, el big data y el análisis en tiempo real, donde las bases de datos tradicionales a menudo tienen dificultades para seguir el ritmo.
NoSQL hace referencia a las bases de datos que almacenan datos en formatos flexibles utilizando modelos como documentos, almacenes clave-valor y almacenes vectoriales. Su escalabilidad y rendimiento las hacen ideales para aplicaciones modernas que requieren acceso en tiempo real y manejan grandes cargas de trabajo dinámicas.
¿Cuál es la diferencia entre SQL y NoSQL?
Bases de datos SQL y NoSQL difieren en la forma de almacenar y consultar los datos. Las bases de datos SQL se basan en tablas con columnas y filas para recuperar y escribir datos estructurados, mientras que las bases de datos NoSQL utilizan modelos de datos flexibles más adecuados para datos no estructurados y semiestructurados.
SQLSQL, introducido por primera vez en los años 70, es utilizado actualmente por desarrolladores y analistas de datos de todo el mundo para buscar datos almacenados en sistemas relacionales e informar sobre ellos. Las bases de datos SQL son ideales para aplicaciones que requieren integridad de los datos y utilizan relaciones estructuradas y consultas estandarizadas (por ejemplo, software de planificación de recursos empresariales). Aunque NoSQL existe desde los años 60, pero el término se acuñó a principios de la década de 2000, cuando se hizo crucial para los desarrolladores utilizar bases de datos capaces de almacenar y recuperar datos para aplicaciones en tiempo real.
Cabe señalar que SQL se ha ido ampliando para admitir patrones de acceso NoSQL. Por ejemplo, muchas bases de datos relacionales admiten ahora JSON (JavaScript Object Notation) como tipo de datos. Algunas bases de datos incluso han extendido SQL para consultar directamente estructuras JSON, incluyendo Couchbase, que soporta SQL++ (SQL para JSON).
La diferencia entre las bases de datos SQL y NoSQL radica en su estructura y casos de uso. Las bases de datos SQL utilizan tablas, lo que las hace ideales para aplicaciones que requieren una estructura rígida y datos normalizados. En cambio, las bases de datos NoSQL utilizan modelos flexibles, lo que las hace más adecuadas para manejar datos no estructurados y semiestructurados, al tiempo que permiten el acceso en tiempo real.
Tipos de bases de datos NoSQL
Estos son los tipos más populares de patrones de acceso a bases de datos NoSQL:
- Almacenes clave-valor agrupan los datos asociados en tablas independientes en las que los registros se identifican mediante claves únicas para facilitar su recuperación. Tienen la estructura justa para reflejar el valor de las bases de datos relacionales al tiempo que añaden las ventajas de rendimiento y accesibilidad de una estructura de acceso a datos NoSQL. Los datos clave-valor se almacenan fácilmente en una caché donde los datos a los que se accede con frecuencia se mantienen en memoria para lecturas rápidas. Las escrituras, actualizaciones y nuevas solicitudes de lectura se dirigen mediante programación al almacenamiento persistente. Los almacenes de clave-valor priorizan las velocidades de acceso atómico por encima de la coherencia, el aislamiento y la durabilidad.
- Bases de datos documentales almacenan principalmente información en forma de documentos lógicos, incluidos los documentos JSON. Por ejemplo, estos sistemas también pueden almacenar documentos XML u objetos binarios. Debido a la naturaleza flexible del formato y al grado de control que proporciona a los desarrolladores, las bases de datos de documentos son las preferidas a la hora de crear aplicaciones basadas en datos.
- Bases de datos de columnas y columnas anchas almacenar datos por columnas en lugar de filasque optimiza el rendimiento de las consultas para cargas de trabajo analíticas y procesamiento de datos a gran escala. Al igual que los almacenes clave-valor, las bases de datos de columnas anchas tienen cierta estructura NoSQL básica, al tiempo que conservan la flexibilidad, el manejo de datos y las capacidades de agregación.
- Buscar en bases de datos permiten a los usuarios consultar datos semiestructurados y no estructurados, como páginas web, documentos, mapas y documentos JSON y XML. Utilizan índices invertidos especializados para localizar palabras clave dentro de cuerpos de texto con el fin de encontrar datos relevantes, de forma similar a "googlear" algo en línea.
- Bases de datos gráficas utilizan estructuras gráficas como nodos, aristas y propiedades para definir las relaciones entre los elementos de datos almacenados. Las bases de datos de grafos son útiles para identificar patrones de relación en sin estructurar y semiestructurado información, creando redes sociales, conjuntos de piezas, estructuras organizativas y ontologías. Las bases de datos de grafos se utilizan mucho en motores de recomendación, reconocimiento de patrones de fraude, funciones de IA predictiva y vinculación de redes sociales.
- Bases de datos de series temporales permiten a los usuarios seguir los cambios de los datos a lo largo del tiempo y detectar anomalías en gráficos de cotizaciones bursátiles, registros de máquinas, monitores de salud y sistemas de alerta. Dado que los datos de series temporales cambian con rapidez, estas bases de datos generan cantidades ingentes de información, lo que puede plantear problemas de escalabilidad.
- Bases de datos vectoriales ayudan a mejorar la precisión de los modelos generativos de IA proporcionando pistas (vectores) que ayudarles a encontrar las respuestas "correctas dentro de sus datos de entrenamiento. Las bases de datos vectoriales funcionan dentro de los procesos de generación aumentada por recuperación (RAG) para almacenar incrustaciones vectoriales que ayudan a reducir las alucinaciones de la IA generativa y a mantener el progreso del modelo.
Entre los patrones de acceso a datos NoSQL más populares se encuentran los almacenes de clave-valor, las bases de datos de documentos, las bases de datos de columnas anchas y columnares, las bases de datos de búsqueda, las bases de datos de gráficos, las bases de datos de series temporales y las bases de datos vectoriales. Cada uno de estos tipos de NoSQL tiene características únicas, como la escalabilidad, la flexibilidad del esquema y la eficiencia de las consultas. Deberías explorarlos en profundidad para decidir qué base de datos NoSQL utilizar.
¿Por qué utilizar NoSQL?
Las empresas prefieren las bases de datos NoSQL por su capacidad para manejar grandes volúmenes de datos diversos y crecientes. Las ventajas específicas de las bases de datos NoSQL incluyen:
- Escalabilidad: Las bases de datos NoSQL escalan horizontalmente distribuyendo los datos entre varios servidores, lo que las hace ideales para grandes cargas de trabajo.
- Flexibilidad: A diferencia de las bases de datos relacionales, NoSQL permite almacenar datos sin esquema, lo que facilita el almacenamiento y la gestión de datos no estructurados o semiestructurados.
- Alto rendimiento: Optimizadas para lecturas y escrituras rápidas, las bases de datos NoSQL reducen la complejidad de las consultas y mejoran los tiempos de respuesta de las aplicaciones en tiempo real.
- Varios modelos de datos: Las bases de datos NoSQL favorecen los modelos de datos clave-valor, documento, columna ancha, búsqueda y series temporales, lo que las hace ideales para múltiples casos de uso.
- Big data y procesamiento en tiempo real: NoSQL está diseñado para manejar cantidades masivas de datos, por lo que es ideal para análisis de macrodatosIoT y gestión de sesiones y caché.
- Nube y computación distribuida: Las bases de datos NoSQL funcionan bien en entornos de nube al garantizar una alta disponibilidad y tolerancia a fallos en los sistemas distribuidos.
- Desarrollo e iteración más sencillos: Con NoSQL, los desarrolladores pueden aprovechar sus conocimientos de SQL y utilizar una base de datos que se integra con herramientas conocidas, entornos de desarrollo integrados (IDE)y marcos.
La base de datos NoSQL polivalente de Couchbase es especialmente adecuada para aplicaciones de IA porque ofrece:
1. Alto rendimiento y baja latencia
- Arquitectura que da prioridad a la memoria: Utiliza un diseño de memoria distribuida para lecturas y escrituras rápidas, lo que reduce la latencia de inferencia del modelo de IA.
- Tiempos de respuesta inferiores al milisegundo: Garantiza el acceso a los datos en tiempo real, lo que es crucial para casos de uso como motores de recomendacióndetección del fraude y análisis predictivo.
2. Escalabilidad y arquitectura distribuida
- Escalado multidimensional: Puede escalarse horizontal o verticalmente para gestionar conjuntos de datos de IA masivos y cargas de trabajo crecientes.
- Replicación entre centros de datos (XDCR): Admite despliegues de IA multirregión y multicloud con alta disponibilidad.
3. Almacenamiento de datos flexible y multimodelo
- Base de datos NoSQL basada en JSON: Almacena datos no estructurados y semiestructurados, lo que resulta esencial para las aplicaciones de IA que procesan diversos conjuntos de datos.
- Soporte para búsqueda vectorial: Ayuda a los desarrolladores a crear aplicaciones utilizando la búsqueda vectorial y se integra con Cadena LangChain y LlamaIndex.
4. Capacidades integradas de IA y análisis
- SQL para JSON (SQL++): Consultas tipo SQL con indexación, búsqueda de texto completo y análisis para la formación e inferencia de modelos de IA.
- Procesamiento de eventos y flujos: Activa Inteligencia Artificial en tiempo real mediante funciones integradas y una arquitectura basada en eventos.
- Integración con marcos AI/ML: Trabaja con TensorFlow, PyTorch y Apache Spark para el entrenamiento y despliegue de modelos de IA.
5. Despliegue multicloud y edge AI
- Entorno multicloud: Se ejecuta en Amazon Web Services (AWS), Microsoft Azure y Google Cloud, por lo que los desarrolladores pueden desarrollar e implantar aplicaciones de IA en la nube de su elección.
- Soporte de Edge Computing: Ideal para aplicaciones de IA en tiempo real en dispositivos móviles e IoT, reduciendo la dependencia de la nube y mejorando los tiempos de respuesta.
6. Seguridad y cumplimiento
- Seguridad de nivel empresarial: Proporciona cifrado integrado, control de acceso basado en funciones (RBAC) y cumplimiento de normativas como GDPR, HIPAA y SOC 2.
- Aislamiento y gobernanza de datos: Admite la supervisión del cumplimiento de la normativa y la detección del fraude basadas en IA.
7. 7. Rentabilidad
- Alto rendimiento a menor coste: Reduce los costes de infraestructura de la nube gestionando eficazmente los recursos y minimizando la transferencia de datos.
- Base de datos multimodal: Permite a los desarrolladores almacenar y consultar múltiples tipos de datos, reduciendo la necesidad de bases de datos adicionales y ahorrando en posibles costes de integración, licencias y gastos en la nube.
Los casos de uso específicos para aplicaciones de IA con Couchbase incluyen:
- Recomendaciones personalizadas: Comercio electrónico y servicios de streaming
- Detección de fraudes y análisis de riesgos: Banca y ciberseguridad
- Chatbots y IA agéntica: Atención al cliente y asistentes virtuales
- IoT y IA de borde: Dispositivos inteligentes y sistemas autónomos
Las empresas prefieren las bases de datos NoSQL por su flexibilidad, escalabilidad y alto rendimiento en el manejo de grandes volúmenes de datos diversos y crecientes. Además, las bases de datos NoSQL utilizan el escalado horizontal, distribuyendo los datos entre varios servidores para mantener el rendimiento a medida que crecen las cargas de trabajo. Estas capacidades las hacen muy adecuadas para aplicaciones de IA, sistemas IoT, servicios de campo adaptativos y gestión de caché y sesiones.
Las empresas de la lista Global 2000 están adoptando rápidamente las bases de datos NoSQL para impulsar sus aplicaciones de misión crítica:


"Descubrimos que la tecnología de replicación entre centros de datos para Couchbase era superior, especialmente para grandes cargas de trabajo".


"Con menos de la mitad de servidores, podemos aumentar el rendimiento y conseguir una arquitectura mucho más escalable".


"Couchbase es un almacén de datos distribuidos altamente escalable que desempeña un papel fundamental en nuestros sistemas de almacenamiento en caché".


"Los equipos de clase empresarial cuestan mucho dinero. Podemos escalar y tener alta disponibilidad con hardware básico".
Tutorial NoSQL
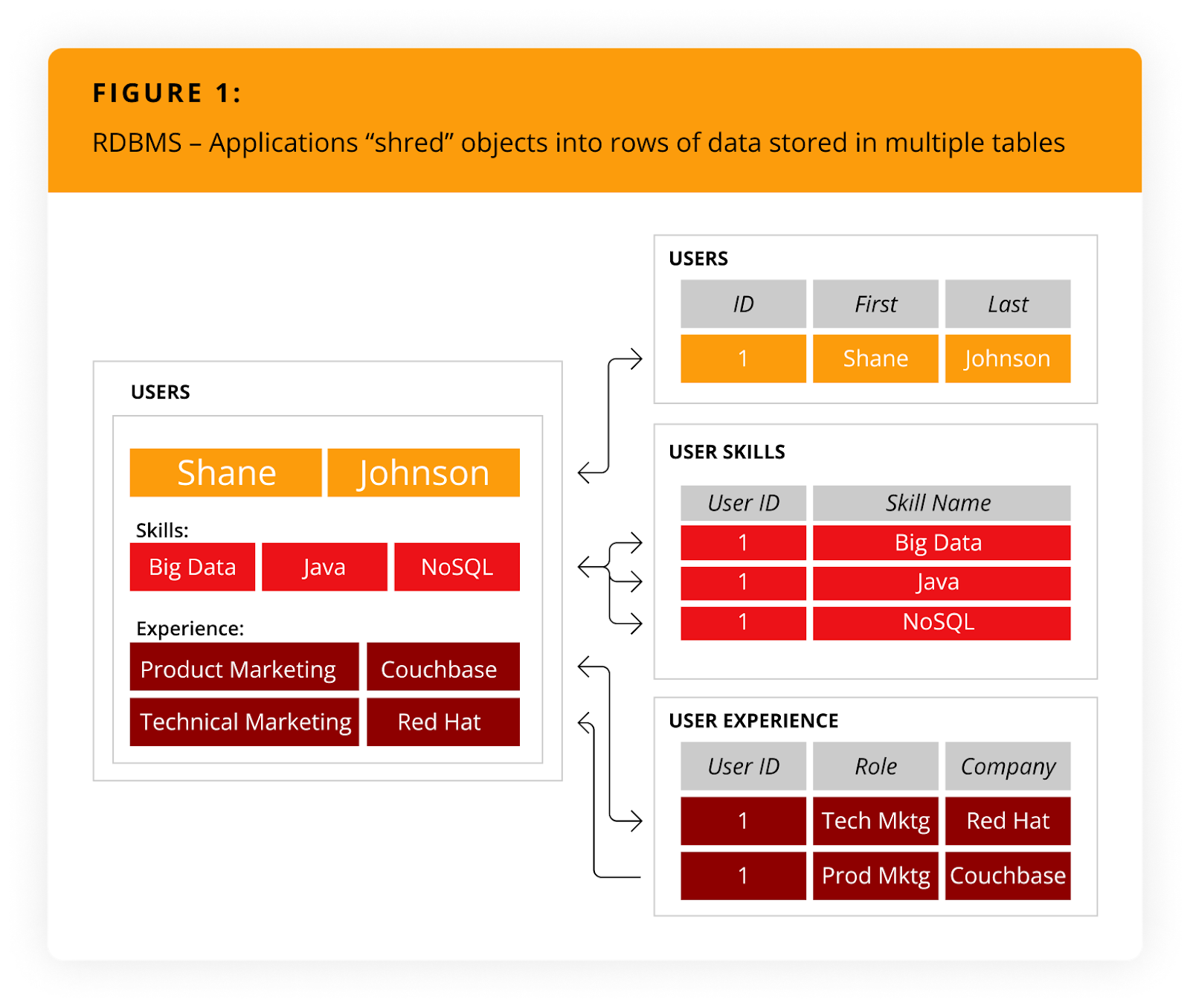
¿Cómo se compara NoSQL con las bases de datos relacionales? Veámoslo más de cerca. El siguiente tutorial ilustra una aplicación NoSQL utilizada para gestionar currículos. Interactúa con los currículos como un objeto (es decir, el objeto usuario), contiene una matriz para las habilidades y tiene una colección para los puestos. Alternativamente, escribir un currículum en una base de datos relacional requiere que la aplicación "triture" (normalice) el objeto usuario.
Almacenar este currículum requeriría que la aplicación insertara seis filas en tres tablas, como se ilustra en Figura 1.
Pulsa para ampliar
Y, para leer este perfil, la aplicación tendría que leer seis filas de tres tablas, como se ilustra en Figura 2.

Pulsa para ampliar
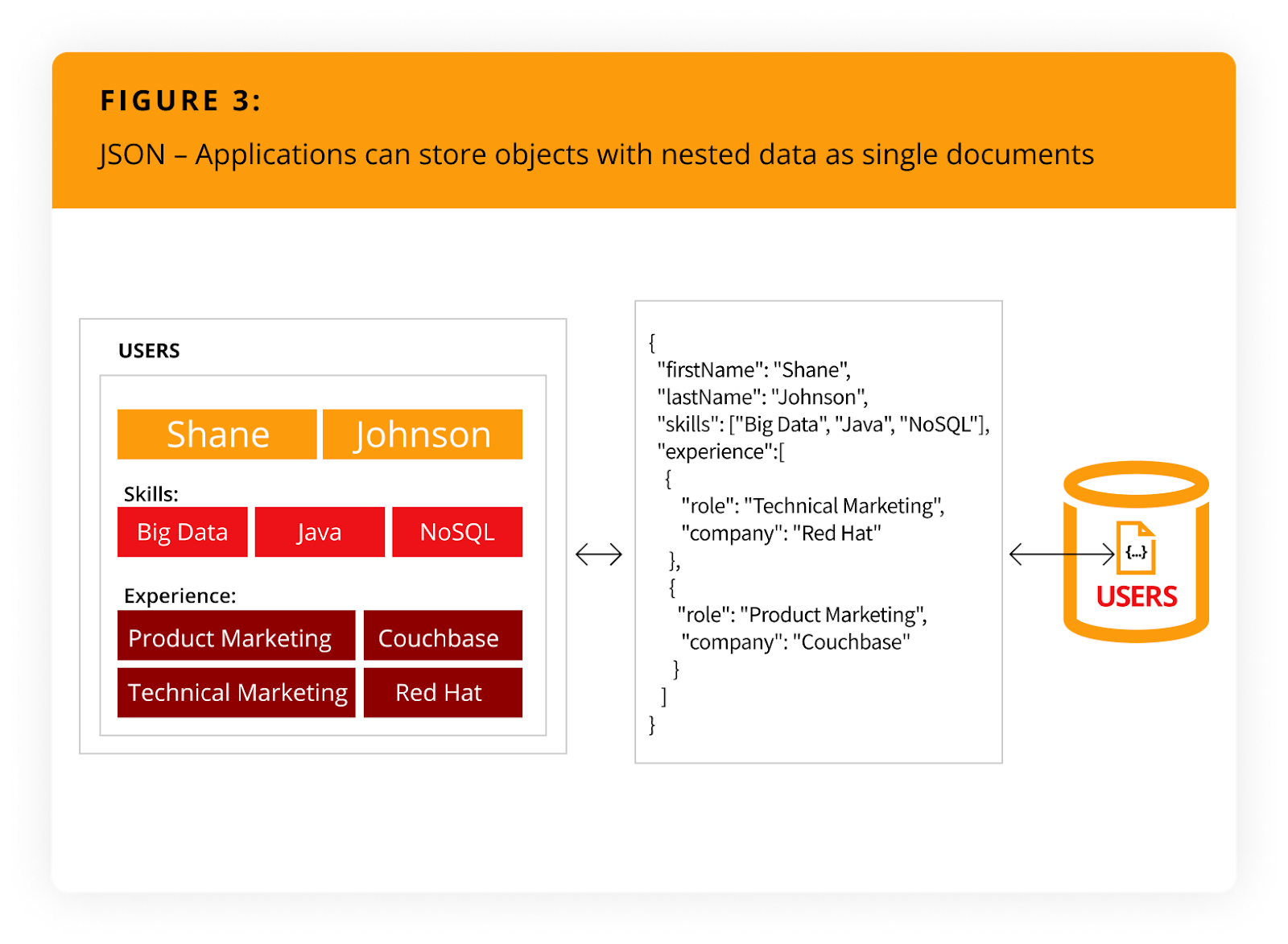
JSON no sólo elimina el desajuste de impedancia objeto-relacional, sino también la sobrecarga de los marcos de mapeo objeto-relacional (ORM). Simplifica el desarrollo de aplicaciones porque los objetos pueden leerse y escribirse sin normalizarlos (es decir, un único objeto puede leerse o escribirse como un único documento), como se ilustra en Figura 3.
Pulsa para ampliar
¿Qué pasa con las consultas y SQL?
Algunos pueden argumentar que la consulta de bases de datos NoSQL es más difícil, pero esto es un error común. La flexibilidad inherente a las bases de datos NoSQL orientadas a documentos les permite manejar datos estructurados y no estructurados igual de bien, y las nuevas herramientas permiten realizar consultas más rápido que nunca.
Couchbase admite SQLque permite a los desarrolladores aprovechar la potencia de SQL y la flexibilidad de JSON. No sólo admite las sentencias SELECT / FROM / WHERE estándar, sino también la agregación (GROUP BY), la ordenación (SORT BY), las uniones (LEFT OUTER / INNER) y la consulta de matrices y colecciones anidadas. Además, el rendimiento de las consultas puede mejorarse con índices compuestos, parciales y de cobertura.
SELECT RTRIM(p.FirstName) + ' ' + LTRIM(p.LastName) AS Name, d.City
FROM AdventureWorks2025.Person.Person AS p
INNER JOIN AdventureWorks2025.HumanResources.Employee e ON p.BusinessEntityID = e.BusinessEntityID
INNER JOIN
(SELECT bea.BusinessEntityID, a.City
FROM AdventureWorks2025.Person.Address AS a
INNER JOIN AdventureWorks2025.Person.BusinessEntityAddress AS bea
ON a.AddressID = bea.AddressID) AS d
ON p.BusinessEntityID = d.BusinessEntityID
ORDER BY p.LastName, p.FirstName;
SELECT RTRIM(p.FirstName) || ' ' || LTRIM(p.LastName) AS Name, d.City
FROM AdventureWorks2025.Person.Person AS p
INNER JOIN AdventureWorks2025.HumanResources.Employee e ON p.BusinessEntityID = e.BusinessEntityID
INNER JOIN
(SELECT bea.BusinessEntityID, a.City
FROM AdventureWorks2025.Person.Address AS a
INNER JOIN AdventureWorks2025.Person.BusinessEntityAddress AS bea
ON a.AddressID = bea.AddressID) AS d
ON p.BusinessEntityID = d.BusinessEntityID
ORDER BY p.LastName, p.FirstName;
Las bases de datos NoSQL almacenan los datos en documentos JSON flexibles, eliminando la necesidad de complejos mapeos objeto-relacionales (ORM) y facilitando la gestión de datos estructurados y no estructurados. Este enfoque simplifica el desarrollo de aplicaciones al almacenar y recuperar objetos como un único documento en lugar de dividirlos en múltiples tablas. Couchbase mejora aún más las capacidades de consulta con SQL++, que admite la conocida sintaxis SQL.
Por qué las bases de datos relacionales se quedan cortas
Los sistemas de gestión de bases de datos relacionales nacieron en la era de los mainframes y las aplicaciones empresariales, mucho antes de Internet, la nube, el big data, los móviles, la inteligencia artificial y las empresas interactivas masivas de hoy en día. Estas bases de datos se diseñaron para ejecutarse en un único servidor: cuanto más grande, mejor, y su diseño estaba pensado para optimizar el uso de los escasos recursos de almacenamiento, RAM y procesamiento. La única forma de aumentar la capacidad de estas bases de datos era actualizar los servidores (procesadores, memoria y almacenamiento). Con el paso de las décadas, la mayoría de las restricciones de su diseño original, como la normalización, la tipificación fuerte de los datos y la integridad referencial, se han suavizado o eliminado.
Los sistemas de gestión de bases de datos NoSQL surgieron debido al crecimiento exponencial de Internet y al auge de las aplicaciones web. Google lanzó el Documento de investigación Bigtable en 2006, y Amazon lanzó el Documento de investigación sobre la dinamo en 2007 - estos documentos detallan cómo las dos empresas diseñaron sus bases de datos para satisfacer las necesidades cambiantes de las empresas. En última instancia, las bases de datos modernas se centraban en desarrollar con agilidad, satisfacer las necesidades cambiantesy eliminar la transformación de datos.
Las bases de datos relacionales se diseñaron originalmente para entornos de un solo servidor con el fin de optimizar unos recursos limitados, pero a medida que crecían las necesidades de datos, se enfrentaban a problemas de escalabilidad. Impulsadas por el auge de Internet y las aplicaciones web, las bases de datos NoSQL surgieron para hacer frente a estas limitaciones, centrándose en la agilidad, la escalabilidad y la reducción de las complejidades de la transformación de datos.
Conclusión
Entonces, ¿para qué se utilizan las bases de datos NoSQL y por qué son importantes? A medida que las empresas se orientan hacia la inteligencia artificial, facilitada por la nube, los dispositivos móviles, las redes sociales, el aprendizaje automático y los Tecnologías GenAI - Los desarrolladores y los equipos de operaciones deben crear y mantener aplicaciones web, móviles y de IoT más rápido y a mayor escala. NoSQL, flexible y de alto rendimiento, es cada vez más la tecnología de bases de datos que eligen.
Miles de Empresa Global 2000 y millones de desarrolladores que trabajan en pequeñas empresas y startups han adoptado NoSQL. Para muchos, el uso de NoSQL comenzó con una caché, una prueba de concepto o una pequeña aplicación, y luego se expandió a aplicaciones de misión crítica específicas antes de convertirse en la base de todo el desarrollo de aplicaciones.
Con las bases de datos NoSQL, las empresas pueden desarrollar con mayor agilidad, operar a cualquier escala y ofrecer el rendimiento y la disponibilidad necesarios para satisfacer las demandas de las empresas de la economía digital.



Empezar a construir
Consulte nuestro portal para desarrolladores para explorar NoSQL, buscar recursos y empezar con tutoriales.
Utilizar Capella gratis
Ponte manos a la obra con Couchbase en unos pocos clics. Capella DBaaS es la forma más fácil y rápida de empezar.
Póngase en contacto
¿Quieres saber más sobre las ofertas de Couchbase? Permítanos ayudarle.