- Desenvolvedores
-
-
COMUNIDADE

Participe da comunidade de desenvolvedores
Explore recursos para desenvolvedores, embaixadores e eventos em sua área.
Saiba mais
-
-
Visão geral do banco de dados na memória
O que é um banco de dados na memória? Os IMDBs são sistemas de armazenamento de dados de alta velocidade que mantêm todos os dados na memória principal do computador (conhecida como memória de acesso aleatório ou RAM), o que agiliza a recuperação e o processamento dos dados. Essa tecnologia é ideal para aplicativos que exigem respostas em tempo real, como transações financeiras, sistemas de telecomunicações e jogos on-line. Entretanto, devido à natureza volátil da RAM, esses bancos de dados podem usar a replicação de dados para evitar a perda de dados. Embora o armazenamento de dados na memória possa ser mais caro em comparação com o armazenamento em disco tradicional, a disponibilidade cada vez maior de RAM a preços acessíveis e o valor da velocidade em muitos aplicativos modernos tornam os bancos de dados na memória uma ferramenta valiosa para muitos projetos.
- Como funciona um banco de dados na memória?
- Por que usar um banco de dados na memória?
- Vantagens e desvantagens dos bancos de dados na memória
- Comparação de bancos de dados na memória
- Banco de dados na memória do Couchbase
Como funciona um banco de dados na memória?
Um banco de dados na memória usa uma combinação de gerenciamento de armazenamento, manipulação de dados e mecanismos à prova de falhas, como a replicação, para oferecer maior velocidade de processamento de dados. Aqui está uma explicação simplificada das principais características:
- Armazenamento de dados: Ao contrário dos bancos de dados tradicionais, um IMDB armazena todos os seus dados na RAM do computador. Isso proporciona um acesso mais rápido do que a recuperação de dados de um disco rígido ou de um SSD.
- Processamento de dados: Com todos os dados disponíveis na memória, os IMDBs podem processar operações e executar consultas diretamente na memória. Isso reduz significativamente a latência, tornando os IMDBs excelentes para aplicativos que precisam de respostas em tempo real.
- Persistência de dados: Os IMDBs podem empregar várias estratégias de durabilidade de dados para atenuar a natureza volátil da RAM. As técnicas incluem manter um backup dos dados em disco ou o uso de replicação para duplicar os dados em vários nós.
Por que usar um banco de dados na memória?
Os bancos de dados na memória oferecem velocidade para acesso e processamento de dados, o que proporciona um aumento significativo no desempenho de seus aplicativos. Ao armazenar dados na memória principal do computador, os IMDBs podem permitir respostas mais rápidas e em tempo real.
Recursos do banco de dados na memória
Os bancos de dados na memória vêm com vários recursos distintos que os diferenciam dos bancos de dados tradicionais, mais pesados em disco:
- Velocidade: O recurso mais importante dos IMDBs é sua velocidade. Ao manter todos os dados na memória principal do sistema, os tempos de acesso e processamento de dados são drasticamente reduzidos, resultando em respostas de latência muito baixa.
- Processamento em tempo real: Devido às suas altas velocidades de processamento, os IMDBs são ideais para aplicativos que exigem respostas em tempo real ou quase em tempo real.
- Persistência de dados: Além de armazenar dados na memória, alguns IMDBs têm recursos para garantir a persistência e a recuperação dos dados. Esses recursos incluem gravações assíncronas em disco, snapshotting e backups baseados em disco.
- Compressão: Os IMDBs geralmente suportam a compactação de dados para reduzir o espaço de memória e otimizar o armazenamento.
- Escalabilidade: Os IMDBs podem ser ampliados (adicionando mais RAM) ou reduzidos (distribuídos em vários sistemas) para lidar com grandes volumes de dados.
Casos de uso e exemplos na memória
Os bancos de dados na memória são amplamente usados em vários setores e aplicativos devido aos seus recursos de processamento de dados em alta velocidade. Os casos de uso comuns incluem:
- Recomendação e personalização em tempo real: Um dos casos de uso mais proeminentes dos IMDBs é a análise em tempo real. As empresas de setores como finanças, varejo e telecomunicações usam IMDBs para analisar grandes fluxos de dados em tempo real. Por exemplo, as instituições financeiras podem usá-los para detecção de fraudes em tempo real, enquanto os varejistas os utilizam para personalização e recomendações em tempo real. Wells Fargopor exemplo, criou seu sistema de monitoramento de fraudes usando o banco de dados na memória do Couchbase. Seu sistema protege 100% de transações em tempo real a velocidades inferiores a 10 milissegundos por operação, ou 9.000 leituras e gravações por segundo.
- Armazenamento em cache: Os IMDBs são normalmente usados para armazenar dados em cache, com dados acessados com frequência armazenados na memória para recuperação rápida. Isso é especialmente útil para aplicativos da Web de alto tráfego, em que a entrega rápida de conteúdo é essencial para uma boa experiência do usuário. Por exemplo, LinkedIn fez a transição para o Couchbase como uma solução de cache para seu armazenamento de dados de fonte de verdade, e o Couchbase agora suporta mais de 50 casos de uso em toda a empresa.
- Armazenamento de sessão: Os IMDBs costumam ser usados para o gerenciamento de sessões em aplicativos da Web, onde armazenam dados como perfis de usuários ou informações de carrinhos de compras para permitir uma experiência de usuário rápida e perfeita. Cisco migrou para o Couchbase para obter baixa latência confiável e tempos de resposta consistentes, e agora usa o Couchbase para lidar com mais de 100 bilhões de sessões de usuários por ano.
- Telecomunicações: No setor de telecomunicações, os IMDBs lidam com roteamento de chamadas e gerenciamento de sessões, mantêm perfis de clientes e processam grandes volumes de registros de detalhes de chamadas em tempo real. Vodafone usa o Couchbase para gerenciar e personalizar milhões de comunicações em vários canais para mais de 17 milhões de clientes. O Couchbase oferece segurança de dados e escalabilidade para expansão sob demanda.
- Ferramentas de colaboração: Ferramentas de colaboração em tempo real, como Bublup use IMDBs para gerenciar e sincronizar simultaneamente as alterações em aplicativos móveis e da Web para vários usuários.
Quais são as vantagens e desvantagens dos bancos de dados na memória?
Os bancos de dados na memória apresentam um conjunto exclusivo de vantagens e desvantagens que podem afetar significativamente suas estratégias de gerenciamento de dados. Veja a seguir as principais vantagens e desvantagens a serem consideradas:
Vantagens
- Velocidade: Como os dados do IMDB são armazenados na RAM, eles podem ser acessados significativamente mais rápido do que os dados armazenados em disco. Isso proporciona respostas de consulta e tempos de transação mais rápidos, tornando os IMDBs uma ótima opção para aplicativos que exigem processamento de dados em tempo real.
- Escalabilidade: Os IMDBs podem ser dimensionados mais facilmente para gerenciar grandes volumes de dados. Eles podem fazer bom uso da quantidade crescente de memória disponível no hardware moderno.
- Confiabilidade: Apesar de os dados serem armazenados na memória, os IMDBs ainda podem oferecer durabilidade e confiabilidade dos dados. Técnicas como replicação, persistência e registro de transações ajudam a proteger contra a perda de dados.
Desvantagens
- Custo: A RAM é mais cara do que o armazenamento em disco, portanto, manter grandes quantidades de dados na memória pode ser caro, especialmente para bancos de dados muito grandes. Quando apenas uma fração de seus dados gerais precisa estar na RAM, um mecanismo de armazenamento como o Couchbase Magma pode fornecer acesso rápido a grandes quantidades de dados armazenados em disco.
- Volatilidade: A RAM é volátil, o que significa que, se houver falta de energia, os dados também serão. Entretanto, a maioria dos IMDBs tem mecanismos para manter os dados em disco ou replicá-los na rede para evitar a perda de dados. O Couchbase oferece aos clientes várias opções de replicação e persistência.
- Limitações de hardware: Embora os tamanhos de memória estejam aumentando, ainda há um limite finito para a quantidade que um sistema individual pode ter. Você pode superar facilmente os limites de um único sistema usando dimensionamento horizontal como o fornecido pelo Couchbase Capella™ DBaaS.
Comparação de bancos de dados na memória
| Banco de dados na memória | Banco de dados que prioriza a memória | Banco de dados baseado em disco | |
|---|---|---|---|
| Desempenho | Geralmente mais rápido devido ao acesso direto à memória que reduz a latência de E/S do disco. | Mais rápido do que o baseado em disco, mas pode não ser tão rápido quanto o puro na memória devido à possível latência de E/S do disco. | Normalmente, mais lento devido à latência de E/S do disco. |
| Custo | Tende a ser mais caro devido ao alto custo da RAM. (Geralmente, a RAM é apenas uma parte do custo total). | Custo médio. Você pode aumentar a RAM com armazenamento em disco mais barato. | Geralmente menos dispendioso devido à dependência do armazenamento em disco. |
| Persistência de dados | Frequentemente volátil. Os dados podem ser perdidos em caso de reinicialização ou falha se os recursos de durabilidade não forem usados. | Oferece persistência, o que reduz o risco de perda de dados, apesar da dependência primária da memória. | Altamente persistente. Os dados são armazenados mesmo que o sistema seja desligado. |
| Escalabilidade | Limitado pela RAM disponível, a menos que seja possível o escalonamento horizontal. | Maior escalabilidade, pois pode usar o armazenamento em disco para conjuntos de dados maiores. | Pode armazenar dados em discos grandes, mas pode não ser capaz de acompanhar as demandas de E/S. |
| Padrões de acesso a dados | Melhor para cargas de trabalho com altas taxas de operação e baixa latência. A maioria é otimizada para armazenamento de dados transitórios. | Bom para cargas de trabalho com uma combinação de operações de leitura e gravação. Requisitos de latência baixos a moderados. | Melhor para cargas de trabalho analíticas, de armazenamento de longo prazo e de gravação pesada, ou se o desempenho for pouco preocupante. |
| Casos de uso | Análise em tempo real, cache, armazenamento de sessão ou qualquer coisa transitória. | Finalidade geral, incluindo aplicativos em tempo real e quase em tempo real, armazenamento em cache e cargas de trabalho mistas. | Armazenamento de dados em grande escala e aplicativos com requisitos que não mudam com frequência. |
| Exemplos |
|
CouchStore ou Magma (Disponível no Couchbase Capella e no Couchbase Server). | Implantações típicas de SQL Server, Oracle, Postgres, MySQL, etc. (Eles podem usar memória para armazenar em buffer e armazenar em cache os planos de consulta, e alguns podem ter complementos para aumentar o armazenamento em cache). Compare com o NoSQL. |
Banco de dados na memória do Couchbase
As tecnologias de cache distribuídas, altamente disponíveis e na memória do Couchbase fornecem respostas de alta velocidade mesmo em grandes volumes. O mais novo desenvolvimento na memória no ecossistema do Couchbase é a introdução do suporte a buckets somente de memória no banco de dados como serviço (DBaaS) do Couchbase Capella. A Capella sempre apoiou o armazenamento em cache com armazenamento em memória de alta velocidade, persistindo simultaneamente os dados de volta ao disco para evitar a perda de dados. (Esse método ainda é o padrão.) A introdução de buckets somente de memória permite que os clientes optem por armazenar os dados somente como cache, sem gravá-los em disco.
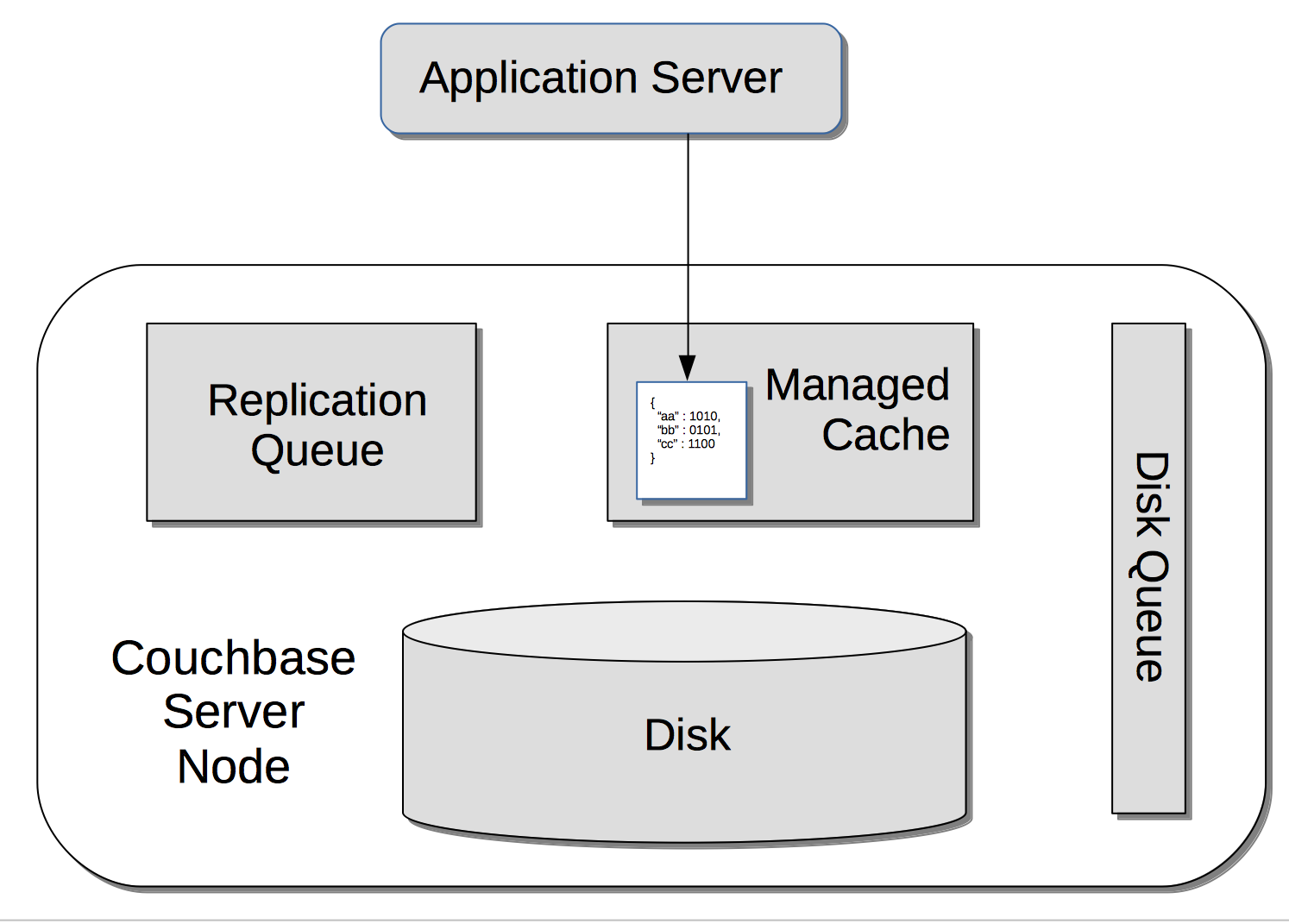
CouchStore arquitetura memory-first: A opção somente de memória dispensa as partes de disco e de fila de disco da arquitetura para aumentar o desempenho.
O recurso somente de memória do Capella é uma adição útil para aplicativos que exigem armazenamento em cache. Dados transitórios ou efêmeros, que talvez não precisem persistir permanentemente no disco, agora podem ser gerenciados com mais eficiência. Esse recurso pode aumentar o desempenho do aplicativo ao reduzir as viagens de dados para o disco, enquanto a flexibilidade no gerenciamento de dados pode reduzir os custos de disco.
Os dados somente em memória são altamente benéficos em cenários de alto tráfego, nos quais os dados pré-carregados no cache podem atender rapidamente aos picos de uso. Exemplos de casos de uso de bancos de dados na memória incluem:
- Gerenciamento de sessões para aplicativos da Web
- Melhoria do desempenho por meio de mecanismos de cache
- Gerenciamento de informações anônimas
- Aumentar a segurança e a privacidade, limitando a exposição a dados confidenciais
Com o Capella, os usuários podem definir um bucket como somente de memória durante sua criação. Em um único banco de dados, os compartimentos "somente memória" e "memória e disco" podem ser usados lado a lado para diferentes casos de uso. Esse recurso torna o Capella um escolha preparada para o futuro para as necessidades de cache, pois pode ser facilmente expandido para abranger casos de uso mais avançados à medida que surgirem.
Iniciar a construção
Confira nosso portal do desenvolvedor para explorar o NoSQL, procurar recursos e começar a usar os tutoriais.
Experimente Capella gratuitamente
Comece a trabalhar com o Couchbase em apenas alguns cliques. O Capella DBaaS é a maneira mais fácil e rápida de começar.
Couchbase para ISVs
Crie aplicativos avançados com menos complexidade e custo.