- Desenvolvedores
-
-
COMUNIDADE

Participe da comunidade de desenvolvedores
Explore recursos para desenvolvedores, embaixadores e eventos em sua área.
Saiba mais
-
-
Visão geral: Estrutura NoSQL e conceitos-chave
Para entender melhor como funcionam os bancos de dados NoSQL, esta página aborda:
O que é um banco de dados NoSQL?
Um banco de dados NoSQL, abreviação de "não apenas SQL (Structured Query Language)", é um banco de dados não relacional projetado para lidar com estruturas de dados diversas e flexíveis. A definição de NoSQL refere-se a bancos de dados que suportam vários modelos - incluindo armazenamentos de documentos, gráficos, valores-chave, colunas amplas e vetores - oferecendo maior escalabilidade e adaptabilidade em comparação com os bancos de dados SQL tradicionais, que dependem de tabelas estruturadas e esquemas fixos.
O significado de NoSQL evoluiu com os avanços em CPUs, RAM, computação em nuvem e interações de IA, permitindo que os bancos de dados modernos gerenciem com eficiência conjuntos de dados grandes e em tempo real. Ao priorizar dimensionamento horizontal e desempenho, os bancos de dados NoSQL garantem a distribuição contínua de dados em vários nós, o que os torna a escolha preferida para IA, big data e análise em tempo real, em que os bancos de dados tradicionais muitas vezes têm dificuldade para acompanhar.
NoSQL refere-se a bancos de dados que armazenam dados em formatos flexíveis usando modelos como documentos, armazenamentos de valores-chave e armazenamentos vetoriais. Sua escalabilidade e desempenho os tornam ideais para aplicativos modernos que exigem acesso em tempo real e lidam com grandes cargas de trabalho dinâmicas.
Qual é a diferença entre SQL e NoSQL?
Bancos de dados SQL e NoSQL diferem na forma como armazenam e consultam dados. Os bancos de dados SQL dependem de tabelas com colunas e linhas para recuperar e gravar dados estruturados, enquanto os bancos de dados NoSQL usam modelos de dados flexíveis mais adequados para dados não estruturados e semiestruturados.
SQLO banco de dados SQL, introduzido pela primeira vez na década de 1970, agora é usado por desenvolvedores e analistas de dados em todo o mundo para localizar e gerar relatórios sobre dados armazenados em sistemas relacionais. Os bancos de dados SQL são ideais para aplicativos que exigem integridade de dados e usam relações estruturadas e consultas padronizadas (por exemplo, software de planejamento de recursos empresariais). Embora NoSQL existe desde a década de 1960, o termo foi cunhado pela primeira vez no início dos anos 2000, quando se tornou crucial para os desenvolvedores o uso de bancos de dados capazes de armazenar e recuperar dados para aplicativos em tempo real.
Vale a pena observar que o SQL vem se expandindo para dar suporte aos padrões de acesso NoSQL. Por exemplo, muitos bancos de dados relacionais agora suportam JSON (JavaScript Object Notation) como um tipo de dados. Alguns bancos de dados até estenderam o SQL para consultar diretamente as estruturas JSON, incluindo o Couchbase, que suporta SQL++ (SQL para JSON).
A diferença entre os bancos de dados SQL e NoSQL está em sua estrutura e casos de uso. Os bancos de dados SQL usam tabelas, o que os torna ideais para aplicativos que exigem uma estrutura rígida e dados normalizados. Por outro lado, os bancos de dados NoSQL usam modelos flexíveis, o que os torna mais adequados para lidar com dados não estruturados e semiestruturados, permitindo o acesso em tempo real.
Tipos de bancos de dados NoSQL
Esses são os tipos mais populares de padrões de acesso a bancos de dados NoSQL:
- Armazenamento de valores-chave agrupam dados associados em tabelas independentes em que os registros são identificados por chaves exclusivas para facilitar a recuperação. Eles têm estrutura suficiente para espelhar o valor dos bancos de dados relacionais e, ao mesmo tempo, acrescentam os benefícios de desempenho e acessibilidade de uma estrutura de acesso a dados NoSQL. Os dados de valor-chave são facilmente armazenados em um cache em que os dados acessados com frequência são mantidos na memória para leituras rápidas. As gravações, atualizações e novas solicitações de leitura são roteadas programaticamente para o armazenamento persistente. Os armazenamentos de valores-chave priorizam as velocidades de acesso atômico acima da consistência, do isolamento e da durabilidade.
- Bancos de dados de documentos armazenam principalmente informações como documentos lógicos, inclusive documentos JSON. Por exemplo, esses sistemas também podem armazenar documentos XML ou objetos binários. Devido à natureza flexível do formato e ao grau de controle que ele oferece aos desenvolvedores, os bancos de dados de documentos são os preferidos na criação de aplicativos orientados por dados.
- Bancos de dados de colunas largas e colunares armazenar dados por colunas em vez de linhasque otimiza o desempenho da consulta para cargas de trabalho analíticas e processamento de dados em grande escala. Assim como os armazenamentos de valores-chave, os bancos de dados de colunas largas têm alguma estrutura NoSQL básica e preservam a flexibilidade, o manuseio de dados e as capacidades de agregação.
- Pesquisar bancos de dados permitem que os usuários consultem dados semiestruturados e não estruturados, como páginas da Web, documentos, mapas, JSON e documentos XML. Eles usam índices invertidos especializados para localizar palavras-chave em corpos de texto para encontrar dados relevantes, semelhante a "pesquisar" algo on-line no Google.
- Bancos de dados gráficos usam estruturas gráficas como nós, bordas e propriedades para definir as relações entre os elementos de dados armazenados. Os bancos de dados de gráficos são úteis para identificar padrões de relacionamento em não estruturado e semiestruturado informações, criando redes sociais, montagens de peças, estruturas organizacionais e ontologias. Os bancos de dados de gráficos são muito usados em mecanismos de recomendação, reconhecimento de padrões de fraude, funções de IA preditivas e vinculação de redes sociais.
- Bancos de dados de séries temporais permitem que os usuários acompanhem as alterações de dados ao longo do tempo e detectem anomalias em gráficos de preços de ações, registros de máquinas, monitores de saúde e sistemas de alerta. Como os dados de séries temporais mudam rapidamente, esses bancos de dados geram grandes quantidades de informações, o que pode causar problemas de dimensionamento.
- Bancos de dados vetoriais ajudam a melhorar a precisão dos modelos de IA generativa, fornecendo dicas (vetores) que ajudá-los a encontrar as respostas "corretas" em seus dados de treinamento. Os bancos de dados vetoriais operam dentro dos processos de geração aumentada por recuperação (RAG) para armazenar incorporação de vetores que ajudam a reduzir as alucinações da IA generativa e a manter o progresso do modelo.
Os padrões populares de acesso a dados NoSQL incluem armazenamentos de valores-chave, bancos de dados de documentos, bancos de dados de colunas e colunas amplas, bancos de dados de pesquisa, bancos de dados de gráficos, bancos de dados de séries temporais e bancos de dados vetoriais. Cada um desses tipos de NoSQL tem características exclusivas, como escalabilidade, flexibilidade de esquema e eficiência de consulta. Você deve explorá-los em profundidade para decidir qual banco de dados NoSQL usar.
Por que usar o NoSQL?
As empresas preferem os bancos de dados NoSQL por sua capacidade de lidar com grandes volumes de dados diversos e crescentes. As vantagens específicas dos bancos de dados NoSQL incluem:
- Escalabilidade: Os bancos de dados NoSQL são dimensionados horizontalmente por meio da distribuição de dados em vários servidores, o que os torna ideais para grandes cargas de trabalho.
- Flexibilidade: Diferentemente dos bancos de dados relacionais, o NoSQL permite o armazenamento de dados sem esquema, facilitando o armazenamento e o gerenciamento de dados não estruturados ou semiestruturados.
- Alto desempenho: Otimizados para leituras e gravações rápidas, os bancos de dados NoSQL reduzem a complexidade das consultas e melhoram os tempos de resposta dos aplicativos em tempo real.
- Vários modelos de dados: Os bancos de dados NoSQL favorecem os modelos de dados de valor-chave, documento, coluna ampla, pesquisa e série temporal, o que os torna ideais para vários casos de uso.
- Big data e processamento em tempo real: O NoSQL foi projetado para lidar com grandes quantidades de dados, o que o torna ideal para análise de big dataIoT, cache e gerenciamento de sessão.
- Computação distribuída e em nuvem: Os bancos de dados NoSQL funcionam bem em ambientes de nuvem, garantindo alta disponibilidade e tolerância a falhas em sistemas distribuídos.
- Desenvolvimento e iteração mais fáceis: Com o NoSQL, os desenvolvedores podem aproveitar as habilidades existentes em SQL e usar um banco de dados que se integra a ferramentas conhecidas, ambientes de desenvolvimento integrado (IDEs)e estruturas.
O banco de dados NoSQL multiuso do Couchbase é especialmente adequado para aplicativos de IA porque oferece:
1. Alto desempenho e baixa latência
- Arquitetura que prioriza a memória: Usa um design distribuído que prioriza a memória para leituras e gravações rápidas, reduzindo a latência de inferência do modelo de IA.
- Tempos de resposta inferiores a milissegundos: Garante o acesso aos dados em tempo real, o que é crucial para casos de uso como mecanismos de recomendaçãodetecção de fraudes e análise preditiva.
2. Escalabilidade e arquitetura distribuída
- Dimensionamento multidimensional: Pode ser dimensionado horizontal ou verticalmente para lidar com conjuntos de dados de IA maciços e cargas de trabalho crescentes.
- Replicação entre data centers (XDCR): Oferece suporte a implementações de IA em várias regiões e nuvens com alta disponibilidade.
3. Armazenamento de dados flexível e com vários modelos
- Banco de dados NoSQL baseado em JSON: Armazena dados não estruturados e semiestruturados, o que é essencial para aplicativos de IA que processam diversos conjuntos de dados.
- Suporte para pesquisa vetorial: Ajuda os desenvolvedores a criar aplicativos usando a pesquisa vetorial e se integra com LangChain e LlamaIndex.
4. Recursos integrados de IA e análise
- SQL para JSON (SQL++): Consulta semelhante a SQL com indexação, pesquisa de texto completo e análise para treinamento e inferência de modelos de IA.
- Processamento de eventos e fluxos: Permite insights de IA em tempo real usando funções incorporadas e arquitetura orientada por eventos.
- Integração com estruturas de IA/ML: Trabalha com TensorFlow, PyTorch e Apache Spark para treinamento e implantação de modelos de IA.
5. Implementação de IA de borda e multinuvem
- Ambiente multicloud: É executado no Amazon Web Services (AWS), no Microsoft Azure e no Google Cloud, para que os desenvolvedores possam desenvolver e implementar aplicativos de IA na nuvem de sua escolha.
- Suporte à computação de borda: Ideal para aplicativos de IA em tempo real em dispositivos móveis e de IoT, reduzindo a dependência da nuvem e melhorando os tempos de resposta.
6. Segurança e conformidade
- Segurança de nível empresarial: Oferece criptografia integrada, controle de acesso baseado em função (RBAC) e conformidade com normas como GDPR, HIPAA e SOC 2.
- Isolamento e governança de dados: Oferece suporte ao monitoramento de conformidade orientado por IA e à detecção de fraudes.
7. Eficiência de custos
- Alto desempenho a um custo menor: Reduz os custos da infraestrutura de nuvem gerenciando recursos com eficiência e minimizando a transferência de dados.
- Banco de dados multimodal: Permite que os desenvolvedores armazenem e consultem vários tipos de dados, reduzindo a necessidade de bancos de dados adicionais e economizando em possíveis custos de integração, taxas de licenciamento e gastos com a nuvem.
Os casos de uso específicos para aplicativos de IA com o Couchbase incluem:
- Recomendações personalizadas: Comércio eletrônico e serviços de streaming
- Detecção de fraudes e análise de riscos: Bancos e segurança cibernética
- Chatbots e IA agêntica: Suporte ao cliente e assistentes virtuais
- IoT e IA de ponta: Dispositivos inteligentes e sistemas autônomos
As empresas preferem os bancos de dados NoSQL por sua flexibilidade, escalabilidade e alto desempenho no tratamento de grandes volumes de dados diversos e crescentes. Além disso, os bancos de dados NoSQL usam dimensionamento horizontal, distribuindo dados em vários servidores para manter o desempenho à medida que as cargas de trabalho aumentam. Esses recursos os tornam adequados para aplicativos de IA, sistemas de IoT, serviços de campo adaptáveis e gerenciamento de cache e de sessão.
As empresas do Global 2000 estão adotando rapidamente os bancos de dados NoSQL para alimentar seus aplicativos de missão crítica:


"Descobrimos que a tecnologia de replicação entre data centers para o Couchbase era superior, especialmente para grandes cargas de trabalho."


"Com menos da metade dos servidores, podemos aumentar o desempenho e obter uma arquitetura escalável muito melhor."


"O Couchbase é um armazenamento de dados distribuído altamente escalável que desempenha um papel fundamental em nossos sistemas de cache."


"Caixas de classe empresarial custam muito dinheiro. Podemos escalonar e ter alta disponibilidade com hardware de commodity."
Tutorial de NoSQL
Como o NoSQL se compara aos bancos de dados relacionais? Vamos dar uma olhada mais de perto. O tutorial a seguir ilustra um aplicativo NoSQL usado para gerenciar currículos. Ele interage com currículos como um objeto (ou seja, o objeto do usuário), contém uma matriz para habilidades e tem uma coleção para cargos. Como alternativa, a gravação de um currículo em um banco de dados relacional exige que o aplicativo "destrua" (normalize) o objeto do usuário.
O armazenamento desse currículo exigiria que o aplicativo inserisse seis linhas em três tabelas, conforme ilustrado em Figura 1.
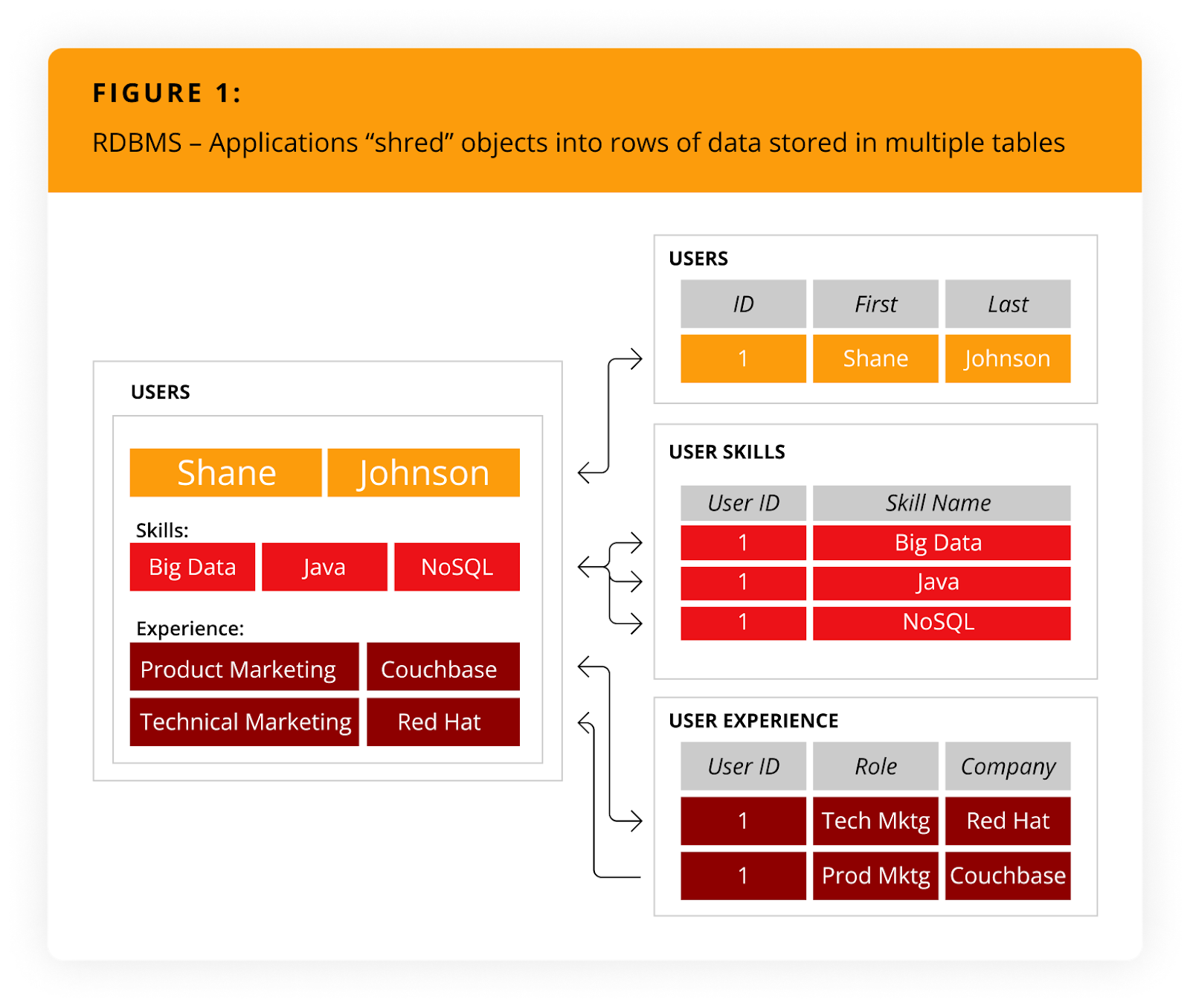
Clique para expandir
Além disso, a leitura desse perfil exigiria que o aplicativo lesse seis linhas de três tabelas, conforme ilustrado em Figura 2.

Clique para expandir
O JSON não só elimina a incompatibilidade de impedância objeto-relacional, mas também a sobrecarga das estruturas de mapeamento objeto-relacional (ORM). Ele simplifica o desenvolvimento de aplicativos porque os objetos podem ser lidos e gravados sem normalizá-los (ou seja, um único objeto pode ser lido ou gravado como um único documento), conforme ilustrado em Figura 3.
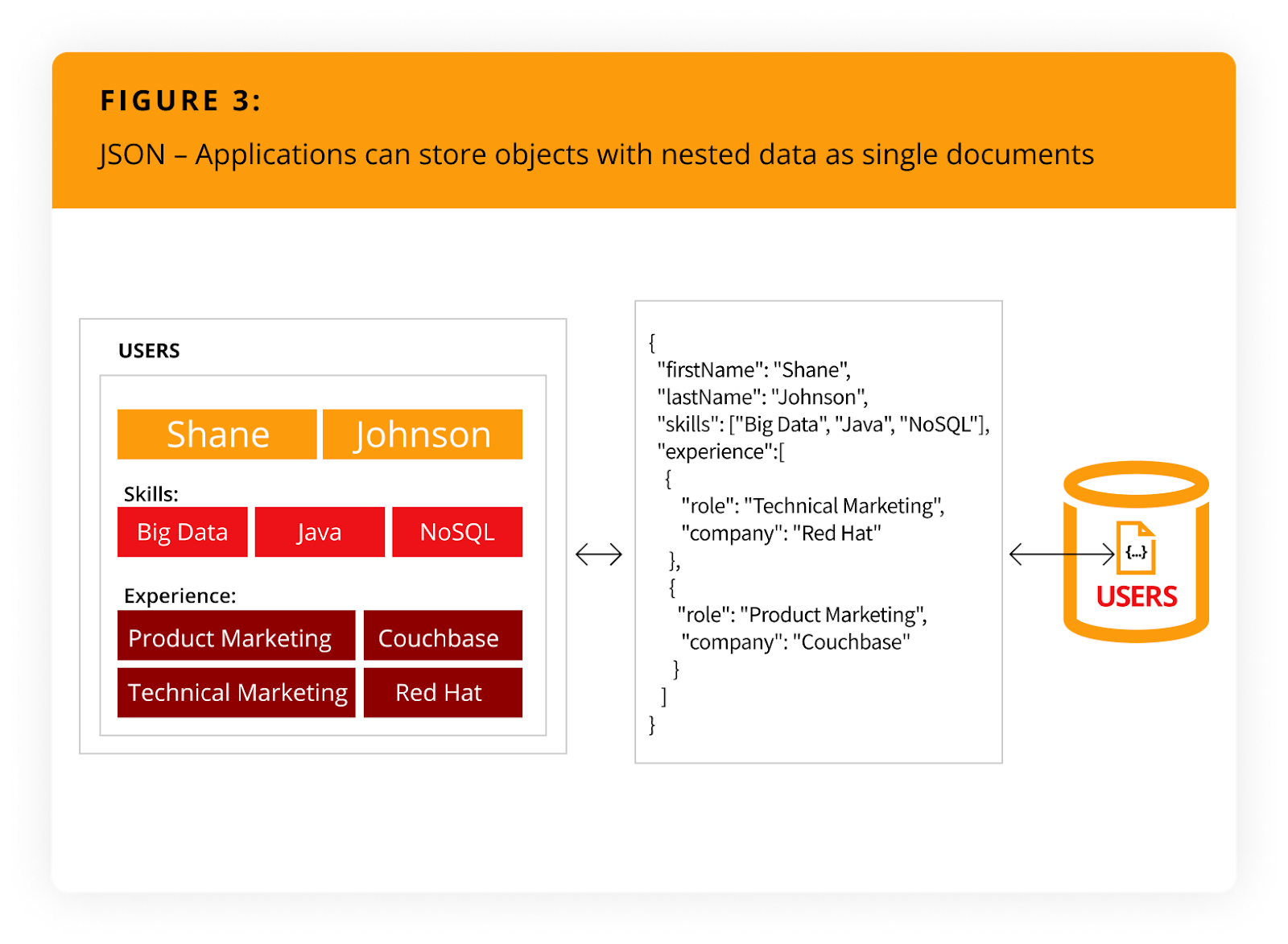
Clique para expandir
E quanto a consultas e SQL?
Alguns podem argumentar que a consulta a bancos de dados NoSQL é mais difícil, mas esse é um equívoco comum. A flexibilidade inerente dos bancos de dados NoSQL orientados a documentos permite que eles lidem igualmente bem com dados estruturados e não estruturados, e as novas ferramentas permitem consultas mais rápidas do que nunca.
O Couchbase suporta SQL++que permite que os desenvolvedores aproveitem o poder do SQL e a flexibilidade do JSON. Ele não apenas oferece suporte a instruções SELECT / FROM / WHERE padrão, mas também a agregação (GROUP BY), classificação (SORT BY), junções (LEFT OUTER / INNER) e consulta a matrizes e coleções aninhadas. Além disso, o desempenho da consulta pode ser aprimorado com índices compostos, parciais e de cobertura.
SELECT RTRIM(p.FirstName) + ' ' + LTRIM(p.LastName) AS Name, d.City
FROM AdventureWorks2025.Person.Person AS p
INNER JOIN AdventureWorks2025.HumanResources.Employee e ON p.BusinessEntityID = e.BusinessEntityID
INNER JOIN
(SELECT bea.BusinessEntityID, a.City
FROM AdventureWorks2025.Person.Address AS a
INNER JOIN AdventureWorks2025.Person.BusinessEntityAddress AS bea
ON a.AddressID = bea.AddressID) AS d
ON p.BusinessEntityID = d.BusinessEntityID
ORDER BY p.LastName, p.FirstName;
SELECT RTRIM(p.FirstName) || ' ' || LTRIM(p.LastName) AS Name, d.City
FROM AdventureWorks2025.Person.Person AS p
INNER JOIN AdventureWorks2025.HumanResources.Employee e ON p.BusinessEntityID = e.BusinessEntityID
INNER JOIN
(SELECT bea.BusinessEntityID, a.City
FROM AdventureWorks2025.Person.Address AS a
INNER JOIN AdventureWorks2025.Person.BusinessEntityAddress AS bea
ON a.AddressID = bea.AddressID) AS d
ON p.BusinessEntityID = d.BusinessEntityID
ORDER BY p.LastName, p.FirstName;
Os bancos de dados NoSQL armazenam dados em documentos JSON flexíveis, eliminando a necessidade de mapeamento objeto-relacional (ORM) complexo e facilitando o gerenciamento de dados estruturados e não estruturados. Essa abordagem simplifica o desenvolvimento de aplicativos ao armazenar e recuperar objetos como um único documento, em vez de dividi-los em várias tabelas. O Couchbase aprimora ainda mais os recursos de consulta com o SQL++, que suporta a sintaxe SQL familiar.
Por que os bancos de dados relacionais são insuficientes
Os sistemas de gerenciamento de bancos de dados relacionais nasceram na era dos mainframes e dos aplicativos de negócios - muito antes da Internet, da nuvem, do big data, dos dispositivos móveis, da inteligência artificial e das empresas interativas em massa de hoje. Esses bancos de dados foram projetados para serem executados em um único servidor - quanto maior, melhor, e seu design foi concebido para otimizar o uso de recursos escassos de armazenamento, RAM e processamento. A única maneira de aumentar a capacidade desses bancos de dados era atualizar os servidores (processadores, memória e armazenamento) para aumentar a escala. Com o passar das décadas, a maioria das restrições de seu projeto original, incluindo normalização, tipagem forte de dados e integridade referencial, foi atenuada ou eliminada.
Os sistemas de gerenciamento de banco de dados NoSQL surgiram devido ao crescimento exponencial da Internet e ao aumento dos aplicativos da Web. O Google lançou o Trabalho de pesquisa de grande porte em 2006, e a Amazon lançou o Trabalho de pesquisa sobre o Dynamo em 2007 - esses documentos detalhavam como as duas empresas projetaram seus bancos de dados para atender às necessidades em evolução das empresas. Em última análise, os bancos de dados modernos se concentraram em desenvolvimento com agilidade, atender aos requisitos em constante mudançae eliminação da transformação de dados.
Os bancos de dados relacionais foram originalmente projetados para ambientes de servidor único para otimizar recursos limitados, mas à medida que as necessidades de dados aumentavam, eles enfrentavam desafios de escalabilidade. Impulsionados pela ascensão da Internet e dos aplicativos da Web, os bancos de dados NoSQL surgiram para lidar com essas limitações, concentrando-se na agilidade, na escalabilidade e na redução das complexidades de transformação de dados.
Conclusão
Então, para que são usados os bancos de dados NoSQL e por que eles são importantes? À medida que as empresas mudam para a inteligência artificial - possibilitada por nuvem, dispositivos móveis, mídia social, aprendizado de máquina e Tecnologias GenAI - Os desenvolvedores e as equipes de operações precisam criar e manter aplicativos da Web, móveis e de IoT com mais rapidez e em maior escala. O NoSQL flexível e de alto desempenho é cada vez mais a tecnologia de banco de dados que eles escolhem.
Milhares de Empresa Global 2000 desenvolvedores e milhões de desenvolvedores que trabalham em empresas menores e startups adotaram o NoSQL. Para muitos, o uso do NoSQL começou com um cache, uma prova de conceito ou um aplicativo pequeno e, em seguida, expandiu-se para aplicativos de missão crítica direcionados antes de se tornar a base para todo o desenvolvimento de aplicativos.
Com os bancos de dados NoSQL, as empresas podem se desenvolver com maior agilidade, operar em qualquer escala e oferecer o desempenho e a disponibilidade necessários para atender às demandas dos negócios da economia digital.



Iniciar a construção
Confira nosso portal do desenvolvedor para explorar o NoSQL, procurar recursos e começar a usar os tutoriais.
Use o Capella gratuitamente
Comece a trabalhar com o Couchbase em apenas alguns cliques. O Capella DBaaS é a maneira mais fácil e rápida de começar.
Entre em contato
Deseja saber mais sobre as ofertas do Couchbase? Deixe-nos ajudar.