Every machine learning use case has different performance needs, and when it comes to ML-powered enterprise prediction serving systems, it’s no different.
A machine learning (ML) model takes an input (e.g., an image) and makes a prediction about it (e.g., what object is in the image). Once a ML model is trained on historical data (e.g., a set of old images), it’s deployed inside a prediction serving system to make predictions on new data.
An enterprise might build their own prediction serving system or use a system from a cloud provider. In either case, the prediction serving system needs storage for the predictions, the model metadata, and the input or features that are passed to the models.
This article describes different architectures to serve real-time prediction machine learning in production and how the Couchbase Data Platform satisfies various storage needs of an enterprise prediction serving system.
Terminology
Before we dive into the details, let’s take a look at some of the terminology used in this article.
-
- Prediction Serving System: A system that takes a trained machine learning model and new data as input and returns a prediction as output.
- Trained Model: A statistical data structure containing the weights and biases obtained from the training process.
- Features: Attributes of the data that are relevant for the prediction process.
When making a real-time prediction, for example, consider a simple linear regression problem such as: y = b1 x1 + b2 x2 … + bn xn …
-
- The features are x1, x2, …
- The trained model is a data structure containing values for b1, b2, …. These values were learned using the training process.
- The prediction serving system takes the features and model as input and returns prediction y as output.
Performance Requirements of a Real-Time Prediction Serving System
Different real-time prediction machine learning use cases have different performance needs.
With real-time predictions, for example, an interactive web application may require predictions to be delivered within tens of milliseconds, whereas a gaming application may need sub-millisecond prediction latency. The prediction system may need to serve a high volume of requests and scale to handle dynamic workloads.
Different types of databases handle these different performance needs. A leading cloud provider recommends three different NoSQL databases for use with their prediction system. Multiple such database products are combined to handle a single use case. This results in a complex architecture for the prediction serving system.
In this article, you’ll see how Couchbase replaces multiple data stores used in a prediction serving system. This reduces complexity, operational overhead, and total cost of ownership (TCO). With Couchbase, your operational, analytics, and AI/ML workload all co-exist on the same data platform.
Couchbase Server’s memory-first architecture, with integrated document cache, delivers sustained high throughput and consistent sub-millisecond latency, outperforming other NoSQL products such as MongoDB and DataStax Cassandra. (Refer to Couchbase Benchmarks and Couchbase High Performance Cache for more information).
The performance of a prediction serving system depends on its architecture and the performance of its components. In turn, a given system’s architecture depends on the use case. Let’s take a closer look at some of the most common prediction serving use cases.
Use Case #1: Real-Time Predictions with Raw Data Stored on Couchbase
Let’s use customer churn score real-time prediction as an example.
A fictional company called ACME wants to identify customers who are likely to stop using its products. The company trains a churn prediction model on historical customer data and deploys it in production to churn scores for new customers in real time using prediction machine learning.
One simple way for ACME to set up a prediction serving system is shown in the use case diagram Figure 1 below.
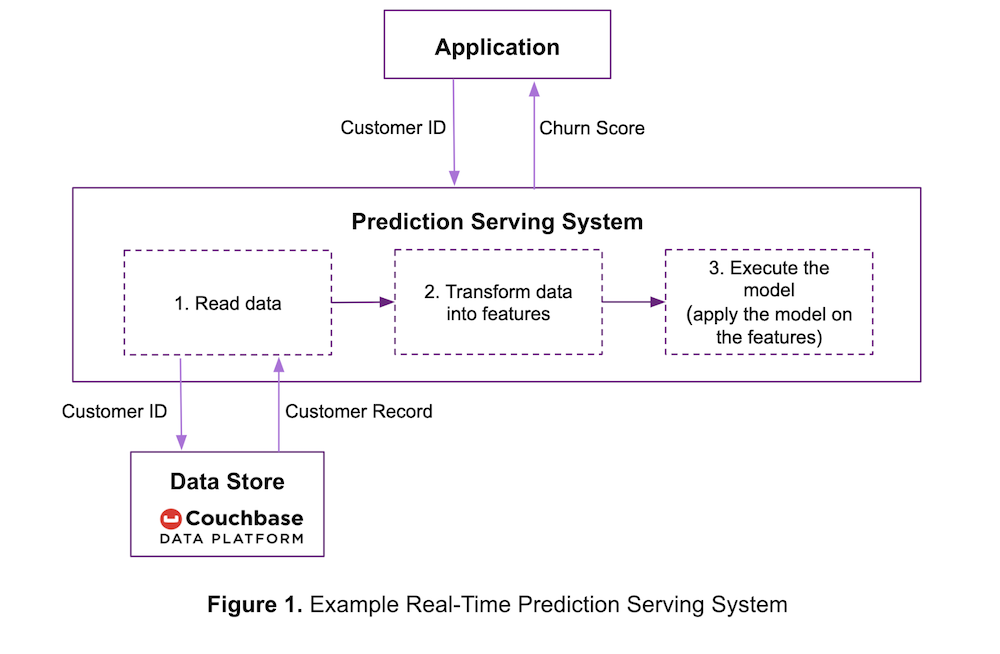
To find the churn score of a customer, an ACME application sends the customer ID to the prediction serving system. The prediction system then:
- Reads customer raw data from the data store.
- Transforms the data into features expected by the model, e.g., a true or false value is converted to 0 or 1.
- Applies the trained model on the features to calculate the prediction and returns it to the application.
If the trained model is also a pipeline, which transforms data into features, then steps 2 and 3 are combined. In order to provide the most timely predictions, the system needs to complete all of the above steps in as little time as possible.
If ACME were to store their input data on the low read-latency Couchbase Data Platform as shown in Figure 1, it will reduce the time to complete step 1. Of course, Couchbase might also be an operational database serving ACME’s other applications at the same time.
If the prediction serving system doesn’t require an entire document, then Couchbase’s sub-document API helps it access only the parts of the JSON documents it needs. Using the sub-document API improves performance and network I/O efficiency, especially when working with large documents.
Use Case #2: Real-Time Predictions with Features Stored on Couchbase
To improve performance, ACME may decide to pre-process the input data and store it in a feature store as shown in Figure 2 below.
Advantages of this approach include:
-
- The features are readily available for a quick lookup while making predictions.
- Data doesn’t have to be transformed into features each time the model is updated. This is an advantage over model pipelines.
- The features can be reused across multiple models.
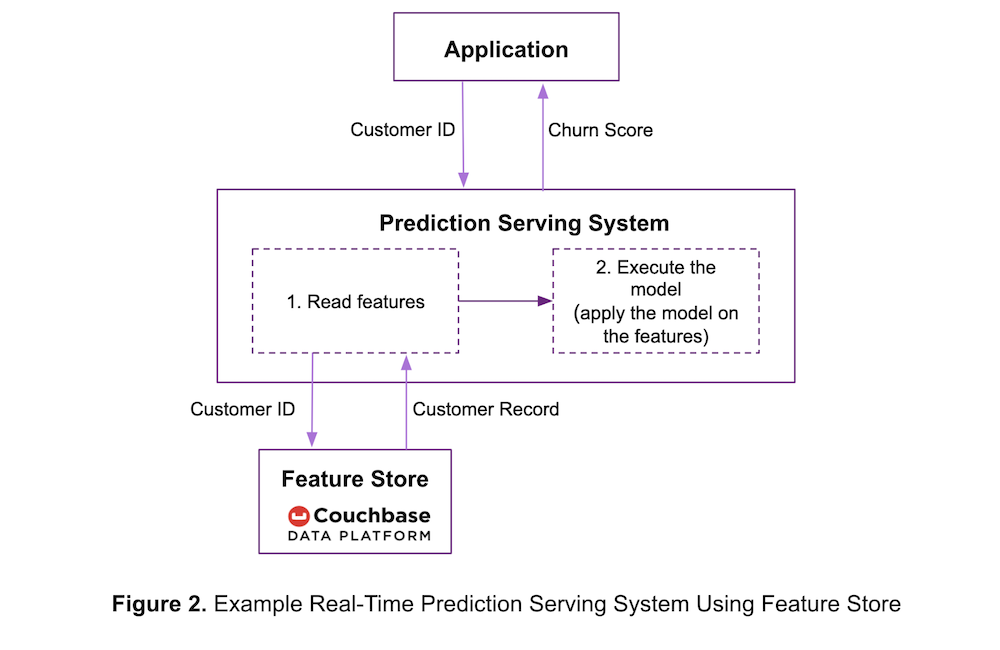
In this architecture, the prediction serving system:
- Reads features from the feature store.
- Applies the trained model on the features to generate a prediction and returns the prediction to the application.
If ACME stores the features on the fast data ingest Couchbase Data Platform, the features are written quickly. As before, the low read-latency provided by Couchbase reduces the time taken to execute step 1, in turn reducing prediction latency.
The time taken to execute step 2 depends on the model performance. Simpler linear models are fast but sophisticated models such as deep neural networks are computationally intensive and can take longer to generate predictions. Users may need to simplify complex models or use hardware accelerators to reduce the time taken by step 2.
Use Case #3: Precomputed Predictions Cached on Couchbase
ACME customer support has a problem: When a customer calls with a complaint, they need to know the customer’s churn score and quickly.
Waiting for the prediction service to calculate the churn score in real time is not an option. To solve this, ACME may decide to precompute predictions using a batch job as shown in Figure 3 below.
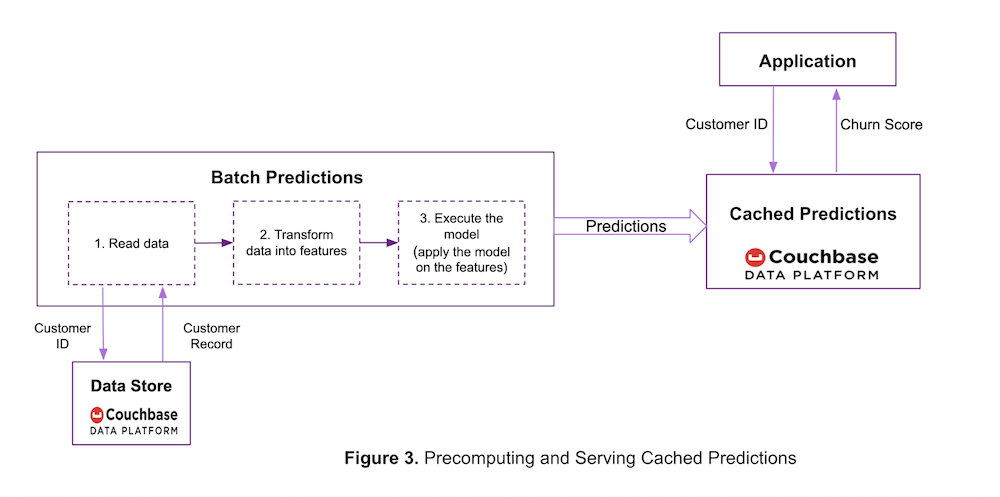
In this architecture, the model execution step is not in the critical path of serving predictions and as a result, the complexity of the model (simple vs deep neural networks) may not be relevant.
Here the Couchbase Data Platform is used for two purposes:
- Storing the raw data (or features) needed for making predictions in the batch job.
- Caching the precomputed predictions to serve them at high throughput and sub-millisecond read latency. The customer ID is used as the key for the precomputed predictions.
By default, Couchbase persists the cached predictions to the disk. But if the predictions are regenerated periodically and their persistence is not needed, then ACME can cache the predictions in Couchbase Ephemeral buckets. This further improves performance by reducing the background disk overhead and lowers disk storage costs. (Learn more about using Ephemeral buckets with Couchbase Buckets.)
In addition to the performance gain from caching the predictions on Couchbase, there are other advantages of using the Couchbase Data Platform. The cached predictions can be indexed using Couchbase’s Index service and used to run queries using Couchbase’s Query service. For example, users can run a Couchbase N1QL query to identify high-risk customers whose churn score is predicted to be above a certain threshold. This can be used by ACME marketing to target these customers for promotional offers.
Couchbase supports multidimensional scaling where each service—data, index, query, eventing, analytics—can be scaled independently. This also provides workload isolation so that the workload of, say, the query service does not interfere with that of the data service.
Use Case #4: Event-Driven Predictions with Data Stored on Couchbase
ACME customer support has a new requirement: They want a customer’s churn score to be recomputed whenever the customer’s record changes.
To handle this use case, ACME may decide to generate predictions in near real time in response to an event and then have them cached for later, as shown in Figure 4 below.

This use case also shows how model metadata plays a role in the prediction process.
Model metadata is information about the model such as its name, version number, when it was trained and so on. It may also include the model’s performance metrics such as average prediction latency and accuracy.
In this example, the model metadata is used to identify the features expected by the trained model. Since this step is performed during the prediction process, the model metadata also needs to be stored on a fast lookup store.
As seen in Figure 4, a single Couchbase cluster can store the model metadata as well as the features and predictions. Each of these types of data can be stored in a separate Couchbase bucket. Couchbase supports multi-tenancy, that is, the ability for more than one application to store and retrieve information within Couchbase. Buckets are the logical elements used to support multi-tenancy.
Use Case #5: Cross Data Center Predictions with Couchbase
ACME is now expanding as an enterprise. To protect against data center failures and to serve low-latency predictions in different geographies, it deploys the prediction serving system in multiple data centers as shown in Figure 5 below.
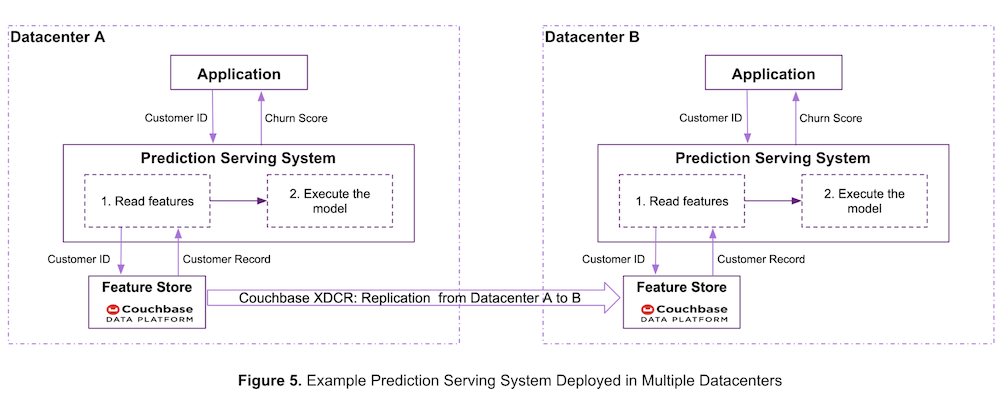
ACME uses Couchbase’s cross data center replication (XDCR) technology which enables customers to deploy geo-distributed applications with high availability in any environment (on-prem, public and private cloud, or hybrid cloud). Refer to the Couchbase XDCR documentation for more information on this technology.
As seen in Figure 5 above, ACME stores the features on the Couchbase Server and uses Couchbase’s XDCR feature to replicate the features from Data Center A to Data Center B.
Figure 6 below shows another way for ACME to serve predictions across data centers.
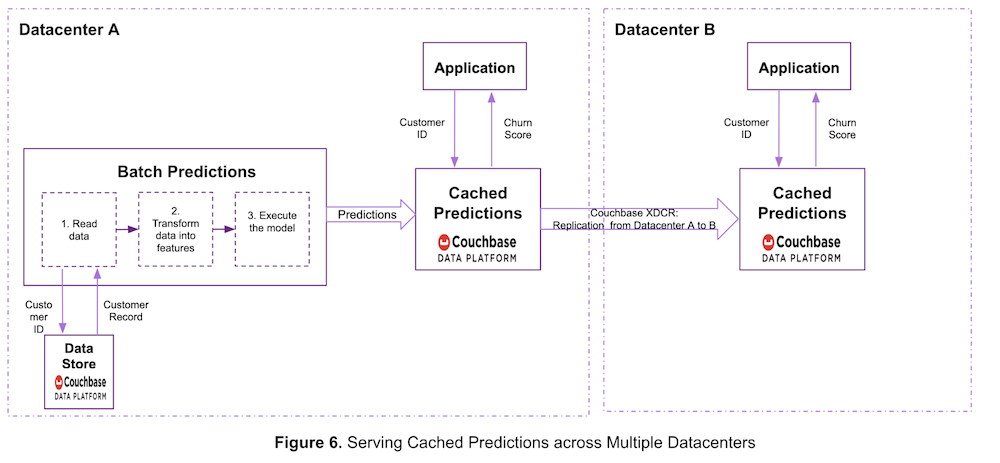
In this case, the prediction serving system is deployed in only one data center. Predictions are generated in Data Center A, then they are cached in Couchbase and replicated to other data centers using Couchbase XDCR.
Cross Data Center Replication is infrastructure-agnostic. In the above examples, Data Center A and Data Center B may be running in the same or different cloud environments or even different infrastructures like on-prem and cloud.
Couchbase Meets Other Requirements of Prediction Serving Systems
Couchbase can also be used to store feature metadata. This is the description of each feature in a feature store. The metadata may include the name of the feature, how it was created, its schema and so on. Features may be shared across multiple machine learning models. The feature metadata helps users discover features that are relevant to their models.
Couchbase allows data to be accessed at consistent low latency and at a sustained high throughput. In addition to meeting your performance needs, Couchbase also satisfies the following database requirements of a production-grade prediction serving system.
Scalability
As your prediction workload increases, your data store must continue to deliver the same steady-state performance. It must be able to scale linearly and easily without adversely impacting the performance of your prediction serving system.
Couchbase Server is designed to provide linear, elastic scalability using intelligent, direct application-to-node data access without additional routing and proxying. Adding or removing nodes is done in minutes with push-button simplicity, without any downtime or code changes.
Availability
To keep your prediction seving system available, the database must always be available during both planned and unplanned interruptions.
Couchbase Server is designed to be fault-tolerant and highly resilient at any scale and on any platform – physical or virtual – delivering always-on availability in case of hardware failures or planned maintenance windows.
Manageability
The data store should not place undue burden on your deployment and operations team for the prediction system. It should be reasonably quick to deploy and easy to monitor and manage.
Couchbase supports multiple methods of deployment including hybrid cloud and Docker containers with the Couchbase Autonomous Operator. The Couchbase Autonomous Operator provides native integration of Couchbase Server with open source Kubernetes and Red Hat OpenShift. It enables users to automate the management of common Couchbase tasks such as the configuration, creation, scaling, and recovery of Couchbase clusters.
Security
A secure database is critical for the overall security and integrity of your enterprise prediction serving system.
Couchbase provides end-to-end encryption of data both over the wire and at rest. Flexible security options are possible with role-based authentication and embedded data, and administrative auditing tools allow for robust control of your enterprise data.
Conclusion
You’ve now seen five real-world examples of how Couchbase is used to store raw input data, features, predictions, and model metadata. Whether you’re buying an enterprise prediction serving system or building your own, the Couchbase Data Platform powers peak performance and real-time results so you maximize the value of your machine learning predictions.
Here are some ways to get started and try out Couchbase for yourself:
-
- Start your free trial of Couchbase Cloud – no installation required.
- Dive deeper into the technical details with this white paper: Couchbase Under the Hood: An Architectural Overview.
- Explore the Query, Full-Text Search, Eventing, and Analytics services that Couchbase delivers.