With the introduction of vector search, users can now store large vector arrays—often made up of seemingly arbitrary numbers—within their documents. Since this data isn’t required for most standard queries, users can now leverage extended attributes (XATTRs), which are part of the document metadata, to store vectors and other bulky content. By doing so, performance is improved by keeping heavy data out of the primary query path. This post will explain what XATTRs are, highlight their benefits, and demonstrate how they can be used in search.
Where are XATTRs?
XATTRs are a document’s metadata which a user can modify or change without altering the document content. This allows the document to be separated into two parts. Services which require the documents will fetch them from the Key Value Store (KV) which gets XATTRs content only when it is required.
Let us take an example where the user is trying to index hotel data where the document structure looks like the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
{ "title": "Gillingham (Kent)", "name": "Medway Youth Hostel", "address": "Capstone Road, ME7 3JE", "directions": null, "phone": "+44 870 770 5964", "tollfree": null, "email": null, "fax": null, "url": "http://www.yha.org.uk", "checkin": null, "checkout": null, "price": null, "geo": { "lat": 51.35785, "lon": 0.55818, "accuracy": "RANGE_INTERPOLATED" }, "id": 10025, "country": "United Kingdom", "city": "Medway", "state": null,, "vacancy": true, "description": "40 bed summer hostel about 3 miles from Gillingham, housed in a districtive converted Oast House in a semi-rural setting.", "description_vector": [0.9293051,...(108 more float32s)...,0.41247833], "pets_ok": true, "free_breakfast": true, "free_internet": false, "free_parking": true } |
This document structure includes all necessary fields for a hotel, along with a vectorized description used to find hotels with similar descriptions. The description vector (line 25), which is a 110-dimensional vector, occupies around 1400 bytes, while the rest of the document is around 1400 bytes in size.
In regular use cases, when a user runs a non-vector query using SQL++ without a covering index, the entire document is fetched. This means that even though the vector, which is close to half the document’s size, is not required, it is still retrieved with the rest of the document, ultimately wasting resources.
Let us imagine a situation where the user does not use XATTRs and has the entirety of the data within the document content and none of it within XATTRs. Any service like query and search that tries to fetch documents will have to process all of the document content to get what they want.
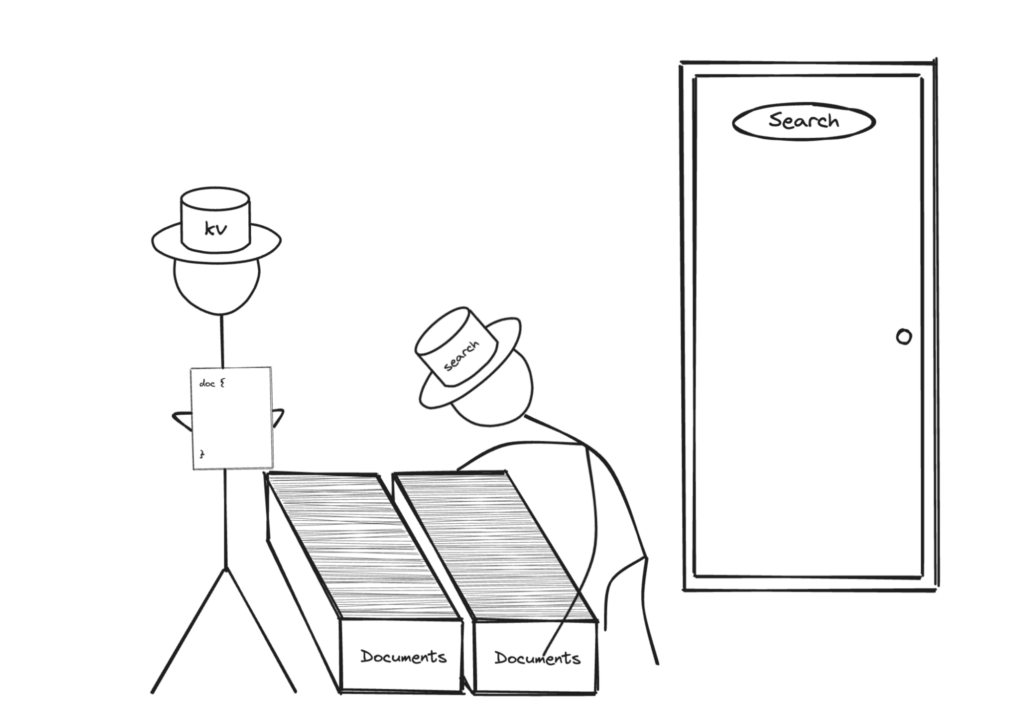
A better way to structure this document would be to store the vector as part of XATTRs. This would mean the services which come in looking for the non-vector data will only go through the non-XATTRs document content thereby cutting the amount of data transferred by half.
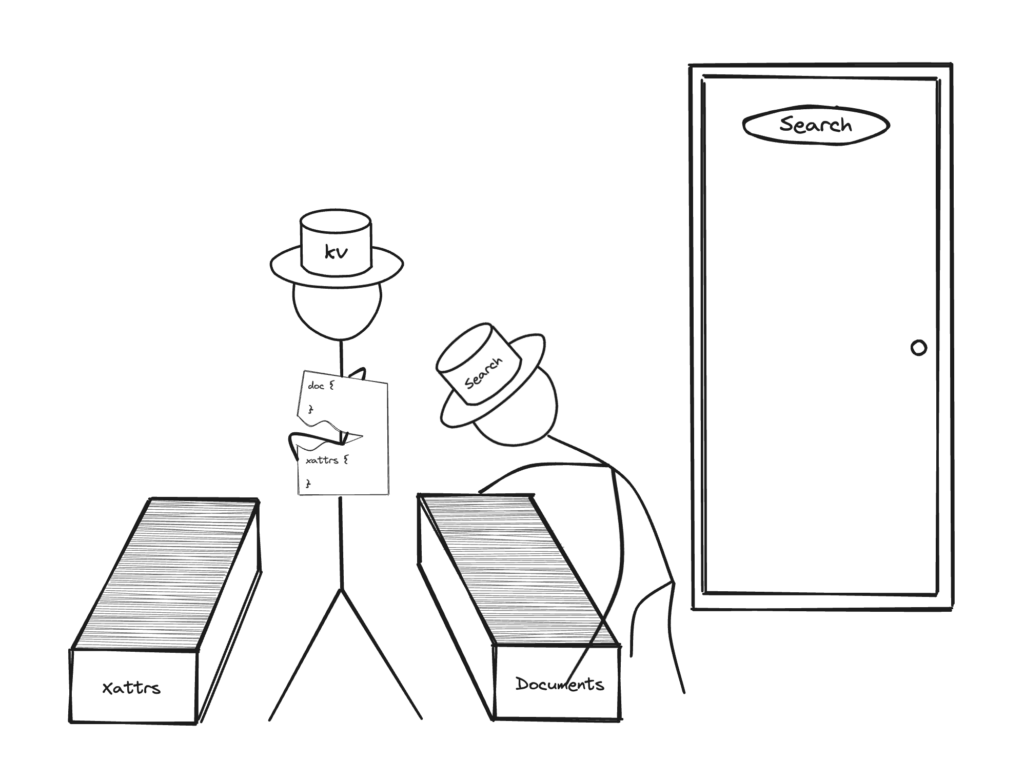
Users can even push this to an extreme by adding other sparsely used fields like geo information, contact details, etc., into XATTRs as well. This further reduces the amount of unnecessary data transferred.

How to index Couchbase XATTRs
From Couchbase Server 7.6.2 onwards, the search service offers users the ability to ingest data present in XATTRs only when required by the index mapping during the index creation process. If the XATTRs data is not relevant and an XATTRs mapping is not present in the index definition, then users can expect faster data ingestion and indexing rate because a lighter payload is fetched from the data service.
Let us assume a user created an index which indexes the XATTRs content. The index definition would look something like this, with XATTRs indexed in lines 10-27:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
{ "name": "example-index", "type": "fulltext-index", "params": { "mapping": { "default_mapping": { "enabled": true, "dynamic": true, "properties": { "_$xattrs": { "enabled": true, "dynamic": true, "properties": { "textField": { "enabled": true, "dynamic": false, "fields": [ { "name": "textField", "type": "text", "store": false, "index": true, "include_term_vectors": false, "include_in_all": false, "docvalues": false } ] } } } } }, "default_type": "_default", "default_analyzer": "standard", "default_datetime_parser": "dateTimeOptional", "default_field": "_all", "store_dynamic": false, "index_dynamic": true, "docvalues_dynamic": false }, "store": { "indexType": "scorch", "kvStoreName": "" }, "doc_config": { "mode": "type_field", "type_field": "type", "docid_prefix_delim": "", "docid_regexp": "" } }, "sourceType": "couchbase", "sourceName": "sample-bucket", "sourceUUID": "602c579bc2a74e67dc1f051eb769e702", "sourceParams": {}, "planParams": { "maxPartitionsPerPIndex": 1024, "numReplicas": 0, "indexPartitions": 1 }, "uuid": "" } |
Following the creation of the index using an index definition like above, search will fetch all of the document content and the XATTRs content from the data service.
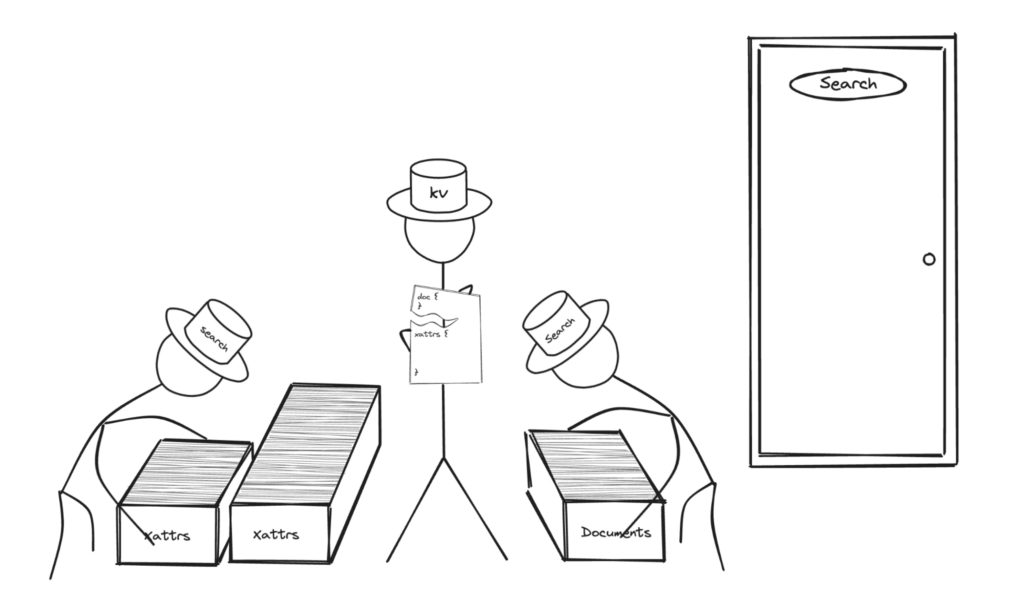
In this case, after fetching the content, the search service will then combine the two into a single document. The data present within XATTRs will be mapped into the document content under special field mapping named _$xattrs during the indexing process.

To query fields present in the XATTRs content, it should be noted that this content will be placed under a special field named _$xattrs and the query should reflect that. There is also an inherent restriction on the size of the XATTRs field name which is 12 characters.
Here is how it looks when building a query for a sample document with XATTRs:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "explain": true, "fields": [ "*" ], "highlight": {}, "query": { "query": "_$xattrs.textField:*" }, "size": 10, "from": 0 } |
XATTRs are not limited to storing vectors. Whenever there are fields which are infrequently used, fields only specific to the search service or bulky fields, it is advisable to add them to XATTRs. This way, services that do not need these fields need to fetch less data from KV.
Next steps
-
- Read more about Vector Search concepts in our blogs, including tutorials and concepts.
- Explore more on how to use XATTRs via SDKs through our documentation.
- Couchbase Capella’s free trial includes vector search, among many other features. Give it a try today.