What are embedding models?
Embedding models are a type of machine learning model designed to represent data (such as text, images, or other forms of information) in a continuous, low-dimensional vector space. These embeddings capture semantic or contextual similarities between pieces of data, enabling machines to perform tasks like comparison, clustering, or classification more effectively.
Imagine you want to describe different fruits. Instead of long descriptions, you use numbers for characteristics like sweetness, size, and color. For example, an apple might be [8, 5, 7] while a banana is [9, 7, 4]. These numbers make it easier to compare or group similar fruits.
What does an embedding model do?
An embedding model converts text, images, and audio into meaningful numbers and compares them to find patterns or connections. This process is similar to how a library organizes books by genre or topic, allowing users to find what they’re looking for faster.
Here are examples of daily use cases for embedding models:
Text search
Imagine typing “best Greek food” into a search engine. An embedding model will convert your query into numbers and retrieve documents with similar embeddings. The model will then show results that are close to your query.
Recommend movies
If you liked a movie, the system uses an embedding model to represent it (e.g., genre, cast, mood) as numbers. It compares these numbers to other movie embeddings and recommends similar ones.
Match images and captions
An embedding model can match an image of a sunset over the ocean with the caption “A serene sunset over calm ocean waves” by converting both the image and potential captions into numerical representations (embeddings). The model identifies the caption with an embedding closest to the image’s embedding, ensuring an accurate match. This technique powers tools like image search and photo tagging.
Group similar items
A shopping website uses embeddings to group similar products together. For instance, “red sneakers” might be close to “blue sneakers” in the embedding space, so they’re shown as related.
Types of embeddings models
There are several embedding models, each designed for different types of data and tasks. Here are the main types:
Word embedding models
These models convert words into numerical vectors that capture semantic meanings and relationships between words. Examples include:
-
- Word2vec: Learns word embeddings by predicting a word based on its context (skip-gram) or predicting context based on a word (CBOW).
- GloVe (Global Vectors for Word Representation): A model that uses word co-occurrence statistics from a large corpus to create embeddings.
- fastText: Similar to Word2vec, but considers subword information, making it more effective for morphologically rich languages.
Contextualized word embedding models
These models generate dynamic word embeddings based on the context in which a word appears. Unlike static embeddings, the meaning of a word can change depending on its usage.
-
- BERT (Bidirectional Encoder Representations from Transformers): Generates word embeddings based on the context of the surrounding words, making it highly effective for tasks like question answering and sentiment analysis.
- GPT (Generative Pre-trained Transformer): Generates contextualized embeddings for text generation and other language tasks.
- ELMo (Embeddings from Language Models: Provides word embeddings based on the entire sentence context, allowing it to capture deeper meanings.
Sentence or document embedding models
These models create embeddings representing entire sentences or documents rather than just individual words.
-
- Doc2vec: An extension of Word2vec that generates embeddings for whole documents by considering the context of the words in the document.
- InferSent: A sentence encoder that learns to map sentences into embeddings for tasks like sentence similarity and classification.
Image embedding models
These models represent images as vectors, enabling tasks like image recognition and retrieval.
-
- Convolutional Neural Networks (CNNs): Models like ResNet and VGG extract features from images and generate image classification and recognition embeddings.
- CLIP (Contrastive Language-Image Pre-training): A model that connects images and textual descriptions by generating embeddings for both and aligning them in the same vector space for tasks like image-text search.
Audio and speech embedding models
These models convert audio or speech data into embeddings, which are useful for tasks like speech recognition and emotion detection.
-
- VGGish: An embedding model for audio, particularly music and speech, based on CNNs.
- Wav2vec: A model by Meta AI that generates embeddings for raw speech audio, which is effective for speech-to-text tasks.
Each model is designed to handle specific types of data and tasks, helping to capture and represent relationships usefully for machine learning applications.
How are embedding models trained?
Embedding models are trained using large datasets and specific learning objectives that guide them to create meaningful numerical data representations. The training process involves the following steps:
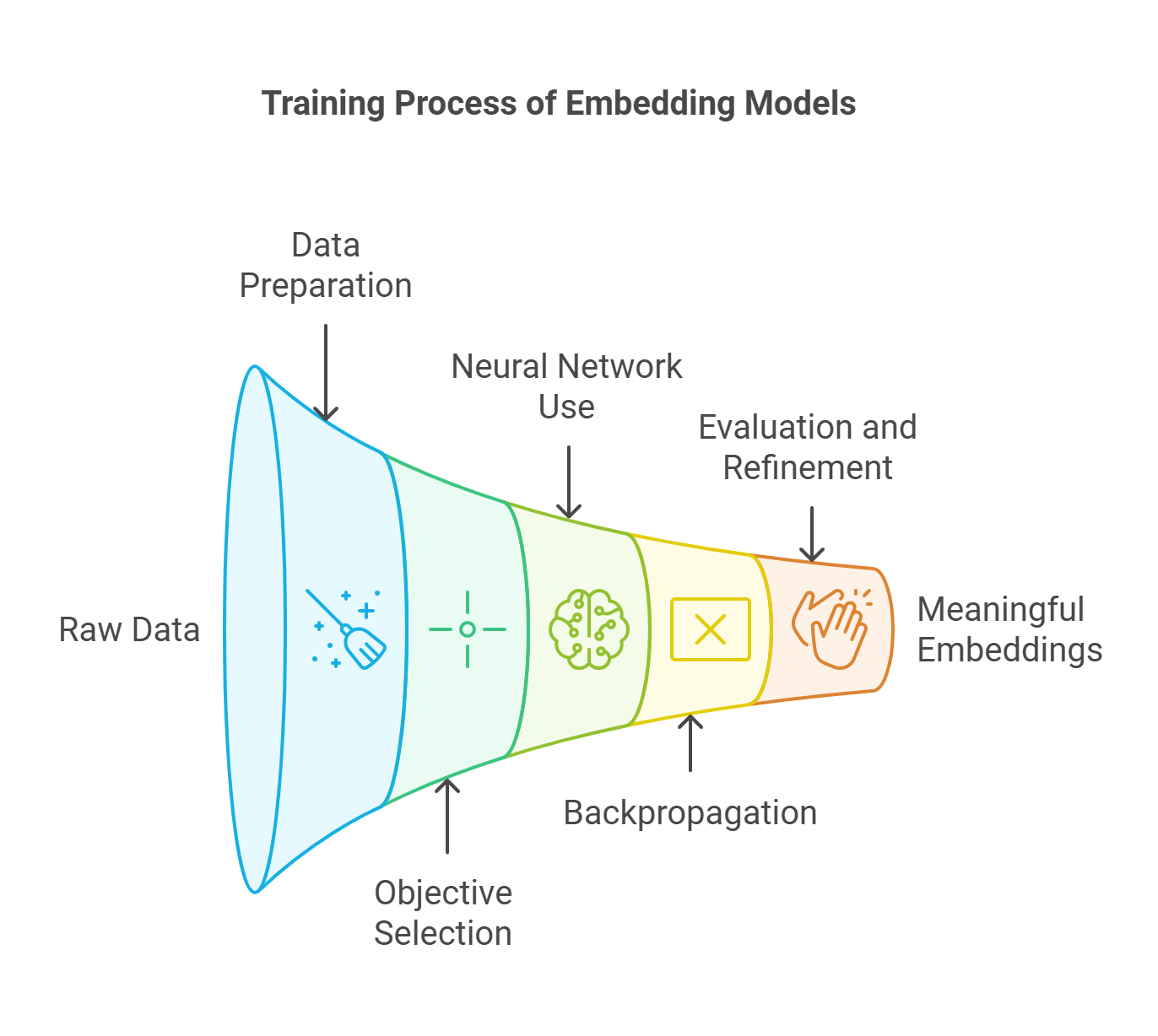
The training process for embedding models
1. Collecting and preparing data
-
- Datasets: Large datasets (like text corpora) are required for language embeddings, labeled image datasets for visual embeddings, and paired datasets (e.g., images and captions) for multimodal embeddings.
- Preprocessing: Text is tokenized into words or subwords, images are resized and normalized, and audio is transformed into spectrograms or other formats.
2. Choosing a training objective
The model learns to create embeddings by optimizing for a specific objective. Common objectives include:
-
- Predicting context (language models)
-
-
-
- Example: Word2vec’s skip-gram model predicts surrounding words for a given word. If the input is “The cat sat on the __,” the model might predict “mat.”
-
-
-
- Minimizing differences in related data (contrastive learning)
-
-
-
- Example: In CLIP, an image and its caption are brought closer in the embedding space, while unrelated images and captions are pushed further apart.
-
-
-
- Classification or task-specific objectives
-
-
- Example: A model might predict whether an image contains a dog or cat. The embeddings are adjusted to make the task easier by clustering similar images.
-
3. Using neural networks
-
- Shallow models: Early models like Word2vec use simple neural networks to learn embeddings based on co-occurrence patterns.
- Deep models: Transformers (e.g., BERT, GPT) and CNNs extract more complex patterns and relationships by processing data in layers.
4. Backpropagation and optimization
-
- The model makes a prediction, calculates an error (the difference between the prediction and the target), and adjusts its parameters using backpropagation.
- An optimizer (like Adam or SGD) updates the embeddings and the model’s weights to minimize this error.
5. Evaluating and refining
-
- The model is evaluated using validation data to ensure it produces meaningful embeddings for the intended tasks.
- Adjustments like hyperparameter tuning or fine-tuning on specific datasets are made to improve performance.
How do embedding models work?
Now, let’s dive into how these models work:

Embedding model process
1. Input data processing
The model inputs raw data (e.g., text, images, or audio) and pre-processes it in the following manner:
-
- Text is tokenized into smaller units like words or subwords.
- Images are broken into smaller elements like pixels or features.
- Audio is converted into waveforms or spectrograms.
2. Feature extraction
The embedding model analyzes the input to identify key features:
-
- With text, it considers the context and meaning of words.
- With images, it detects visual patterns, colors, or shapes.
- With audio, it identifies tones, frequencies, or rhythms.
For example, Word2vec learns relationships between words based on how often they appear together in a large dataset. For example, it might notice that “king” and “queen” frequently appear in similar contexts and assign them close embeddings in the vector space.
3. Dimensionality reduction
High-dimensional data (e.g., an image with millions of pixels) is compressed into a lower-dimensional vector. This vector preserves the essential information while discarding unnecessary details. For instance, an image might be reduced to a 512-dimensional vector, capturing its main features without retaining the full resolution.
4. Learning through training
Embedding models are trained on large datasets using machine learning techniques to detect patterns and relationships. These techniques include:
-
- Unsupervised learning: The model learns to organize data by clustering similar words or images together.
- Supervised learning: The model learns to align embeddings with specific labels or to distinguish between similar and dissimilar pairs (e.g., matching captions with the correct images).
5. Output embeddings
The model outputs a vector for each input. These embeddings can be:
-
- Compared using mathematical measures like cosine similarity.
- Grouped or clustered for analysis.
- Passed to other machine learning models for tasks like classification or recommendation.
How to choose the right embedding model
Choosing the right embedding model depends on the type of data you’re working with and the specific task you want to perform. Here are some key considerations to help you select the right one.
Type of data
-
- Text: If you’re working with text data, like sentences or documents, choose a model based on whether you need static word embeddings or dynamic, context-based embeddings. (e.g., Word2vec, GloVe, BERT, GPT).
- Images: If you’re dealing with images, you’ll need a model that can convert visual features into embeddings. (e.g., ResNet, VGG, CLIP).
- Audio: If you’re working with audio or speech data, look for models specifically designed to handle sound. (e.g., VGGish or Wav2vec).
Task requirements
-
- Word-level tasks: If you need to analyze or compare individual words, models like Word2vec or fastText may be appropriate.
- Sentence or document-level tasks: For tasks requiring a representation of whole sentences or documents (e.g., similarity or classification), models like Doc2vec or BERT are better suited.
- Multimodal tasks: If you need to work with text and images (or other combinations), models like CLIP or DALL-E are ideal because they align embeddings across different data types.
Performance considerations
-
- Speed and efficiency: Simpler models like Word2vec and GloVe are faster and less resource-intensive, making them suitable for smaller datasets and real-time applications. However, they may not capture nuanced relationships as well as more complex models.
- Accuracy and depth: More advanced models, such as BERT and GPT, provide high accuracy by capturing deep semantic relationships and context; however, they are computationally expensive and slow to train.
Size of dataset
-
- Large datasets: For large datasets, models like BERT and CLIP, which are pre-trained on vast amounts of data, can be fine-tuned to specific tasks.
- Smaller datasets: If you have limited data, models like fastText or Word2vec may perform better, as they can be trained with fewer data points.
Pre-trained models vs. custom training
-
- If you’re working on a general task and don’t need a highly specialized model, using pre-trained embeddings from models like BERT, GPT, or ResNet is often sufficient and saves time.
- If your data is highly specific (e.g., a niche domain or language), you may need to fine-tune a pre-trained model or train a custom model.
Conclusion
In this post, we explored how embedding models help transform complex data, such as text, images, or audio, into simplified numerical representations that computers can understand and process efficiently. By learning the relationships and patterns within the data, these models enable applications ranging from natural language processing to image recognition to multimodal tasks. Choosing the right embedding model depends on factors such as data type, the specific task, the size of the dataset, and available computational resources.
You can visit these resources from Couchbase to keep learning about vector embeddings and search: