Aggregate grouping is what I’m titling this blog post, but I don’t know if it’s the best name. Have you ever used MySQL’s GROUP_CONCAT function or the FOR XML PATH('') workaround in SQL Server? That’s basically what I’m writing about today. With Couchbase Server, the easiest way to do it is with N1QL’s ARRAY_AGG function, but you can also do it with an old school MapReduce View.
I’m writing this post because one of our solution engineers was working on this problem for a customer (who will go unnamed). Neither of us could find a blog post like this with the answer, so after we worked together to come up with a solution, I decided I would blog about it for my future self (which is pretty much the main reason I blog anything, really. The other reason is to find out if anyone else knows a better way).
Before we get started, I’ve made some material available if you want to follow along. The source code I used to generate the “patient” data used in this post is available on GitHub. If you aren’t .NET savvy, you can just use cbimport on sample data that I’ve created. (Or, you can use the N1QL sandbox, more information on that later). The rest of this blog post assumes you have a “patients” bucket with that sample data in it.
Requirements
I have a bucket of patient documents. Each patient has a single doctor. The patient document refers to a doctor by a field called doctorId. There may be other data in the patient document, but we’re mainly focused on the patient document’s key and the doctorId value. Some examples:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
key 01257721 { "doctorId": 58, "patientName": "Robyn Kirby", "patientDob": "1986-05-16T19:01:52.4075881-04:00" } key 116wmq8i { "doctorId": 8, "patientName": "Helen Clark", "patientDob": "2016-02-01T04:54:30.3505879-05:00" } |
Next, we can assume that each doctor can have multiple patients. We can also assume that a doctor document exists, but we don’t actually need that for this tutorial, so let’s just focus on the patients for now.
Finally, what we want for our application (or report or whatever), is an aggregate grouping of the patients with their doctor. Each record would identify a doctor and a list/array/collection of patients. Something like:
| doctor | patients |
|---|---|
|
58 |
01257721, 450mkkri, 8g2mrze2 … |
|
8 |
05woknfk, 116wmq8i, 2t5yttqi … |
|
… etc … |
… etc … |
This might be useful for a dashboard showing all the patients assigned to doctors, for instance. How can we get the data in this form, with N1QL or with MapReduce?
N1QL Aggregate grouping
N1QL gives us the ARRAY_AGG function to make this possible.
Start by selecting the doctorId from each patient document, and the key to the patient document. Then, apply ARRAY_AGG to the patient document ID. Finally, group the results by the doctorId.
|
1 2 3 |
SELECT p.doctorId AS doctor, ARRAY_AGG(META(p).id) AS patients FROM patients p GROUP BY p.doctorId; |
Note: don’t forget to run CREATE PRIMARY INDEX ON patients for this tutorial to enable a primary index scan.
Imagine this query without the ARRAY_AGG. It would return one record for each patient. By adding the ARRAY_AGG and the GROUP BY, it now returns one record for each doctor.
Here’s a snippet of the results on the sample data set I created:
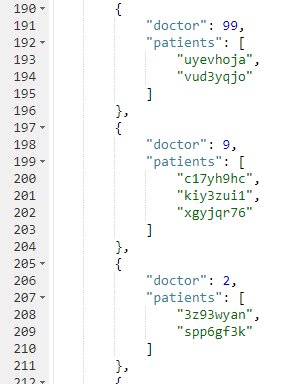
If you don’t want to go through the trouble of creating a bucket and importing sample data, you can also try this in the N1QL tutorial sandbox. There aren’t patient documents in there, so the query will be a little different.
I’m going to group up emails by age. Start by selecting the age from each document, and the email from each document. Then, apply ARRAY_AGG to the email. Finally, group the results by the age.
|
1 2 3 |
SELECT t.age AS age, ARRAY_AGG(t.email) AS emails FROM tutorial t group by t.age; |
Here’s a screenshot of some of the results from the sandbox:

Aggregate group with MapReduce
Similar aggregate grouping can also be achieved with a MapReduce View.
Start by creating a new View. From Couchbase Console, go to Indexes, then Views. Select the “patients” bucket. Click “Create Development View”. Name a design document (I called mine “_design/dev_patient”. Create a view, I called mine “doctorPatientGroup”.
We’ll need both a Map and a custom Reduce function.
First, for the map, we just want the doctorId (in an array, since we’ll be using grouping) and the patient’s document ID.
|
1 2 3 |
function (doc, meta) { emit([doc.doctorId], meta.id); } |
Next, for the reduce function, we’ll take the values and concatenate them into an array. Below is one way that you can do it. I do not claim to be a JavaScript expert or a MapReduce expert, so there might be a more efficient way to tackle this:
|
1 2 3 4 |
function reduce(key, values, rereduce) { var merged = [].concat.apply([], values); return merged; } |
After you’ve created both map and reduce functions, save the index.
Finally, when actually calling this Index, set group_level to 1. You can do this in the UI:
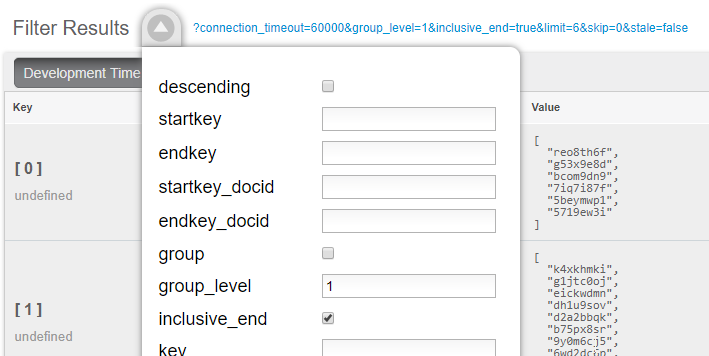
Or you can do it from the Index URL. Here’s an example from a cluster running on my local machine:
|
1 |
http://127.0.0.1:8092/patients/_design/dev_patients/_view/doctorPatientGroup?connection_timeout=60000&full_set=true&group_level=1&inclusive_end=true&skip=0&stale=false |
The result of that view should look like this (truncated to look nicer in a blog post):
|
1 2 3 4 5 6 7 8 9 |
{"rows":[ {"key":[0],"value":["reo8th6f","g53x9e8d", ... ]}, {"key":[1],"value":["k4xkhmki","g1jtc0oj", ... ]}, {"key":[2],"value":["spp6gf3k","3z93wyan"]}, {"key":[3],"value":["qnx93fh3","gssusiun", ...]}, {"key":[4],"value":["qvqgb0ve","jm0g69zz", ...]}, {"key":[5],"value":["ywjfvad6","so4uznxx", ...]} ... ]} |
Summary
I think the N1QL method is easier, but there may be performance benefits to using MapReduce in some cases. In either case, you can accomplish aggregate grouping just as easily (if not more easily) as in a relational database.
Interested in learning more about N1QL? Be sure to check out the complete N1QL tutorial/sandbox. Interested in MapReduce Views? Check out the MapReduce Views documentation to get started.
Did you find this post useful? Have suggestions for improvement? Please leave a comment below, or contact me on Twitter @mgroves.