As Couchbase data platform evolved, services like N1QL and GSI Indexing handled the use cases Couchbase VIEWS used to handle and much more. It’s logical to ask the comparative question between them. Here is a table comparing both. This is intended for developers and architects familiar with both them and not as an introductory article. Use the links here to learn more and play with the respective features.
| Topic |
Couchbase Map-Reduce Views |
Couchbase N1QL+GSI |
| Approach | Based on user-defined map() and reduce() functions that operate on data in the background. Because map() and reduce() is written in Javascript, you can code complex logic within those functions. | Based on declarative N1QL query (SQL for JSON). Uses appropriate indexes to optimize execution and executed dynamically by orchestrating Query-Index-data services. N1QL enables easily writeable and readable queries for JSON. Because it’s inspired by SQL, it’s flexible, composable. Because, it’s extended for JSON, it works on rich JSON data. Uses 4-valued boolean logic (true, false,NULL, MISSING) |
| More Info | Couchbase Docs: http://bit.ly/2jQrY11 |
|
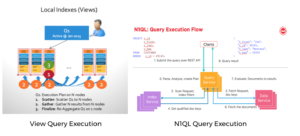
| Querying | Query based on
|
Query Statements
Query Operations:
|
| Indexing | Simple index for views. |
|
| Partitioning | Aligned to data partitioning. | Independent services.
N1QL and GSI scales independent of Data service and each other. |
| Scale | Scales with data service | Independent scaling via Multidimensional scaling (MDS) |
| Fetch with document key | Because the data is partitioned on document key, fetches the document directly from the node | Specify the query via USE KEYS clause.
Because the data is partitioned on document key, fetches the document directly from the node |
| Fetch with Index key | Scatter-Gather | Each index scan on a single node; Data on multiple nodes.
Post processing in Query node |
| Range scan | Scatter-Gather | Index scan on a single node.
Post processing in Query node |
| Grouping, aggregation | Built-in with Views API | Built into N1QL |
| Caching | File system | Index buffer pool
Data cache |
| Storage | Couchstore | Plasma storage engine (5.0 & above)
Memory Optimized Index (4.5 and above) ForestDB (community) |
| Availability | Replica Based | 5.0: Replicas
4.x: Equivalent Indexes |
| Query Latency
(Simple queries) |
10 milliseconds to 100 milliseconds | 5 milliseconds+ |
| Query Throughput
(Simple queries) |
3K to 4K queries per second | 40K queries per second |
| Scalability | Moderate (scaling tied to data service) | High (independent scaling of index and query services: MDS) |
| Applicability | Aggregations, best of large scale aggregations for low and moderate latency requirements. Map-reduce operations on the data is done in the background as the data is modified. | Best for attribute based lookup, range scans, complex select-join-project-array
Operations. Supports grouping, aggregation and ordering — these operations are done dynamically as part of query execution. |
| Application requirements | Report on well defined metrics
Large scale aggregations Latency sensitive |
Secondary key lookups
Range Scans Operational aggregations Filtered queries Ad-hoc queries with complex predicates, joins, aggregations, app search, pagination, secondary key based updates. |
| Spatial | Supported via Spatial Views | Not directly.
https://dzone.com/articles/speed-up-spatial-search-in-couchbase-n1ql |
| Consistency | Stale = UPDATE_AFTER
Stale = OK Stale = FALSE |
Unbounded (stale = OK)
AT_PLUS (read your own writes) REQUEST_PLUS (read after index updates up to now(). Stale = False). |
| Tools | Web console | Web console, Developer workbench, Query monitoring, Query Profiling, Visual explain, INFER. |