
Daniel Ancuta is a software engineer with several years of experience using different technologies. He’s a big fan of “The Zen of Python,” which he tries to apply not only in his code but in his private life as well. You can find him on Twitter: @daniel_ancuta
Geospatial queries: Using Python to search cities
Geolocation information is used every day in almost every aspect of our interaction with computers. Either it’s a website that wants to send us personalized notifications based on location, maps that show us the shortest possible route, or just tasks running in the background that checks the places we’ve visited.
Today, I’d like to introduce you to geospatial queries that are used in Couchbase. Geospatial queries allow you to search documents based on their geographical location.
Together, we will write a tool in Python that uses geospatial queries with Couchbase REST API and Couchbase Full Text Search, which will help us in searching a database of cities.
Prerequisites
Dependencies
In this article I used Couchbase Enterprise Edition 5.1.0 build 5552 and Python 3.6.4.
To run snippets from this article you should install Couchbase 2.3 (I am using 2.3.4) via pip.
Couchbase
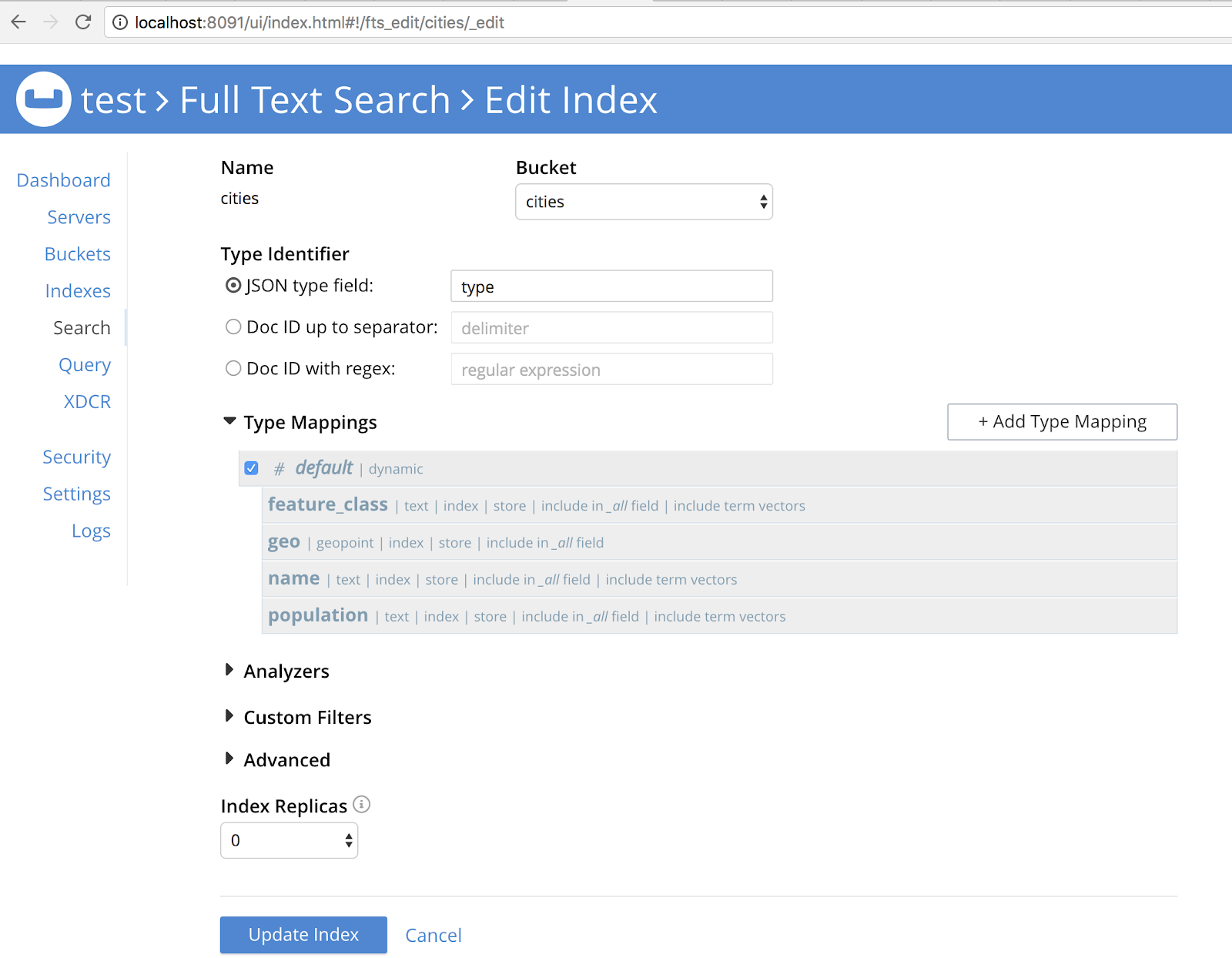
- Create a cities bucket
- Create a cities search with geo field of type geopoint type. You can read about it in the Inserting a Child Field part of the documentation.
It should look like the image below:
Populating Couchbase with data
First of all, we need to have data for our exercise. For that, we will use a database of cities from geonames.org.
GeoNames contains two main databases: list of cities and list of postal codes.
All are grouped by country with corresponding information like name, coordinates, population, time zone, country code, and so on. Both are in CSV format.
For the purpose of this exercise, we will use the list of cities. I’ve used PL.zip but feel free to choose whichever you prefer from the list of cities.
Data model
City class will be our representation of a single city that we will use across the whole application. By encapsulating it in a model, we unify the API and don’t need to rely on third-party data sources (e.g., CSV file) which might change.
Most of our snippets are located (until said otherwise) in the core.py file. So just remember to update it (especially when adding new imports) and not override the whole content.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# core.py class City: def __init__(self, geonameid, feature_class, name, population, lat, lon): self.geonameid = geonameid self.feature_class = feature_class self.name = name self.population = population self.lat = lat self.lon = lon @classmethod def from_csv_row(cls, row): return cls(row[0], row[7], row[1], row[12], row[4], row[5]) |
CSV iterator to process cities
As we have a model class, it’s time to prepare an iterator that will help us to read the cities from the CSV file.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# core.py import csv from collections import Iterator class CitiesCsvIterator(Iterator): def __init__(self, path): self._path = path self._fp = None self._csv_reader = None def __enter__(self): self._fp = open(self._path, 'r') self._csv_reader = csv.reader(self._fp, delimiter='\t') return self def __exit__(self, exc_type, exc_val, exc_tb): self._fp.close() def __next__(self): return City.from_csv_row(next(self._csv_reader)) |
Insert cities to Couchbase bucket
We have unified the way to represent a city, and we have an iterator that would read those from csv file.
It’s time to put this data into our main data source, Couchbase.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# core.py import logging import sys from couchbase.cluster import Cluster, PasswordAuthenticator logger = logging.getLogger() logger.setLevel(logging.DEBUG) logger.addHandler(logging.StreamHandler(sys.stdout)) def get_bucket(username, password, connection_string='couchbase://localhost'): cluster = Cluster(connection_string) authenticator = PasswordAuthenticator(username, password) cluster.authenticate(authenticator) return cluster.open_bucket('cities') class CitiesService: def __init__(self, bucket): self._bucket = bucket def load_from_csv(self, path): with CitiesCsvIterator(path) as cities_iterator: for city in cities_iterator: if city.feature_class not in ('PPL', 'PPLA', 'PPLA2', 'PPLA3', 'PPLA4', 'PPLC'): continue logger.info(f'Inserting {city.geonameid}') self._bucket.upsert( city.geonameid, { 'name': city.name, 'feature_class': city.feature_class, 'population': city.population, 'geo': {'lat': float(city.lat), 'lon': float(city.lon)} } ) |
To check if everything we wrote so far is working, let’s load CSV content into Couchbase.
|
1 2 3 4 5 |
# core.py bucket = get_bucket('admin', 'test123456') cities_service = CitiesService(bucket) cities_service.load_from_csv('~/directory-with-cities/PL/PL.txt', bucket) |
At this point you should have cities loaded into your Couchbase bucket. The time it takes depends on the country you have chosen.
Search cities
We have our bucket ready with data, so it’s time to come back to CitiesService and prepare a few methods that would help us in searching cities.
But before we start, we need to modify the City class slightly, by adding the following method:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# core.py @classmethod def from_couchbase_dict(cls, row): fields = row['fields'] return cls(row['id'], fields['feature_class'], fields['name'], fields['population'], fields['geo'][1], fields['geo'][0]) |
That’s a list of methods we will implement in CitiesService:
- get_by_name(name, limit=10), returns cities by their names
- get_by_coordinates(lat, lon), returns city by coordinates
- get_nearest_to_city(city, distance=’10’, unit=’km’, limit=10), returns nearest city
get_by_name
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# core.py from couchbase.fulltext import TermQuery INDEX_NAME = 'cities' def get_by_name(self, name, limit=10): result = self._bucket.search(self.INDEX_NAME, TermQuery(name.lower(), field='name'), limit=limit, fields='*') for c_city in result: yield City.from_couchbase_dict(c_city) |
get_by_coordinates
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# core.py from couchbase.fulltext import GeoDistanceQuery INDEX_NAME = 'cities' def get_by_coordinates(self, lat, lon): result = self._bucket.search(self.INDEX_NAME, GeoDistanceQuery('1km', (lon, lat)), fields='*') for c_city in result: yield City.from_couchbase_dict(c_city) |
get_nearest_to_city
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# core.py from couchbase.fulltext import RawQuery, SortRaw INDEX_NAME = 'cities' def get_nearest_to_city(self, city, distance='10', unit='km', limit=10): query = RawQuery({ 'location': { 'lon': city.lon, 'lat': city.lat }, 'distance': str(distance) + unit, 'field': 'geo' }) sort = SortRaw([{ 'by': 'geo_distance', 'field': 'geo', 'unit': unit, 'location': { 'lon': city.lon, 'lat': city.lat } }]) result = self._bucket.search(self.INDEX_NAME, query, sort=sort, fields='*', limit=limit) for c_city in result: yield City.from_couchbase_dict(c_city) |
As you might notice in this example, we used RawQuery and SortRaw classes. Sadly, couchbase-python-client API does not work correctly with the newest Couchbase and geo searches.
Call methods
As we now have all methods ready, we can call it!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# core.py bucket = get_bucket('admin', 'test123456') cities_service = CitiesService(bucket) # cities_service.load_from_csv('/my-path/PL/PL.txt') print('get_by_name') cities = cities_service.get_by_name('Poznań') for city in cities: print(city.__dict__) print('get_by_coordinates') cities = cities_service.get_by_coordinates(52.40691997632544, 16.929929926276657) for city in cities: print(city.__dict__) print('get_nearest_to_city') cities = cities_service.get_nearest_to_city(city) for city in cities: print(city.__dict__) |
Where to go from here?
I believe this introduction will enable you to work on something more advanced.
There are a few things that you could do:
- Maybe use a CLI tool or REST API to serve this data?Improve the way we load data, because it might not be super performant if we want to load ALL cities from ALL countries.
You can find the whole code of core.py in github gist.
If you have any questions, don’t hesitate to tweet me @daniel_ancuta.
This post is part of the Community Writing program