Part 1 – Building with Vonage and Couchbase to transform communication and data
Let’s imagine a paradigm shift in the way we perceive the role of AI in the workplace. Instead of AI replacing roles, what if it comes to enhance people’s work in those very same roles? In other words, instead of fearing AI making jobs redundant, we use AI to improve our own workflows and make ourselves more productive.
Does that seem far-fetched? It doesn’t have to be.
In this two-part blog post series, we are going to discover how to take advantage of the precision and clarity of vector search to build a customer support experience that empowers support agents. The end result will be to improve their effectiveness, not to replace them.
Why focus on customer support agents? Well, because they, more often than so many other roles, spend their entire day needing to access vast amounts of knowledge across a wide variety of topics and context switch between topics quickly and efficiently. They need to do all of this while maintaining friendliness and approachability with customers who are reaching out to them often in a state of distress. Customer support agents do this work day in and day out.
Could we build an experience for them that provides them with access to useful context faster and with less effort on their part for each and every customer ticket they are working on? Yes, and that’s exactly what we are going to do.
tl;dr In case you want to skip right to the implementation, you can find a fully working example of this application on GitHub along with detailed README instructions.
Here’s what we are going to build together –
A Ruby on Rails application that enables customer support agents to:
-
- Receive and reply to customers in the application dashboard via WhatsApp
- See answers to previously resolved queries that relate to the current open ticket to provide critical context
- Mark tickets as resolved and add their resolved answer to the knowledge base for context for future customer queries
All of this will be built using three services:
-
- Couchbase Capella, a fully managed database as a service (DBaaS) to store user and ticket information, along with the vector embeddings representing the knowledge base of resolved solutions
- Vonage Messages API, a multi-channel communications API that enables bi-directional conversations on WhatsApp, SMS, Facebook Messenger and other providers
- OpenAI Embeddings API, a service from OpenAI that converts data provided into vector representations of that data to enable vector search
Not sure what vector search and vector embeddings are? Check out this blog post that explains it all and how to get started in 5 minutes. When you are done reading it, come back here and continue the journey!
Ready to get started building? Let’s do it!
Scaffolding the Rails application
The first step to any new Rails application, starts with the beloved rails new command in the terminal, and this project is no different.
Go ahead and initialize a new application by executing the following on your command line:
|
1 |
rails new whatsapp_support_app –css tailwind |
This command will create a brand new Rails application with TailwindCSS installed. We will be using Tailwind for the styling of the frontend of the application.
Then, once the command has finished executing, change into the new directory and let’s install the additional dependencies we will need, namely the Vonage Ruby SDK, the Couchbase Ruby ORM, and a popular Ruby OpenAI SDK:
|
1 |
bundle add vonage couchbase-orm ruby-openai |
Go ahead at this point and run bundle install to install these dependencies.
Now, let’s create the initializer for both the Vonage and OpenAI clients in our app:
|
1 2 |
touch config/initializers/vonage.rb touch config/initializers/openai.rb |
While we are creating files in the config directory, let’s also add the configuration file where we will define our connection settings to Couchbase:
|
1 |
touch config/couchbase.yml |
Once we have created the files for the initializers, we can create the files to hold our future Models and Controllers:
|
1 2 3 4 5 |
touch app/controllers/messages_controller.rb touch app/controllers/dashboard_controller.rb touch app/models/ticket.rb touch app/models/user.rb touch app/models/agent.rb |
The only files left to create at this point are the frontend views, and we will create those later in the Creating the Frontend for the Application section.
At this point, your file structure should look something like this, also including all the standard Rails files that are not mentioned below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
whatsapp_support_app/ app/ controllers/ application_controller.rb messages_controller.rb dashboard_controller.rb models/ application_record.rb ticket.rb user.rb agent.rb config/ initializers/ vonage.rb openai.rb couchbase.yml application.rb environment.rb routes.rb |
The last bit we will add at this point is a file to hold our credentials and other confidential information we do not want to check into Git or make publicly available:
|
1 |
touch .env |
With that last file, we are ready now to move on and create our Couchbase Capella account, our cluster and our bucket to hold ticket and user data.
Setting up Couchbase Capella
Capella is a fully managed database as a service (DBaaS) brought to you by Couchbase. It offers a complete data platform to help accomplish many of your needs, from caching to full text search to big data analytics with Columnar. For this application, we are going to leverage Capella’s JSON document database along with its vector search capabilities.
Each document hosted in Capella is either going to be a ticket or a user:
-
- A user document will hold the WhatsApp phone number the user messaged on.
- A ticket document will have the original query, the user ID of the user who asked the query, the status of the ticket (either open or resolved), eventually a summary of the solution, and the vector embedding representing the solution.
We are also going to create a vector search index that will enable the application to search through the embeddings hosted in the ticket documents for similarities to the ticket an agent is currently working on.
Create a Capella account
The first step is to create a free Capella account. To do so, navigate to cloud.couchbase.com and sign up with either your Google or GitHub account or create an account using an email and password combination.

That’s all it takes to create an account! Now that you have your account, you can create your cluster. A cluster, in case you are unfamiliar with the terminology, is akin to a database server. Let’s do it!
Create a cluster
Capella works in a multi-cloud environment, which means you have the freedom to choose to deploy your cluster to AWS, GCP or Azure. All you need to do is click which one you prefer and Capella, behind the scenes, takes care of the rest for you.
From the home page of your account after you log in click on the + Create Database button in the top right corner and fill in the details, namely the name you chose for it. If you don’t have a name picked out already, perhaps you whatsapp_support_cluster.
When you are ready go ahead and click on the final Create Database button and let Capella do the rest of the work for you.
You now have a Cluster, i.e. Database. The next step is to add a bucket to hold your data. A bucket is akin to a database table, with significant differences. Since you are working with unstructured and semi-structured JSON data, a single bucket can hold diverse types of data.
Create a bucket
Now that you are in the view in the Capella dashboard for your cluster, you will see another + Create button in the top left corner. Once you click the button, you will have the ability to create your first Capella bucket.

Let’s name the bucket whatsapp_support_bucket and make sure to click on the use system generated _default for scope and collection checkbox.
Now, add the bucket name to your .env file you created earlier like this:
|
1 |
COUCHBASE_BUCKET=your_bucket_name |
With your bucket created, the last bit we will do at this point is create your access credentials and fetch your Capella connection string.
Create access credentials
In order to interact with your data on Capella from your application, you need to know the connection string and create access credentials. The connection string can be found by clicking on the Connect button in the top navigation bar in the dashboard. Go ahead and add that to the .env file you created earlier in your codebase like this:
|
1 |
COUCHBASE_CONNECTION_STRING=your_connection_string |
To add access credentials, you will navigate to this page in your Capella settings like shown below and click on the + Create Database Access button. You will provide a name and password and click save. Make sure to immediately add the credentials to your .env file as you won’t be able to access the password again after this:
|
1 2 |
COUCHBASE_USERNAME=your_username COUCHBASE_PASSWORD=your_password |

After creating your credentials, your Capella setup is just about complete! The last step is to create the vector search index, which you can follow the steps outlined in this post to do so.
At this point, you are ready to move on to set up the WhatsApp API service provider that will power the conversations in the application. For our service provider, we will be using the Vonage Messages API.
Using the Vonage Messages API
Vonage offers a suite of communications APIs that cover almost every aspect of modern day interactions, from SMS to phone calls to chatbots. The API we will be using for this application is the Messages API and it offers multi-channel communications in a single API for Facebook Messenger, WhatsApp, Viber, SMS and MMS.
We will be using it for its WhatsApp capabilities, in which you can both send and receive WhatsApp messages programmatically.
Setting up the WhatsApp functionality for production usage requires several steps from Meta, namely the creation of a WhatsApp business account. The details on what this is and the steps to do so are explained in the Vonage documentation, and you are encouraged to read more about it there.
However, just because you don’t have a Meta WhatsApp business account yet, does not mean that you can’t build and test out the functionality! Enter into the scene the Vonage Messages API sandbox. With the sandbox, you can authenticate your personal cell number to programmatically send and receive WhatsApp messages. This allows you to build out your application robustly while you await your Meta WhatsApp business account approval.
Now that we understand a bit of the context, let’s go ahead and create a Vonage APIs account.
Create a Vonage account
To create a Vonage account navigate to dashboard.vonage.com and click on sign-up. It is free to create an account and to begin building with the various APIs.
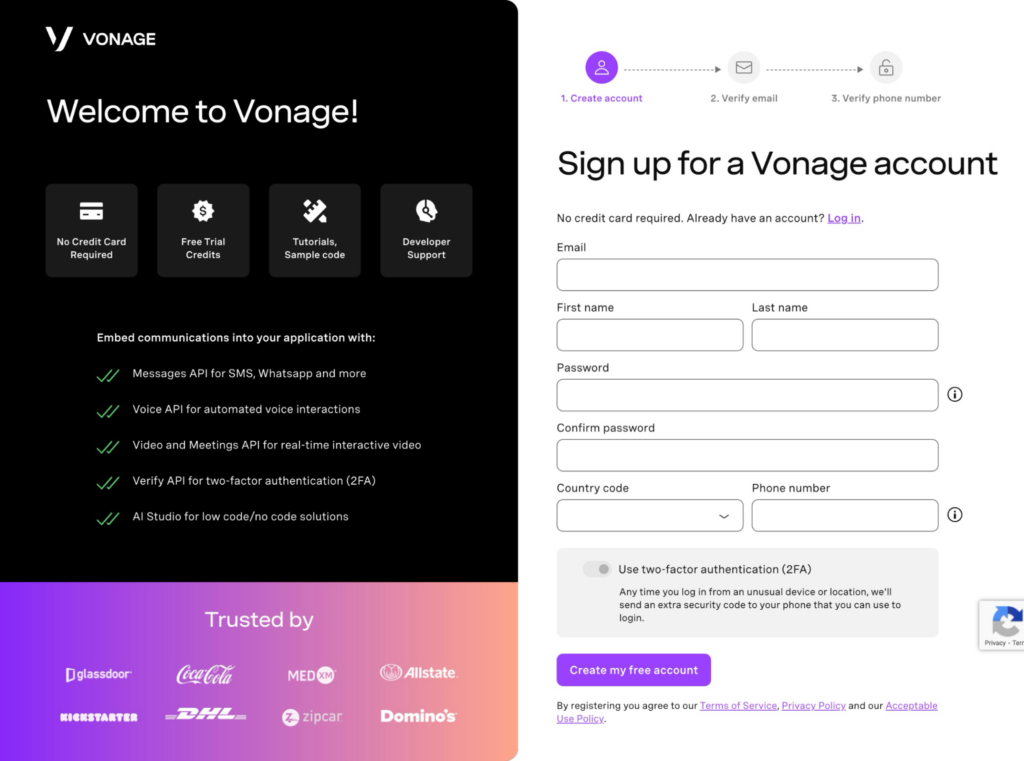
Now that you have your account, you’re ready to set up the Messages API sandbox!
Configure the Vonage Messages API Sandbox
As explained above, the sandbox is excellent for testing and prototyping your application. It allows you to send and receive messages from a preconfigured Vonage phone number and an approved personal phone number.
To configure the Vonage Messages API sandbox, you will need to send a message to the preconfigured Vonage phone number provided. The dashboard will guide you through the process by providing a QR code, a link and a direct phone number to send a message to. It will also share the exact message to send to the number. You can choose to use any of the methods to send the message.
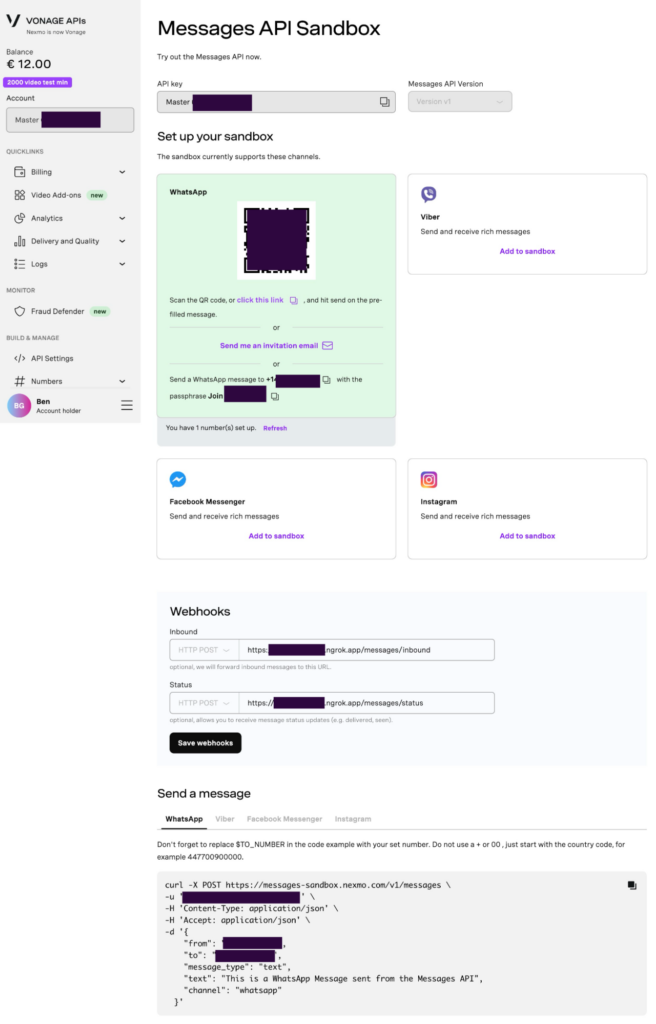
Once you send the message, you will have successfully configured your personal phone number to receive and reply to messages from the Vonage Messages API sandbox.
You will notice the space in the sandbox setup to provide URLs for both Inbound and Status webhook messages. The way in which you receive new WhatsApp messages from the API is via a webhook, so you need to have an externally accessible URL to provide for the webhook to access. There are popular tools available that can expose your localhost environment to the Internet and provide you with an external URL, amongst them is ngrok.
Using ngrok is as straightforward as installing it on your machine and then running ngrok http 3000 in a separate terminal window. The command takes two arguments in this example:
-
- The service to expose – http
- The port the localhost server is running on – 3000
Follow the Quickstart Guide from ngrok with instructions on how to install ngrok on your machine depending on if you are using Mac, Linux or Windows.
Define the Vonage environment variables
As you have been adding your Capella details to your .env file, you will now add your Vonage details to the same file. Namely, you need to add your API key and secret and the preconfigured Vonage phone number provided to you in the sandbox.
Go ahead and open the .env file and add the following:
|
1 2 3 |
VONAGE_API_KEY=your_vonage_api_key VONAGE_API_SECRET=your_vonage_api_secret VONAGE_FROM_NUMBER=your_vonage_from_number |
Now that you have set up both Capella and Vonage, the last step in initial setup is to create an OpenAI API account and add your OpenAI API key to your .env file.
Getting started with the OpenAI Embeddings API
Before we create an OpenAI account, let’s take a moment to understand why we are using OpenAI and what an embedding is. Full disclosure, this is not meant to be a comprehensive look at vector embeddings and what they do. Rather, consider this just a brief overview to equip you to build the application.
A vector embedding is an array of numbers that mathematically represents a piece of data. That data could be text, an image, audio or a video. There are different algorithms that generate these embeddings, each designed to capture various aspects of the data in a way that makes it useful for machine learning models.
For example, in the context of text, an embedding captures the semantic meaning of words or sentences, allowing the AI to understand relationships between concepts beyond simple keyword matching. These embeddings become the building blocks for tasks like search, classification, and recommendation systems, as they enable machines to process and compare complex data efficiently. By using OpenAI’s powerful models, we can generate high-quality embeddings that will allow our application to perform advanced functions such as content similarity matching, which is exactly what it is meant to do when it searches for previously resolved answers to support agents in their current tickets.
Now, let’s proceed with setting up your OpenAI account so we can start building.
Create an OpenAI account
To create an account, head over to platform.openai.com and sign up with your Google, Microsoft or Apple credentials, or create an account using an email and password combination.
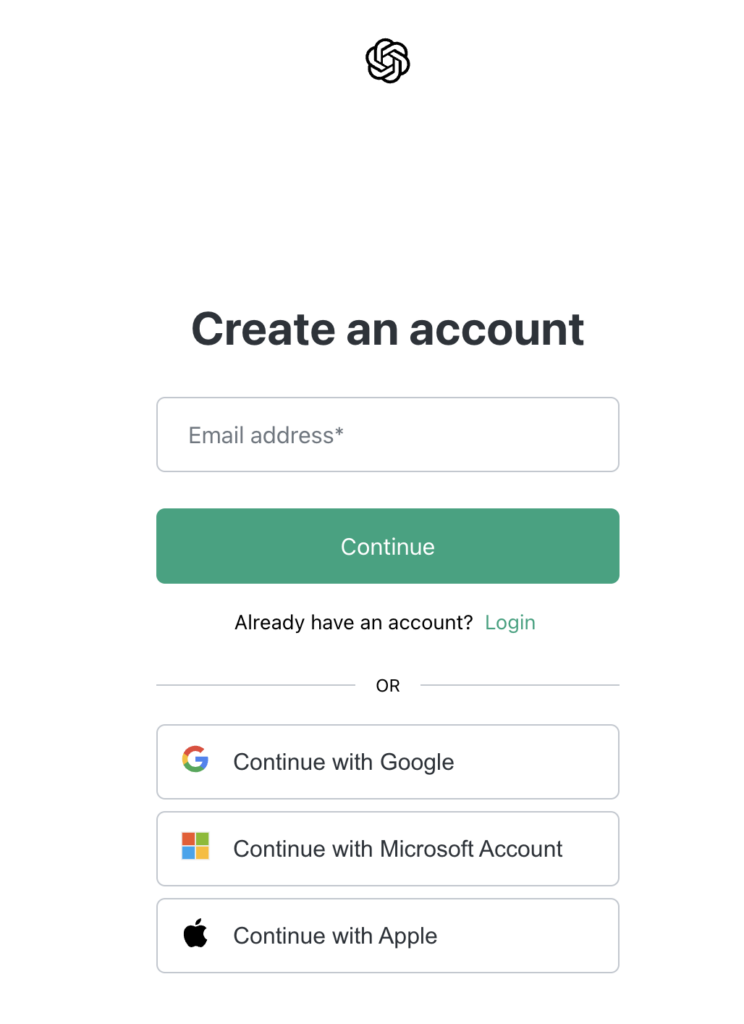
Now that you have your account, all you need to do is create and copy your API key.
Create OpenAI API key
Once you have an account, you can navigate to platform.openai.com/api-keys and create a new API key by clicking on the + Create new secret key button on the top right part of the page.

Similar to your other credentials, you need to immediately save the key as you will not be able to view it again in the dashboard after this moment. As such, add it to the .env file like so:
|
1 |
OPENAI_API_KEY=your_api_key |
That’s it! At this point, you have all your external services defined and set up. You are now ready to build your application. Let’s get going!
To be continued…
In the second part of this two-part series, we will build the application business logic and run our application for the first time. Make sure to check out part two to continue your journey.