When’s the last time you used a database? Most of us are so accustomed to user-friendly interfaces like TikTok, bank apps, and work programs that we don’t realize we’re interacting with databases all the time. We’re even less inclined to think about what’s happening behind the scenes, which can pretty much be broken down into two types of activity: transactional and analytical. A transaction might be uploading a video or making a purchase. Data analysis could be as simple as crunching the numbers on a spreadsheet.
In a relational database, the data for either type of activity is organized into rows and columns that form a table (or tables) to show the relationship between data points. The data can be stored in two different ways: In a columnar database (column store), all the data is grouped together by column. In a row-oriented database (row store), all the data is grouped together by row.
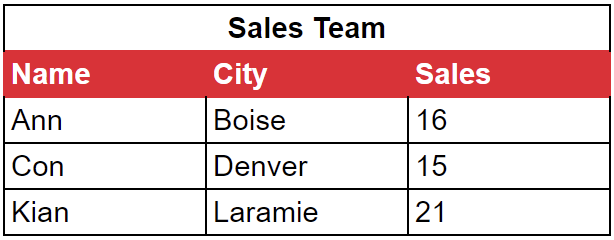
Columnar databases excel at handling analytical workloads, while row-oriented databases are better suited for transactional workloads. To explain the differences and discuss the relative pros and cons, we’ll use the data in this table that tracks a sales team:
What is a columnar database?
A columnar database stores data grouped by columns rather than by rows, optimizing performance for analytical queries. Each column contains data of the same type, allowing for efficient compression. And because a query needs to access only relevant columns, the design enhances data retrieval speed.
While a columnar database is a type of relational database, Couchbase Capella™ is a NoSQL DBaaS that also uses column grouping to perform lightning-fast analytics. It does this by rapidly ingesting JSON and other data sources and converting them to columnar storage.
Writing to column store databases
In a columnar database, data is written to disk by column. That means our sales team data would be grouped and stored like this:
|
1 |
Ann Con Kian | Boise Denver Laramie | 16 15 21 |
Let’s add the following record for a new employee, Gene:

To add Gene’s data, we append it to the end of the respective columns like this:
|
1 |
Ann Con Kian Gene | Boise Denver Laramie Hanford | 16 15 21 0 |
Reading from column store databases
In a columnar database, data is read by accessing specific columns rather than entire rows. When a query is executed, the database retrieves only the columns needed to fulfill the query conditions. This process involves accessing the relevant column data directly, which can significantly reduce I/O overhead and improve query performance, especially for analytical workloads that typically involve aggregations, filtering, and selective projections.
By reading only the necessary columns, columnar databases minimize data transfer and maximize CPU cache utilization. For analytical queries, this results in faster query execution times compared to row-oriented databases.
For example, if we wanted to calculate the average number of sales across the sales team, a columnar database would only have to access the column with the sales figures. This would be much faster and more efficient than a row-oriented database, which would have to access all the data row by row to pull out the relevant sales data.
What is a row storage database?
A row-oriented database organizes data by rows, with each row containing information about a single entity or record. This design is suitable for transactional workloads where entire rows are frequently accessed or modified. Row-oriented databases excel in transaction processing systems where they can ensure fast inserts, updates, and deletes by storing data contiguously on disk to minimize overhead for row-level operations.
Writing to row storage databases
In a row store database, data is written to disk by row rather than by column.
Our sales team data would be stored like this:
|
1 |
Ann Boise 16 | Con Denver 15 | Kian Laramie 21 |
To add Gene’s record, we would append it in its entirety to the end of the existing data like this:
|
1 |
Ann Boise 16 | Con Denver 15 | Kian Laramie 21 | Gene Hanford 0 |
This approach ensures that all record attributes are stored together, facilitating fast retrieval and updates of entire rows. Additionally, row-oriented databases often use logging and buffering mechanisms to optimize write operations.
Reading from row store databases
In a row store database, data is read by accessing entire rows sequentially or through index lookups. When a query is executed, the database retrieves the relevant rows containing the requested data. This retrieval process involves scanning through the rows on disk and fetching entire records that match the query criteria. While row-oriented databases excel at retrieving entire records quickly, they may incur overhead when only specific columns are needed. Because rows must be retrieved in their entirety, this can lead to unnecessary data transfer and processing.
Columnar database vs. row database
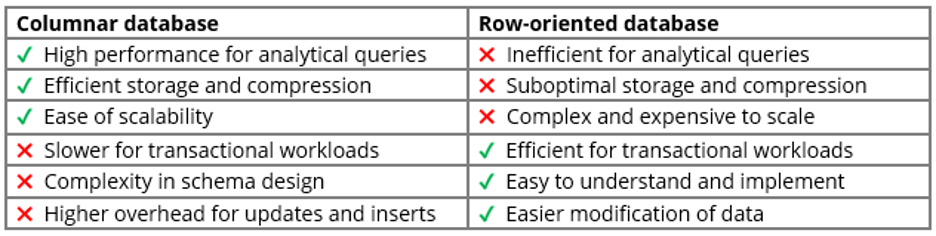
Columnar and row-oriented databases each have distinct benefits and drawbacks related to the way their data is organized. Columnar databases excel in analytical queries and provide efficient storage, but they can struggle with transactional workloads and are more difficult to update. In contrast, row-oriented databases are efficient for transactional workloads and are easier to implement and modify, but they’re inefficient for analytical queries and offer suboptimal storage. Here’s a more detailed breakdown of their pros and cons:
Pros of columnar databases
-
- High performance for analytical queries – Columnar databases excel in read-heavy analytical workloads, offering fast query processing times due to their ability to read only the required columns. This maximizes CPU cache utilization and minimizes I/O overhead.
- Efficient storage and compression – Data is organized by columns, allowing for efficient compression techniques to be applied. Similar data types and properties within columns enable high compression ratios to reduce storage costs and improve query performance.
- Ease of scalability – Columnar databases are advantageous for scalability. Since data is stored in columns, adding additional nodes or servers can be straightforward with each node handling a subset of columns. This scalability is particularly beneficial for analytical workloads where datasets are often large and constantly growing.
Cons of columnar databases
-
- Slower for transactional workloads – While columnar databases excel in analytical queries, they may perform slower for write-heavy transactional workloads involving frequent updates, inserts, and deletes.
- Complexity in schema design – Designing a schema for a columnar database may require careful consideration of column organization and data types to optimize query performance and storage efficiency.
- Higher overhead for updates and inserts – Updating or inserting data in a columnar database can be more complex and resource-intensive compared to row-oriented databases. Columnar databases may require additional processing to maintain data consistency and ensure efficient storage.
Pros of row databases
-
- Efficient for transactional workloads – Row-oriented databases are well-suited for transactional workloads where entire records need to be retrieved, updated, or inserted quickly and efficiently. The row-based storage structure simplifies these operations and ensures fast transaction processing.
- Easy to understand and implement – The row-oriented storage model aligns with the intuitive understanding of data organization, making it easier to design, implement, and maintain databases using this approach. Developers familiar with relational databases find row-oriented databases straightforward to work with.
- Easier modification of data – Row-oriented databases make it easier to modify data, allowing for straightforward updates, inserts, and deletes without significant overhead. This makes them suitable for scenarios with frequent write operations or evolving data requirements.
Cons of row databases
-
- Inefficient for analytical queries – Row-oriented databases may exhibit slower performance for read-heavy analytical queries that involve aggregations, projections, and filtering. Retrieving entire rows for such queries can lead to unnecessary data transfer and processing overhead, reducing query performance compared to columnar databases.
- Suboptimal storage and compression – Storing data in rows may result in suboptimal compression ratios compared to columnar databases. In row-oriented databases, rows typically contain diverse data types and properties, making it challenging to achieve high compression levels and efficient storage.
- Complex and expensive to scale – Because row-oriented databases must store data in rows, it can be more complicated to distribute the data effectively across multiple servers and nodes. The solution often involves adding more powerful hardware, such as increasing CPU or memory resources on existing servers, which can become prohibitively expensive as the dataset grows.
Columnar database examples
Some well-known columnar databases are:
-
- Amazon Redshift
- Apache Cassandra
- MariaDB ColumnStore
- Snowflake
Row-oriented database examples
Two of the most common row-oriented databases are:
-
- PostgreSQL
- MySQL
Why columnar databases are better for analytics
Columnar databases outperform row-oriented databases in analytics primarily due to their data storage and retrieval efficiency. Here are four ways they’re better:
Columnar storage structure – Because data is stored column-wise rather than row-wise, each column can be stored separately on disk. This structure allows better compression and encoding techniques to be applied to each column individually. Since columns typically contain similar data types, values, or properties, compression algorithms can achieve higher compression ratios compared to row-oriented databases, where rows may contain diverse data.
Selective retrieval – Analytical queries often involve aggregating or analyzing a subset of columns rather than entire rows. Columnar databases excel in such scenarios because they can selectively retrieve only the columns required for the query. This selective retrieval minimizes disk I/O operations and maximizes CPU cache utilization. In contrast, row-oriented databases retrieve entire rows even for queries that need only a few columns, resulting in unnecessary data transfer and processing overhead.
Data processing efficiency – When executing analytical queries, columnar databases operate on compressed columnar data directly, allowing for efficient processing of analytical functions such as aggregations, filtering, and projections. Since similar data types are stored contiguously, columnar databases can exploit SIMD (single instruction, multiple data) parallelism and other vectorized processing techniques, enabling faster query execution times. In contrast, row-oriented databases may need to decompress entire rows before performing analytical operations, which can lead to increased computational overhead.
Query optimization – Columnar databases are optimized for analytics through query execution strategies tailored to their storage format. These optimizations include column pruning, predicate pushdown, and vectorized processing techniques. Column pruning eliminates unnecessary column reads during query execution, while predicate pushdown filters rows early in the query processing pipeline, reducing the amount of data that needs to be processed. Vectorized processing techniques operate on batches of data, exploiting CPU parallelism for improved query performance.
Conclusion
While row-oriented databases are better for transactional processing, columnar databases are superior for analytical processing. The advantages of a row-oriented database lie in its ability to perform fast inserts, updates, and deletes. On the other hand, the primary advantages of a columnar database are efficient compression and fast query processing. By organizing data by column and employing specialized query execution strategies, columnar databases can handle large analytical workloads and complex queries with faster query response times and better overall performance.
Related resources
Learn more about choosing the right database for your analytics workloads:
-
- Types of Databases
- What Is Big Data Analytics?
- Comparing Document Databases and Relational Databases
- NoSQL Comparison: MongoDB vs. DynamoDB vs. Couchbase
- Couchbase Announces New Capella Columnar Service
- Comparing Couchbase Capella vs. Cosmos DB
- Database vs. Data Warehouse: Differences, Use Cases, Examples
- Try Couchbase Capella DBaaS for Free