The concept of consolidation is simple, and applying its principles can bring immense benefit to any organization. But what does consolidation mean in the context of database technology?
Google defines consolidation as “the action or process of combining a number of things into a single more effective or coherent whole.”
When applied to databases, consolidation can mean a couple things for any given organization:
-
- Reducing the number of disparate technologies that manage data.
- Reducing unnecessary data redundancy – i.e. multiple copies of the same data.
A simple example of the problem might be a company that stores the exact same customer data in three different databases. For example, an operational database for sales management, an analytics database for business intelligence, and a caching database for faster customer logins to a corporate web app. Within each of these databases, there is data replication for failover and disaster recovery, exacerbating overall data inflation.
Tech leaders in the organization know they are creating redundancy that make things more complicated, but they choose to live with this complexity and cost because they believe there is no single database that can serve all three purposes. As these concessions are made time and time again for more applications, the data footprint swells to the point where many organizations find themselves paying exorbitant storage fees and losing track of how much data they even have. Welcome to the unpleasant world of data sprawl!
The pain of data sprawl
Data sprawl creates a complicated environment of loosely integrated systems that are time consuming to manage, incur high costs for storage, increase security risks, and cause a general loss of efficiency, leading many organizations to make its elimination a priority.
In fact, Google presents the following as a proper use of the word consolidation in a sentence: “a consolidation of data within an enterprise“. It’s noteworthy that Google chose to use “consolidation of data” as the example, emphasizing that it is a common goal for many organizations. Why is it an attractive goal? Because there are clear benefits to database consolidation. When you reduce disparate layers of database technology in your stack, you reduce complexity because there’s less to manage and you reduce costs because your data footprint is smaller.
But with all the different systems, data formats, and access patterns in place to power enterprise applications, how does an organization reduce data sprawl while still providing the specific functionalities their apps require? Let’s explore this in more detail!
Well, how did we get here?
There are many things that cause an unsustainable proliferation of database technologies in an organization: mergers and acquisitions, legacy data retention requirements, a lack of formal corporate technology standards, and a best of breed tech culture that promotes using only the most bespoke tools for a given requirement vs. a consolidated multi-purpose tool set.
These conditions exist in many organizations, some planned, some not, but all contribute to a confusing stack of single-purpose databases and endless copies of the same data that drives up costs and ultimately slows business.
Let’s examine some of the types of databases, and their specific functionality, that are typically required to power modern applications for an enterprise.
Types of databases
Relational databases
Relational databases natively support SQL with joins, aggregations and ACID transactions, the mainstays of operational applications and systems. They excel at storing highly structured data and providing strong consistency, but these characteristics bring rigidity because the data model is fixed and defined by a static schema. So in order to change the data model, developers have to modify the schema, which can slow development. In addition, relational databases are not built for massive scale, and so performance tends to degrade as applications grow. Because of their ubiquity in legacy operational applications, organizations often have many relational databases in their ecosystem to serve functions such as transaction processing.
NoSQL document databases
NoSQL document databases are schemaless, and they store data as JSON documents instead of tables of rows and columns. NoSQL document databases are also designed for distributed data processing, where a single database spans several nodes to make up a cluster of data processing. This makes NoSQL databases inherently scalable by allowing data to be processed across a distributed architecture — if a node goes down, the others pick up the slack.
Additionally, JSON is the de facto standard for consuming and producing data for mobile apps, making it ideal for development without relational rigidity, because JSON defers to the apps and services, and thus to the developers as to how data should be modeled. If your app development follows the domain model, and you want the flexibility to evolve apps without the overhead of relational rigidity, a NoSQL JSON document database is a great option. Many organizations adopt NoSQL document databases as a means to scale their applications.
This article provides more details on the differences between relational and NoSQL databases.
Key-value / In Memory databases
A key-value database stores data as a collection of key-value pairs where each unique key is associated with a specific data value. The data format is simple to facilitate speed, and many key-value databases also run cached in-memory to maximize performance. The speed and efficiency of key-value databases make them a good choice for simple data storage and retrieval needs when the focus is on high performance, and many organizations add a key-value database to their app tech stack to provide a faster experience for users.
Full-text search databases
A full-text search database uses a search index to examine all of the text in stored documents to match search criteria (i.e., text specified by a user). Full-text search typically focuses on long form text fields in documents such as descriptions, abstracts or commentary using indexes that are pre-organized to make retrieval faster than traditional field-based database scanning. Many organizations add a full-text search database to their application tech stack to provide search features and functionality.
Vector search databases
Vector search databases leverage nearest neighbor algorithms to retrieve the records that match most closely to a given search criteria. In a vector search database, text, images, audio, and video are converted to mathematical representations called vectors, which are indexed and used for semantic searches. As such, a vector search finds related information based on the meaning of the search query, not just the words and phrases entered, making it the best option for presenting relevant information that connects with users.
Vector search also makes output from generative AI more accurate and personal by enabling Retrieval Augmented Generation (RAG), where supplemental data is passed along with prompts to provide better precision and context for LLM responses. Because of the expectation for AI capabilities in modern apps, many organizations add a vector search database to their app tech stack to power semantic search and generative AI-based features and functionality.
Columnar analytics databases
A columnar analytics database is designed for speedy retrieval of results from complex analytic queries. Unlike traditional row-based databases that store and retrieve data in rows, columnar databases organize data vertically, grouping and storing values of each column together. This architecture enhances data compression and minimizes I/O operations, resulting in faster query performance and improved data analytics. Columnar databases are especially suitable for analytical workloads that involve complex queries and aggregations over large datasets. They excel in scenarios where read-heavy operations, such as reporting and data analysis, are more frequent than write operations. Many organizations add a columnar analytics database to their application tech stack to power business intelligence and data analytics applications.
Time series databases
A time series database stores and processes data in associated pairs of time and value. Time series data is common to IoT applications, where sensors and meters record readings at regular time intervals and send the information to the database. The complexity of time series data comes in processing the data appropriately even when readings may not come in a linear time-based sequence. For example, in distributed environments with many IoT devices in operation, readings may be written to the database out of chronological order, and the time series functionality of the database reconciles this to maintain the consistency and accuracy of the data. Many organizations add a time series database to their application tech stack to enable IoT applications.
Graph databases
A graph database is built to store and manage interconnected data, representing data as nodes (entities) and edges (relationships), forming a graph structure. Each node stores attributes, while edges define connections and properties between nodes. This design makes graph databases ideal for handling complex relationships that involve connections, such as social networks, recommendation systems, and knowledge graphs. Unlike traditional relational databases, graph databases excel at traversing relationships to enable faster and more intuitive querying, and more accurate results. In addition, graph databases are ideal for Retrieval Augmented Generation (RAG), where data relationships can be passed along with prompts to provide better precision and context for generative AI/LLM responses. Many organizations add a graph database to their application tech stack to help power AI features in their applications.
Embedded databases
An embedded database is a self-contained database system integrated directly into an application codebase, eliminating the need for a separate database server. Embedded data processing provides faster data access, and eliminates dependencies on the internet for data access. Embedded databases are commonly used in mobile and IoT apps where intermittent or prolonged lack of network connectivity is expected, such as for field service or other use cases that regularly operate out of range of networks. A critical component of an embedded database is the ability to synchronize data to centralized databases, as well as to other embedded database clients, which is important for maintaining data integrity and consistency.
Polyglot persistence is not the approach
Looking at the list of different database types, and the specific access patterns that they enable, it’s easy to see how an organization would adopt multiple databases.
Suppose a company has an ecommerce web application. For managing the inventories and powering transactions they might start with a relational database. But because relational databases can’t scale, they might add an in-memory key-value caching database to speed up performance. As the app grows, they might want to deploy a distributed architecture in the cloud for scale, and so add a NoSQL document database. Then to power search in the app they might add a search database. And as they look to leverage AI for making compelling offers and recommendations to app users, they might adopt a vector search database and a graph database. Then as they roll out the mobile version of the app they might adopt an embedded database. And finally to analyze their customer data, they might add a columnar analytics database. This approach is known as polyglot persistence which TechTarget defines as:
..a conceptual term that refers to the use of different data storage approaches and technologies to support the unique storage requirements of various data types that live within enterprise applications.
While the approach makes sense on paper — use the best tool for the job — when you consider the multiple layers of data processing, and the replication for failover and DR inherent in each database, you can see how the data footprint grows exponentially with every added system.
The resulting environment is expensive and challenging to maintain, and can quickly get out of control if not addressed properly.
The benefits of database consolidation
While the downside of database proliferation and data sprawl becomes obvious upon examination, the benefits of consolidating such an environment become just as apparent.
When you reduce disparate layers of database technology in your stack, you:
-
- Reduce complexity because there’s less to manage.
- Reduce costs because your data footprint is smaller.
- Improve efficiency because fewer data sources makes apps easier to develop and faster to evolve.
But how do you consolidate your databases without losing their critical functionality? With the right database.
Couchbase Capella: the multi-purpose database
Couchbase Capella is a modern, fully managed NoSQL DBaaS that offers JSON document flexibility, in-memory performance, enterprise-level features, and proven offline mobile and IoT capabilities — all with the lowest total cost of ownership.
Capella is multi-purpose, and as such well suited to replace polyglot persistence architectures thanks to its wide array of services and features that provide all the capabilities of single-purpose databases, combined into a single platform.
Couchbase Capella provides:
-
- Distributed JSON document storage – Capella automatically distributes data across nodes and clusters for scale, and stores data as JSON documents for development flexibility. Learn more about Capella’s distributed architecture in this article.
- Relational capabilities – Capella supports SQL including joins and aggregations, ACID transactions and schema taxonomies via scopes and collections. Read about SQL support in Capella here.
- Key-value, in memory caching – Capella caches key-value data in memory for blazing speed. Learn more about Capella key-value capabilities in the docs.
- Full-text Search – Capella provides Full-text Search capabilities out of the box to power search features for applications. Read about Capella’s Full-text Search capabilities in this article.
- Vector search – Capella includes vector search to enable semantic search and RAG for AI. Read more about vector search in Capella here.
- Columnar analytics – Capella provides a columnar store and extensive data integration with the Capella DBaaS and other databases via Kafka, allowing for real-time operational analytics without ETL. Learn more about the Capella columnar service in this blog.
- Time series – Capella supports time-series data for IoT applications. To learn more about Capella’s time series support, read this blog.
- Graph traversal – Support for graph traversal to understand entity relationships and provide more context for AI prompts. This blog provides details on Couchbase graph traversal capabilities.
- Embedded mobile database – Capella App Services includes an embedded database for mobile and IoT apps that runs on-device, eliminating internet dependencies. Built-in sync to the Capella DBaaS ensures data remains consistent and accurate. Read more on Capella App Services here.
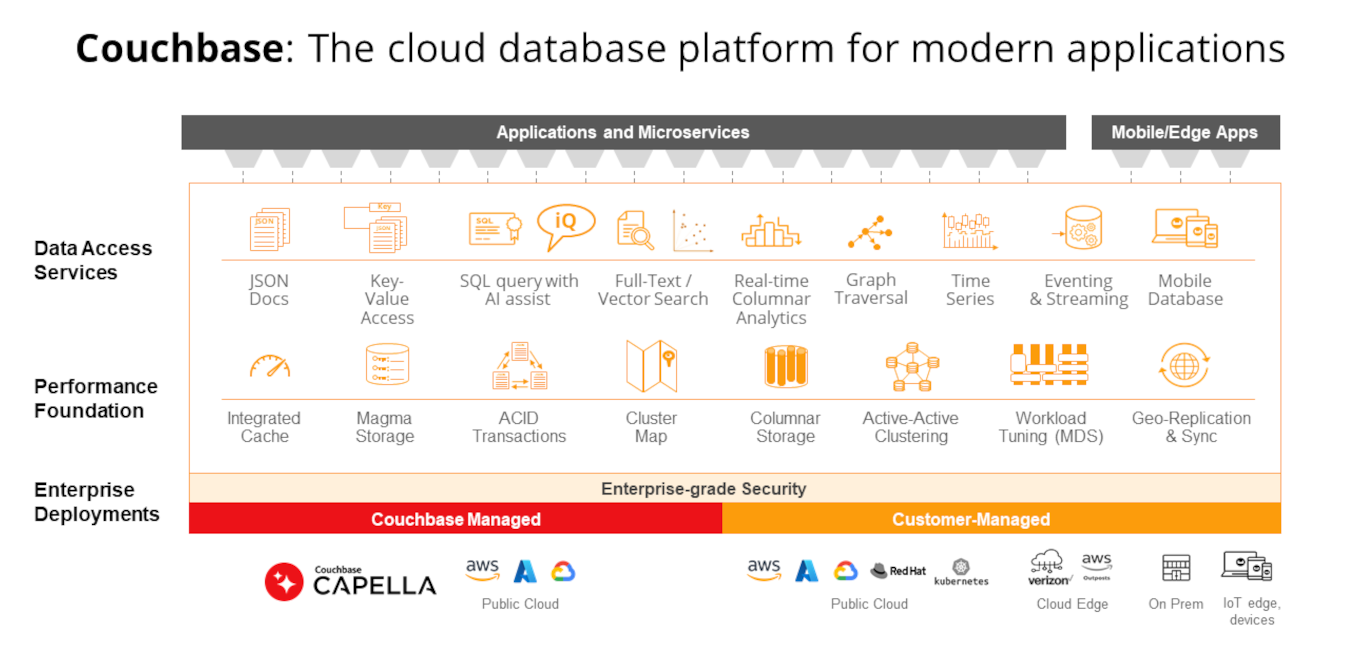
Consolidate to Couchbase Capella
By providing all of these capabilities in a single database technology, Couchbase eliminates the need for a multitude of function-specific databases, allowing you to dramatically reduce your database stack and overall data footprint, saving you time, storage, effort and money.
Viber: real-world benefits of database consolidation
Viber provides audio and video calls, messaging and other communication services through their massively popular app, and they are growing rapidly. Viber uses Couchbase to process up to 15 billion calling and messaging events per day. Couchbase updates user profiles in near-real time, delivering a responsive user experience. By replacing MongoDB™ (a NoSQL document database) and Redis (an in memory key-value database) with a Couchbase, Viber reduced the number of servers required to power their applications from 300 to 120 — a 60% reduction with massive cost savings.
Consolidate your database stack to Couchbase and start realizing the benefits in your own organization! Sign up for your free trial of Couchbase Capella here.