We are excited to announce release of Couchbase Autonomous Operator 1.2. This is landmark release marking several features requested by customers, mainly
- Automated Upgrade of Couchbase Clusters
- Integrated CouchbaseCluster Resource Validation via Adminission Controller
- Helm Support
- Public Connectivity for Couchbase Clients
- Rolling Upgrade of Kubernetes Clusters
- TLS x509 Certificate Rotation
- Unified log collection experience for stateful and stateless deployments
-
Support for Public Kubernetes Services on GKE, AKS and EKS. Kubernetes running on public cloud was already working from day 1, but with Autonomous Operator 1.2, we are supporting it in an official capacity. For this blog’s perspective, we will be using GKE to setup kubernetes cluster on GKE with version 1.12, then deploying Autonomous Operator and then eventually deploying Couchbase Cluster with Server Groups, with persistent volumes, and with x509 TLS certificates.
Overall steps that we will be doing in this blog are as follows:
-
Initialize gcloud utils
-
Deploy kubernetes cluster (v1.12+) with 2 nodes in each availability zones
-
Deploy Autonomous Operator 1.2
-
Deploy Couchbase Cluster
-
Perform Server Group Autofailover
Pre-requisites
- kubectl (gcloud components install kubectl)
- GCP account with right credentials
Initialize gcloud utils
Download gcloud sdk for the OS version of your choice from this URL.
One would need google cloud credentials to initialize the gcloud cli
|
1 2 3 |
cd google-cloud-sdk ./install.sh ./bin/gcloud init |
Deploy kubernetes cluster (v1.12) with 2 nodes in each availability zones
Deploying kubernetes cluster on GKE is fairly straightforward job. To deploy resilient kubernetes clusters, its good idea to deploy nodes in all available zones within a given region. Doing it in such way we can make use of Server Groups or Rack Zone or Availability Zone(AZ) awareness feature within Couchbase server, means if we lose entire AZ, couchbase can failover entire AZ and Application will be active, as it still has the working dataset.
|
1 |
gcloud container clusters create rd-k8s-gke --region us-east1 --machine-type n1-standard-16 --num-nodes 2 |
|
1 2 3 4 |
Details about above command K8s cluster name : rd-k8s-gke machine-type: n1-standard-16 (16 vCPUs and 60GB RAM) num-nodes/AZ : 2 |
More Machines types can be here
At this point, k8s cluster with required number of nodes should be up and running
|
1 2 3 |
$ gcloud container clusters list NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION <strong>NUM_NODES</strong> STATUS rd-k8s-gke us-east1 1.12.6-gke.10 35.229.24.36 n1-standard-16 1.12.6-gke.10 <strong>6</strong> RUNNING |
Details of the k8s cluster can be found like below
|
1 2 3 4 5 6 |
$ kubectl cluster-info Kubernetes master is running at https://55.229.24.36 GLBCDefaultBackend is running at https://55.229.24.36/api/v1/namespaces/kube-system/services/default-http-backend:http/proxy Heapster is running at https://55.229.24.36/api/v1/namespaces/kube-system/services/heapster/proxy KubeDNS is running at https://55.229.24.36/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy Metrics-server is running at https://55.229.24.36/api/v1/namespaces/kube-system/services/https:metrics-server:/proxy |
Deploy Autonomous Operator 1.2
GKE supports RBAC in order to limit permissions. Since the Couchbase Operator creates resources in our GKE cluster, we will need to grant it the permission to do so.
|
1 |
$ kubectl create clusterrolebinding cluster-admin-binding --clusterrole cluster-admin --user $(gcloud config get-value account) |
Download the appropriate package for deploying kubernetes in your environment. Untar the package and deploy the admission controller.
|
1 |
$ kubectl create -f admission.yaml |
Check the status of admission controller
|
1 2 3 |
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE couchbase-operator-admission 1 1 1 1 7s |
In order to visualize how admission controller works in sync with operator and couchbase cluster, it can be illustrated better with the following diagram
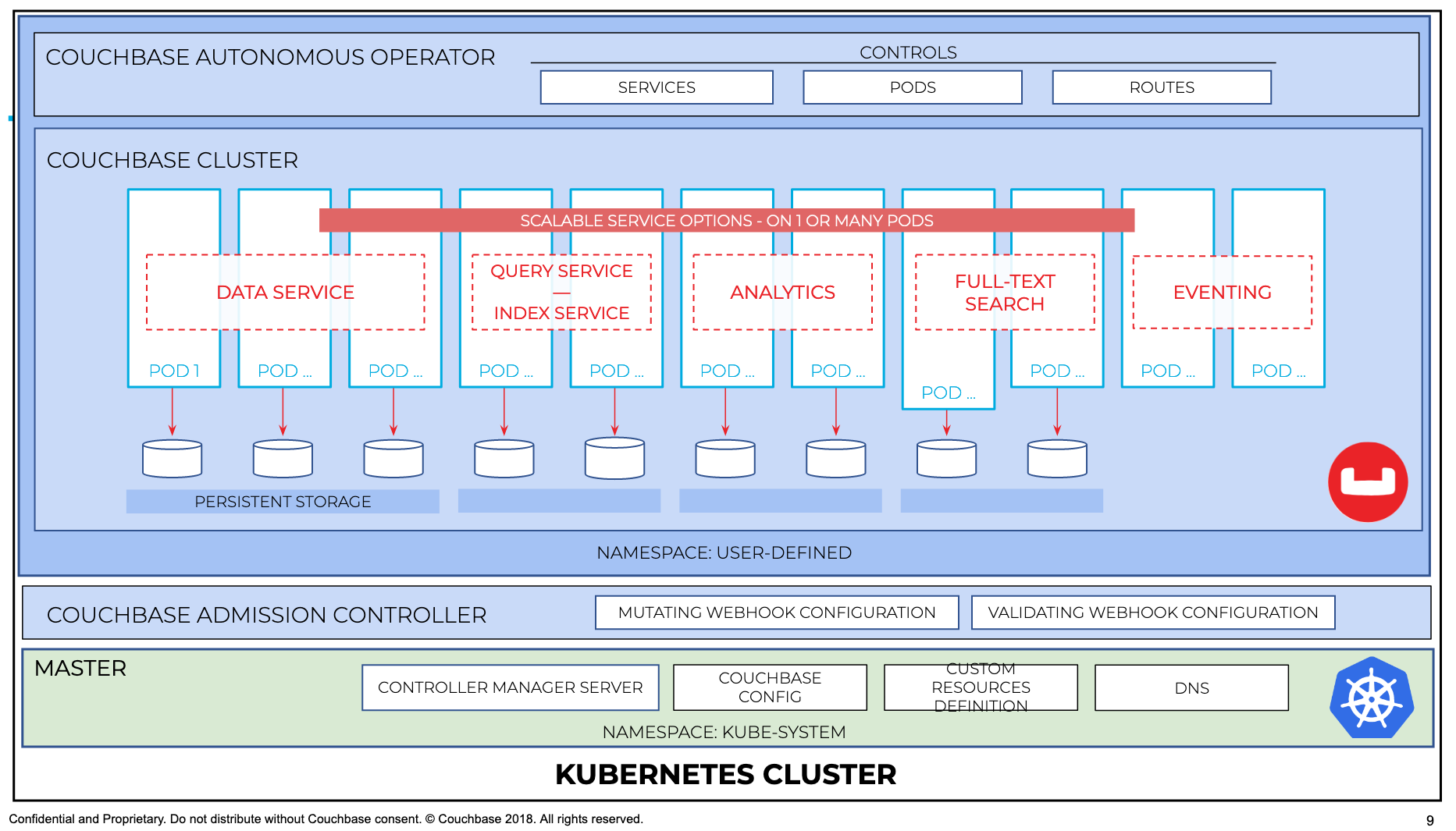
Next steps are to create crd, operator role and operator 1.2
|
1 2 3 |
$ kubectl create -f crd.yaml $ kubectl create -f operator-role.yaml $ kubectl create -f operator-deployment.yaml |
Once the operator is deployed, it gets ready and available within secs
|
1 2 3 4 |
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE couchbase-operator-admission 1 1 1 1 11m couchbase-operator 1 1 1 1 25s |
Deploy Couchbase Cluster
Couchbase cluster will be deployed with following features
-
TLS certificates
-
Server Groups (each server group in one AZ)
-
Persistent Volumes (which are AZ aware)
-
Server Group auto-failover
TLS certificates
Its fairly easy to generate tls certificates, details steps are be found here
Once deployed, tls secrets can be found with kubectl secret command like below
|
1 2 3 4 |
$ kubectl get secrets NAME TYPE DATA AGE couchbase-operator-tls Opaque 1 1d couchbase-server-tls Opaque 2 1d |
Server Groups
Setting up server groups is also straightforward, which will be discussed in the following sections when we deploy the couchbase cluster yaml file.
Persistent Volumes
Persistent Volumes provide way for a reliable way to run stateful applications. Creating them on public cloud is one click operation.
First we can check what storageclass is available for use
|
1 2 3 |
$ kubectl get storageclass NAME PROVISIONER AGE standard (default) kubernetes.io/gce-pd 1d |
All the worker nodes available in the k8s cluster should failure domain labels like below
|
1 2 3 4 5 6 7 |
$ kubectl get nodes -o yaml | grep zone failure-domain.beta.kubernetes.io/zone: us-east1-b failure-domain.beta.kubernetes.io/zone: us-east1-b failure-domain.beta.kubernetes.io/zone: us-east1-d failure-domain.beta.kubernetes.io/zone: us-east1-d failure-domain.beta.kubernetes.io/zone: us-east1-c failure-domain.beta.kubernetes.io/zone: us-east1-c |
NOTE: I don’t have to add any failure domain labels, GKE added automatically.
Create PV for each AZ
|
1 |
$ kubectl apply -f svrgp-pv.yaml |
yaml file svrgp-pv.yaml, can be found here.
Create secret for accessing couchbase UI
|
1 |
$ kubectl apply -f secret.yaml |
Finally deploy couchbase cluster with TLS support, along with Server Groups(which are Az aware) and on persistent volumes (which are also AZ aware).
|
1 |
$ kubectl apply -f couchbase-persistent-tls-svrgps.yaml |
yaml file couchbase-persistent-tls-svrgps.yaml, can be found here
Give a few mins, and couchbase cluster will come up, and it should look like this
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ kubectl get pods NAME READY STATUS RESTARTS AGE cb-gke-demo-0000 1/1 Running 0 1d cb-gke-demo-0001 1/1 Running 0 1d cb-gke-demo-0002 1/1 Running 0 1d cb-gke-demo-0003 1/1 Running 0 1d cb-gke-demo-0004 1/1 Running 0 1d cb-gke-demo-0005 1/1 Running 0 1d cb-gke-demo-0006 1/1 Running 0 1d cb-gke-demo-0007 1/1 Running 0 1d couchbase-operator-6cbc476d4d-mjhx5 1/1 Running 0 1d couchbase-operator-admission-6f97998f8c-cp2mp 1/1 Running 0 1d |
Quick check on persistent volumes claims can be done like below
|
1 |
$ kubectl get pvc |
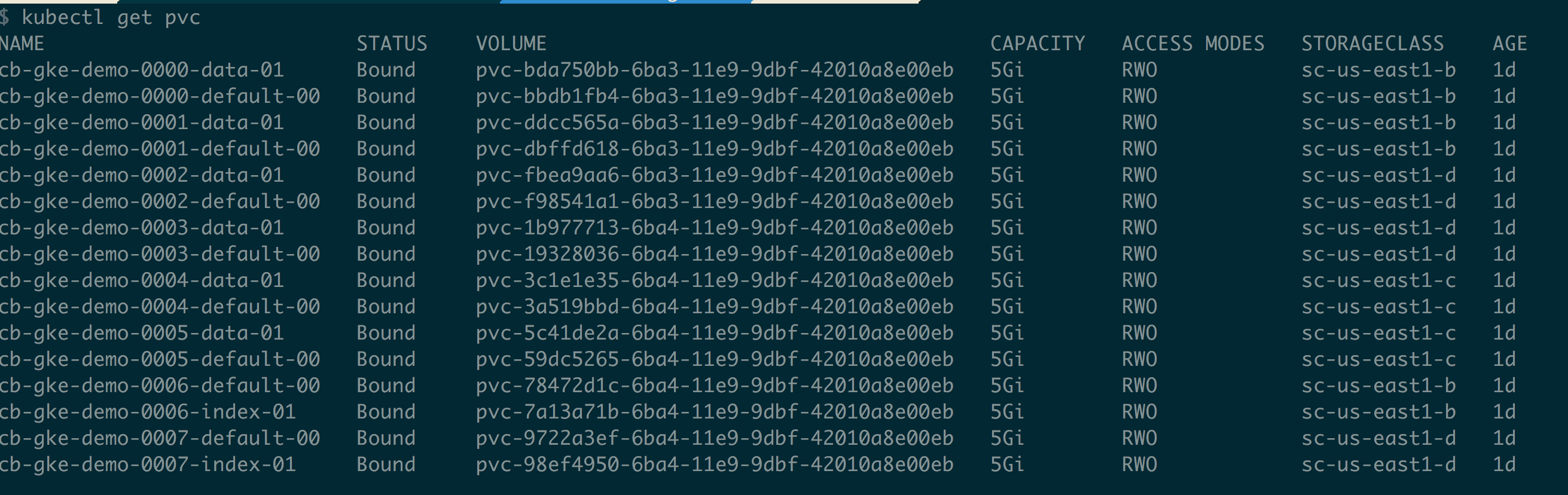
In order to access the Couchbase Cluster UI, either we can port-foward port 8091 of any pod or service itself, on local laptop, or local machine, or it can be exposed via lb.
|
1 |
$ kubectl port-forward service/cb-gke-demo-ui 8091:8091 |
port-forward any pod like below
|
1 |
$ kubectl port-forward cb-gke-demo-0002 8091:8091 |
At this point couchbase server is up and running and we have way to access it.
Perform Server Group Autofailover
Server Group auto-failover
When a couchbase cluster node fails, then it can auto-failover and without any user intervention ALL the working set is available, no user intervention is needed and Application won’t see downtime.
If Couchbase cluster is setup to be Server Group(SG) or AZ or Rack Zone(RZ) aware, then even if we lose entire SG then entire server groups fails over and working set is available, no user intervention is needed and Application won’t see downtime.
In order to have Disaster Recovery, XDCR can be used to replicate Couchbase data to other Couchbase Cluster. This helps in the event if entire source Data Center or Region is lost, Applications can cut over to Remote site and application won’t see downtime.
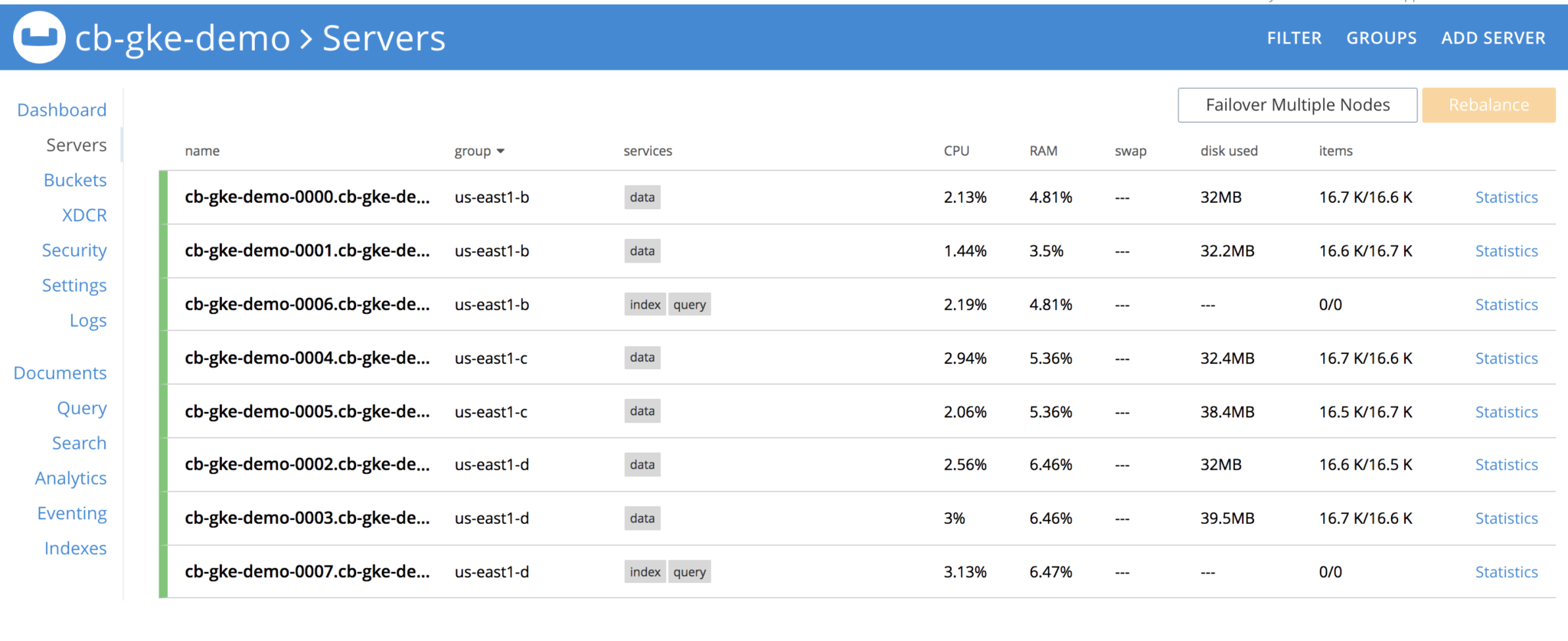
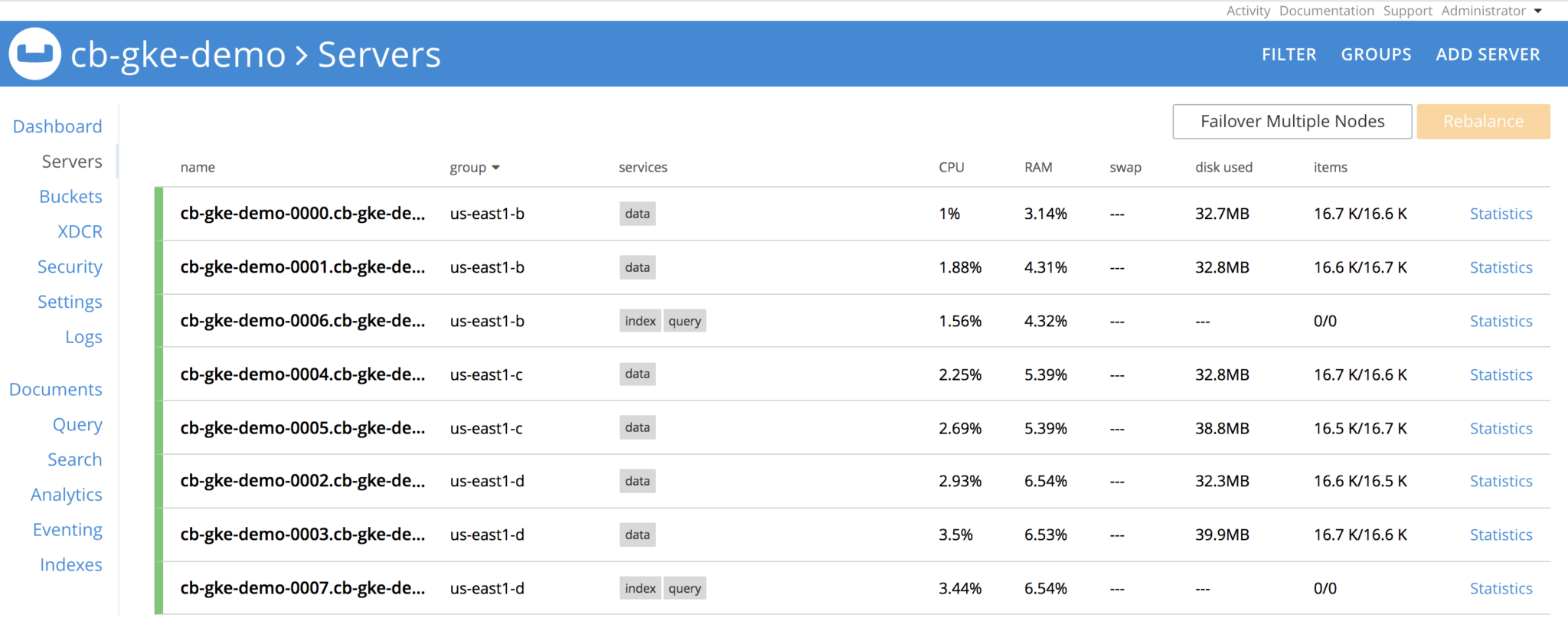
Lets take down the Server Group. Before that, lets see how the cluster looks like
Delete all pods in group us-east1-b, once the pods are deleted, Couchbase cluster will see that nodes are 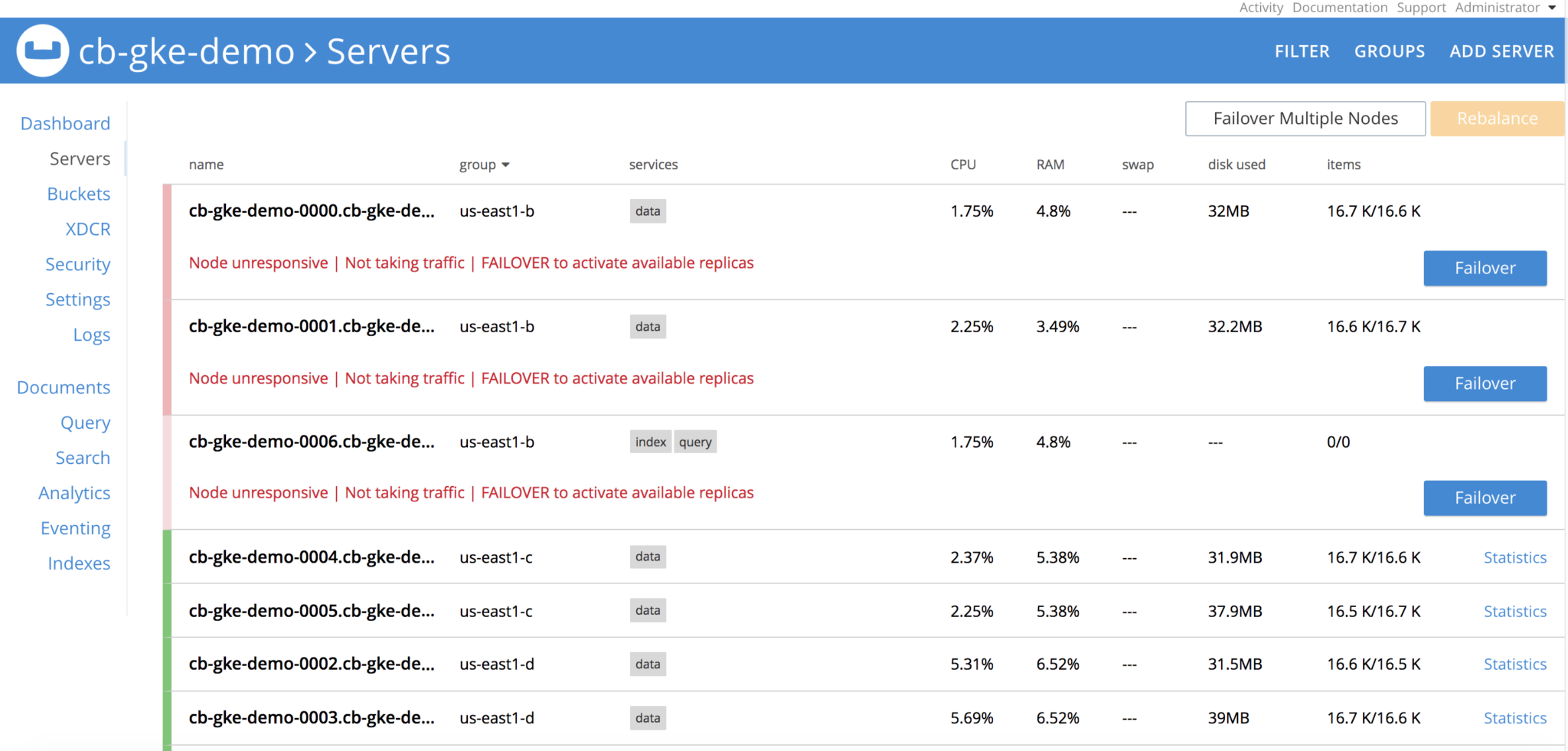
Operator is constantly watching the cluster definition and it will see that server group is lost, and it spins the 3 pods, re-establishes the claims on the PVs and performs delta-node recovery, and then eventually performs rebalance operation and cluster is healthy again. All with no user-intervention whatsoever.
After sometime, cluster is back and up and running.
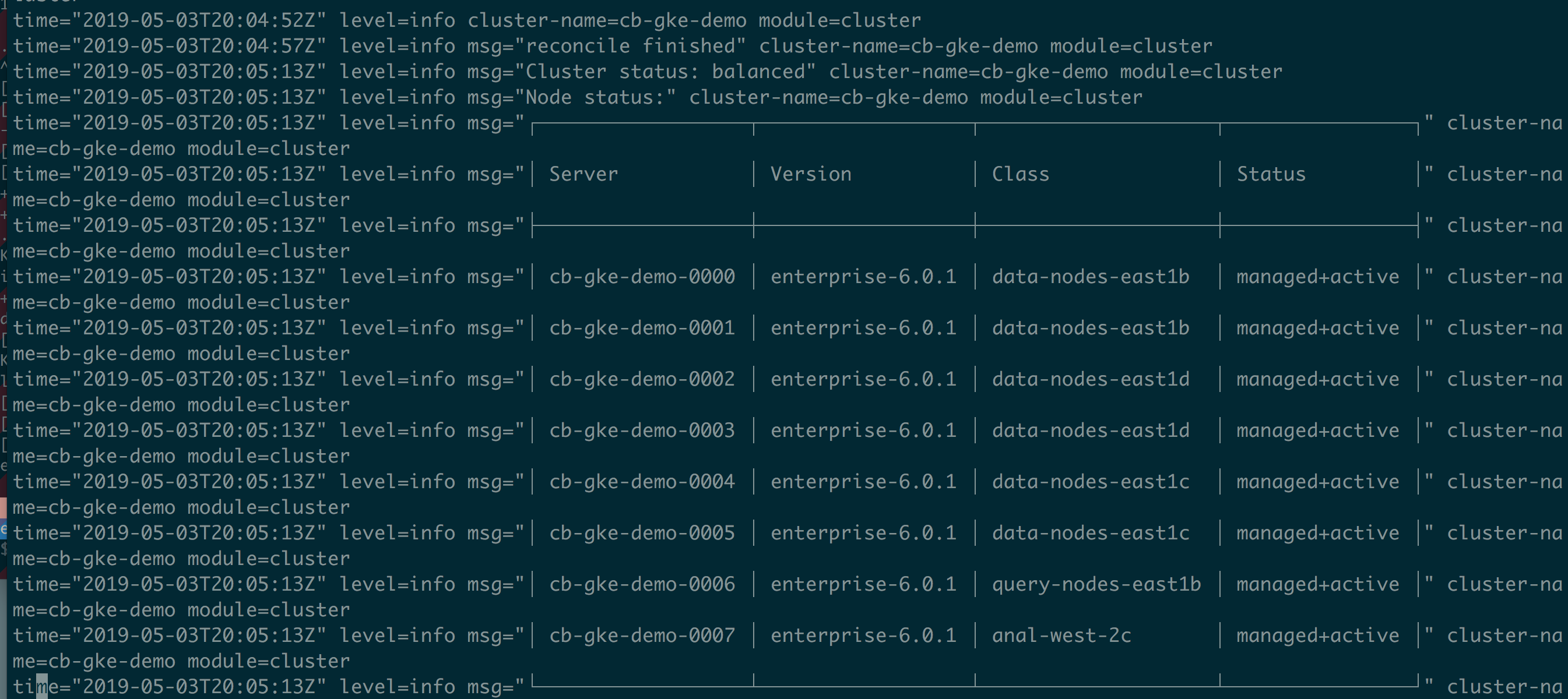
From the operator logs,
|
1 |
$ kubectl logs -f couchbase-operator-6cbc476d4d-mjhx5 |
we can see that cluster is automatically rebalanced.
Epilogue
Sustained differentiation is key to our technology. We have added quite a number of new and supportability features. With all these enterprise grade supportability features, they enable end user to find the issues faster and help operationalize the Couchbase Operator in their environments in a efficient faster and way. We are very excited about the release, feel free to give a try!
References:
https://docs.couchbase.com/operator/1.2/whats-new.html
https://www.couchbase.com/downloads
https://docs.couchbase.com/server/6.0/manage/manage-groups/manage-groups.html
K8s Autonomous Operator Book from @AnilKumar
https://info.couchbase.com/rs/302-GJY-034/images/Kubernetes_ebook.pdf
https://docs.couchbase.com/operator/1.2/tls.html
All yaml files and help files used for this blog can be found here