As enterprises look to deploy production-ready AI agent applications, Large Language Model (LLM) observability has emerged as a critical requirement for ensuring both performance and trust. Organizations need visibility into how agents interact with data, make decisions, and retrieve information to maintain reliability, security, and compliance. Without proper observability, enterprises risk deploying models that produce inconsistent, inaccurate, or biased results, leading to poor user experiences and operational inefficiencies. The new partnership between Couchbase and Arize AI plays a vital role in bringing robust monitoring, evaluation, and optimization capabilities to AI-driven applications.
The integration of Couchbase and Arize AI delivers a powerful solution for building and monitoring Retrieval Augmented Generation (RAG) and agent applications at scale. By leveraging Couchbase’s high-performance vector database and the Arize AI observability platform and enhanced monitoring capabilities, enterprises can confidently build, deploy and optimize Agentic RAG solutions in production.
In this blog, we’ll walk through creating an Agentic RAG QA chatbot using LangGraph and the Couchbase Agent Catalog component of the recently announced Capella AI services (in preview), and evaluating and optimizing its performance with Arize AI. This is a tangible example of how Couchbase and Arize AI enable developers to enhance retrieval workflows, improve response accuracy, and monitor LLM-powered interactions in real time.
The Value of the Couchbase and Arize AI Partnership
By joining forces, Couchbase and Arize AI are revolutionizing how developers build and evaluate AI agent applications. Developers can construct sophisticated agent applications by leveraging Couchbase Capella as a single data platform for LLM caching, long-term and short-term agent memory, vector embedding use cases, analytics, and operational workloads along with their favorite agent development framework for orchestrating agent workflows.
Couchbase Agent Catalog further enhances this system by providing a centralized store for multi-agent workflows within an organization that allows for storage, management, and discovery of various agent tools, prompt versioning, and LLM trace debugging.
To ensure high reliability and transparency, Arize AI provides critical observability features, including:
-
- Tracing Agent Function Calls: Arize enables detailed monitoring of the agent’s function calls, including retrieval steps and LLM interactions, to track how responses are generated.
- Dataset Benchmarking: Developers can create a structured dataset to evaluate and compare agent performance over time.
- Performance Evaluation with LLM as a Judge: Using built-in evaluators, Arize leverages LLMs to assess response accuracy, relevance, and overall agent effectiveness.
- Experimenting with Retrieval Strategies: By adjusting chunk sizes, overlaps, and the number of retrieved documents (K-value), developers can analyze their impact on agent performance.
- Comparative Analysis in Arize: The platform allows side-by-side comparisons of different retrieval strategies, helping teams determine the optimal configuration for their agent.
The Importance of LLM Observability
To ensure that AI applications perform well in production, enterprises need a robust evaluation framework. Observability tools like Arize AI allow developers to:
-
- Assess LLM outputs based on factors such as relevance, hallucination rates, and latency
- Conduct systematic evaluations to measure the impact of prompt changes, retrieval modifications, and parameter adjustments
- Curate comprehensive datasets to benchmark performance across different use cases
- Automate evaluation processes within CI/CD pipelines, ensuring consistent application reliability
Using an LLM as a judge, Arize AI allows developers to measure agent effectiveness using pre-tested evaluators, multi-level custom evaluation techniques, and large-scale performance benchmarking. By running thousands of evaluations, teams can iterate quickly and refine LLM prompts, retrieval methods, and agent workflows to improve overall application quality.
Building an Agentic RAG QA Chatbot
Agentic RAG combines the power of traditional retrieval-augmented generation with intelligent decision-making. In this implementation, we enable an LLM to dynamically decide whether retrieval is necessary based on the query context.
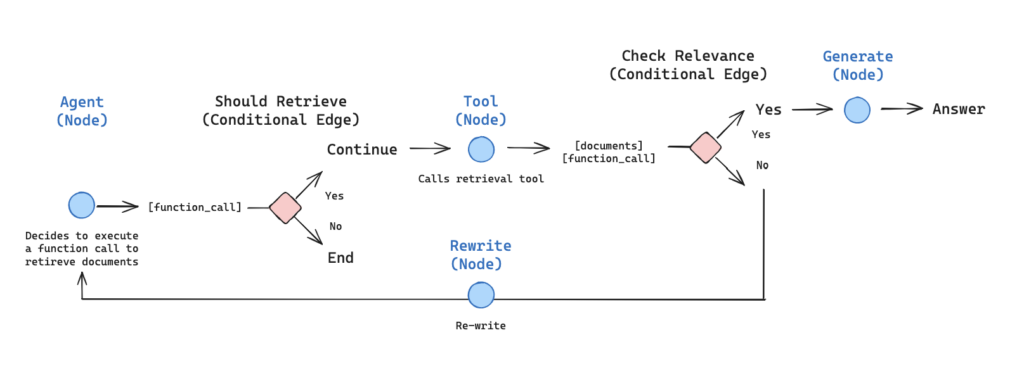
Illustration depicting the agent workflow from Langgraph’s agentic RAG example.
Step-by-Step Implementation
The rest of this blog is based on the accompanying tutorial notebook. Before building and deploying an observable AI agent, you’ll need to configure your development environment.
Prerequisites:
-
- To follow along with this tutorial, you’ll need to sign up for Arize and get your Space, API and Developer keys. You can see the guide here. You will also need an OpenAI API key.
- You’ll need to setup your Couchbase cluster by doing the following:
- Create an account at Couchbase Cloud
- Create a free cluster with the Data, Index, and Search services enabled*
- Create cluster access credentials
- Allow access to the cluster from your local machine
- Create a bucket to store your documents
- Create a search index
- Create tools and prompts required by agents using Couchbase Agent Catalog (for installation and more instructions, explore documentation here)
*The Search Service will be used to perform Semantic Search later when we use Agent catalog.
1) Create an Agentic RAG chatbot using LangGraph, Couchbase as the vector store and Agent Catalog to manage AI agents
Setting Up Dependencies
|
1 2 3 4 |
%pip install -qU langchain-openai langchain-community langchain langgraph langgraph.prebuilt openai langchain-couchbase agentc langchain-huggingface langchain_core %pip install -qq "arize-phoenix[evals]>=7.0.0" "arize-otel>=0.7.0" "openinference-instrumentation-openai>=0.1.18" "openinference-instrumentation-langchain>=0.1.29" |
Connecting to Couchbase
We’ll use Couchbase as our vector store. Here’s how to set up the connection:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
from datetime import timedelta from couchbase.auth import PasswordAuthenticator from couchbase.cluster import Cluster from couchbase.options import ClusterOptions from langchain_couchbase.vectorstores import CouchbaseVectorStore from langchain_huggingface import HuggingFaceEmbeddings # Cluster settings CB_CONN_STRING = "your-connection-string" CB_USERNAME = "your-username" CB_PASSWORD = "your-password" BUCKET_NAME = "your-bucket-name" SCOPE_NAME = "your-scope-name" COLLECTION_NAME = "your-collection-name" SEARCH_INDEX_NAME = "your-search-index-name" # Connect to couchbase cluster auth = PasswordAuthenticator(CB_USERNAME, CB_PASSWORD) options = ClusterOptions(auth) options.apply_profile("wan_development") cluster = Cluster(CB_CONN_STRING, options) cluster.wait_until_ready(timedelta(seconds=5)) # Initialize vector store embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L12-v2") vector_store = CouchbaseVectorStore( cluster=cluster, bucket_name=BUCKET_NAME, scope_name=SCOPE_NAME, collection_name=COLLECTION_NAME, embedding=embeddings, index_name=SEARCH_INDEX_NAME, ) |
Document Ingestion
We’ll create a helper function to load and index documents with configurable chunking parameters:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
from langchain_community.document_loaders import WebBaseLoader from langchain_text_splitters import RecursiveCharacterTextSplitter def reset_vector_store(vector_store, chunk_size=1024, chunk_overlap=20): try: # Delete existing documents results = vector_store.similarity_search( k=1000, query="", search_options={ "query": {"field": "metadata.source", "match": "lilian_weng_blog"} }, ) if results: deleted_ids = [result.id for result in results] vector_store.delete(ids=deleted_ids) # Load documents from URLs urls = [ "https://lilianweng.github.io/posts/2024-07-07-hallucination/", "https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/", "https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/", ] docs = [WebBaseLoader(url).load() for url in urls] docs_list = [item for sublist in docs for item in sublist] # Use RecursiveCharacterTextSplitter with configurable parameters text_splitter = RecursiveCharacterTextSplitter( chunk_size=chunk_size, chunk_overlap=chunk_overlap, separators=["\n\n", "\n", " ", ""], ) doc_splits = text_splitter.split_documents(docs_list) # Add metadata to documents for doc in doc_splits: doc.metadata["source"] = "lilian_weng_blog" # Add documents to vector store vector_store.add_documents(doc_splits) return vector_store except ValueError as e: print(f"Error: {e}") # Initialize with default settings reset_vector_store(vector_store) |
Setting Up the Retriever Tool
Fetch our retriever tool from the Agent Catalog using the agentc provider. In the future, when more tools (and/or prompts) are required and the application grows more complex, Agent Catalog SDK and CLI can be used to automatically fetch the tools based on the use case (semantic search) or by name.
For instructions on how this tool was created and more capabilities of Agent catalog, please refer to the documentation here.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import agentc.langchain import agentc from langchain_core.tools import tool provider = agentc.Provider( decorator=lambda t: tool(t.func), secrets={"CB_USERNAME": CB_USERNAME, "CB_PASSWORD": CB_PASSWORD, "CB_CONN_STRING": CB_CONN_STRING}) # Get the retriever tool from Agent Catalog retriever_tool = provider.get_item(name="retriever_tool", item_type="tool") tools = retriever_tool |
Defining the Agent State
We will define a graph of agents to help all involved agents communicate with each other better. Agents communicate through a state object that is passed around to each node and modified with output from that node.
Our state will be a list of messages and each node in our graph will append to it:
|
1 2 3 4 5 6 7 8 |
from typing import Annotated, Sequence, TypedDict from langchain_core.messages import BaseMessage from langgraph.graph.message import add_messages class AgentState(TypedDict): # The add_messages function defines how an update should be processed # Default is to replace. add_messages says "append" messages: Annotated[Sequence[BaseMessage], add_messages] |
Creating Agent Nodes
We’ll define the core components of our agent pipeline:
Nodes: Relevance Checking Function, Query Rewriter, Main Agent, Response Generation
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 |
from typing import Annotated, Literal, Sequence, TypedDict from langchain import hub from langchain_core.messages import BaseMessage, HumanMessage from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import PromptTemplate from langchain_core.pydantic_v1 import BaseModel, Field from langchain_openai import ChatOpenAI from langgraph.prebuilt import tools_condition ### Relevance Checking Function def grade_documents(state) -> Literal["generate", "rewrite"]: """ Determines whether the retrieved documents are relevant to the question. """ print("---CHECK RELEVANCE---") # Data model class grade(BaseModel): """Binary score for relevance check.""" binary_score: str = Field(description="Relevance score 'yes' or 'no'") # LLM model = ChatOpenAI(temperature=0, model="gpt-4o", streaming=True) llm_with_tool = model.with_structured_output(grade) #fetch a prompt from Agent Catalog grade_documents_prompt = PromptTemplate( template=provider.get_item(name="grade_documents", item_type="prompt").prompt.render(), input_variables=["context", "question"], ) # Chain chain = grade_documents_prompt | llm_with_tool messages = state["messages"] last_message = messages[-1] question = messages[0].content docs = last_message.content scored_result = chain.invoke({"question": question, "context": docs}) score = scored_result.binary_score if score == "yes": print("---DECISION: DOCS RELEVANT---") return "generate" else: print("---DECISION: DOCS NOT RELEVANT---") print(score) return "rewrite" ### Main Agent Node def agent(state): """ Invokes the agent model to generate a response or use tools. """ print("---CALL AGENT---") messages = state["messages"] model = ChatOpenAI(temperature=0, streaming=True, model="gpt-4-turbo") model = model.bind_tools(tools) response = model.invoke(messages) return {"messages": [response]} ### Query Rewriting Node def rewrite(state): """ Transform the query to produce a better question. """ print("---TRANSFORM QUERY---") messages = state["messages"] question = messages[0].content msg = [ HumanMessage( content=f""" \n Look at the input and try to reason about the underlying semantic intent / meaning. \n Here is the initial question: \n ------- \n {question} \n ------- \n Formulate an improved question: """, ) ] model = ChatOpenAI(temperature=0, model="gpt-4-0125-preview", streaming=True) response = model.invoke(msg) return {"messages": [response]} ### Response Generation Node def generate(state): """ Generate answer using retrieved documents """ print("---GENERATE---") messages = state["messages"] question = messages[0].content last_message = messages[-1] docs = last_message.content # Prompt prompt = hub.pull("rlm/rag-prompt") llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0, streaming=True) rag_chain = prompt | llm | StrOutputParser() # Run response = rag_chain.invoke({"context": docs, "question": question}) return {"messages": [response]} |
Building the Agent Graph
Now we’ll connect the nodes into a coherent workflow:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
from langgraph.graph import END, StateGraph, START from langgraph.prebuilt import ToolNode # Define a new graph workflow = StateGraph(AgentState) # Define the nodes workflow.add_node("agent", agent) retrieve = ToolNode(retriever_tool) workflow.add_node("retrieve", retrieve) workflow.add_node("rewrite", rewrite) workflow.add_node("generate", generate) # Define edges workflow.add_edge(START, "agent") # Conditional edges based on agent's decision workflow.add_conditional_edges( "agent", tools_condition, { "tools": "retrieve", END: END, }, ) # Conditional edges after retrieval based on document relevance workflow.add_conditional_edges( "retrieve", grade_documents, ) workflow.add_edge("generate", END) workflow.add_edge("rewrite", "agent") # Compile the graph graph = workflow.compile() |
Visualizing the Agent Graph
Let’s visualize our workflow to better understand it:
|
1 2 3 4 5 6 7 |
from IPython.display import Image, display try: display(Image(graph.get_graph(xray=True).draw_mermaid_png())) except Exception: # This requires some extra dependencies and is optional pass |
2) Trace the agent’s function calls using Arize, capturing retrieval queries, LLM responses, and tool usage
Arize provides comprehensive observability for our agent system. Let’s set up tracing:
|
1 2 3 4 5 6 7 8 9 10 11 |
from arize.otel import register # Setup tracer provider tracer_provider = register( space_id = SPACE_ID, api_key = API_KEY, project_name = "langgraph-agentic-rag", ) # Import the automatic instrumentor from OpenInference from openinference.instrumentation.langchain import LangChainInstrumentor # Instrument LangChain LangChainInstrumentor().instrument(tracer_provider=tracer_provider) |
Now let’s run the agent to see how it works:
|
1 2 3 4 5 6 7 8 9 10 |
import pprint inputs = { "messages": [ ("user", "What does Lilian Weng say about the types of adversarial attacks on LLMs?"), ] } for output in graph.stream(inputs): for key, value in output.items(): pprint.pprint(f"Output from node '{key}':") pprint.pprint(value, indent=2, width=80, depth=None) |
This will execute our agent graph and output detailed information for each node as it processes the query. In Arize, you’ll be able to see a trace visualization showing the execution flow, latency, and details of each function call.
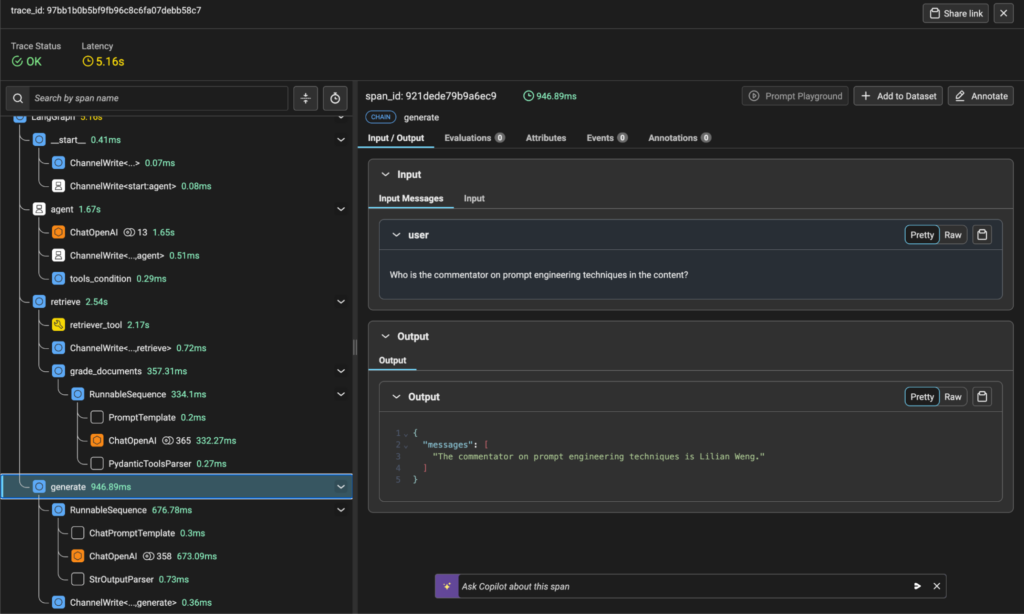
Tracing Visualization from Arize Platform
3) Benchmark performance by generating a dataset with queries and expected responses
To systematically evaluate our system, we need a benchmark dataset:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import pandas as pd from langchain_openai import ChatOpenAI # Define a template for generating questions GEN_TEMPLATE = """ You are an assistant that generates Q&A questions about the content below. The questions should involve the content, specific facts and figures,names, and elements of the story. Do not ask any questions where the answer is not in the content. Respond with one question per line. Do not include any numbering at the beginning of each line. Do not include any category headings. Generate 10 questions. Be sure there are no duplicate questions. [START CONTENT] {content} [END CONTENT] """ # Load the content you want to generate questions about content = """ Lilian Weng discusses various aspects of adversarial attacks on LLMs and prompt engineering techniques. Make sure to use Lilian Weng's name in the questions. """ # Format the template with the content formatted_template = GEN_TEMPLATE.format(content=content) # Initialize the language model model = ChatOpenAI(model="gpt-4o", max_tokens=1300) # Generate questions response = model.invoke(formatted_template) questions_content = response.content questions = questions_content.strip().split("\n") # Create a dataframe to store the questions questions_df = pd.DataFrame(questions, columns=["input"]) |
4) Evaluate Performance Using LLM as a Judge
We’ll use LLM-based evaluation to assess the quality of our agent’s responses:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
from phoenix.evals import OpenAIModel, llm_classify # Define evaluation templates RELEVANCE_EVAL_TEMPLATE = """You are comparing a reference text to a question and trying to determine if the reference text contains information relevant to answering the question. Here is the data: [BEGIN DATA] ************ [Question]: {input} ************ [Reference text]: {reference} [END DATA] Compare the Question above to the Reference text. You must determine whether the Reference text contains information that can answer the Question. Please focus on whether the very specific question can be answered by the information in the Reference text. Your response must be single word, either "relevant" or "unrelated", and should not contain any text or characters aside from that word."unrelated" means that the reference text does not contain an answer to the Question. "relevant" means the reference text contains an answer to the Question. """ CORRECTNESS_EVAL_TEMPLATE = """You are given a question, an answer and reference text. You must determine whether the given answer correctly answers the question based on the reference text. Here is the data: [BEGIN DATA] ************ [Question]: {input} ************ [Reference]: {reference} ************ [Answer]: {output} [END DATA] Your response must be a single word, either "correct" or "incorrect",and should not contain any text or characters aside from that word."correct" means that the question is correctly and fully answered by the answer. "incorrect" means that the question is not correctly or only partially answered by the answer. """ # Define rails for evaluation RELEVANCE_RAILS = ["relevant", "unrelated"] CORRECTNESS_RAILS = ["incorrect", "correct"] # Run evaluations def run_evaluators(rag_df): relevance_eval_df = llm_classify( data=rag_df, template=RELEVANCE_EVAL_TEMPLATE, model=OpenAIModel(model="gpt-4o"), rails=RELEVANCE_RAILS, provide_explanation=True, concurrency=4, ) rag_df["relevance"] = relevance_eval_df["label"] rag_df["relevance_explanation"] = relevance_eval_df["explanation"] correctness_eval_df = llm_classify( data=rag_df, template=CORRECTNESS_EVAL_TEMPLATE, model=OpenAIModel(model="gpt-4o"), rails=CORRECTNESS_RAILS, provide_explanation=True, concurrency=4, ) rag_df["correctness"] = correctness_eval_df["label"] rag_df["correctness_explanation"] = correctness_eval_df["explanation"] return rag_df # Run agent on benchmark dataset def run_rag(questions_df, k_value=2): response_df = questions_df.copy(deep=True) for index, row in response_df.iterrows(): inputs = { "messages": [ ("user", f"{row['input']}"), ] } for output in graph.stream(inputs): for key, value in output.items(): if key == "generate": response_df.loc[index, "output"] = value["messages"][-1] if key == "retrieve": response_df.loc[index, "reference"] = value["messages"][-1].content text_columns = ["input", "output", "reference"] response_df[text_columns] = response_df[text_columns].apply( lambda x: x.astype(str) ) return response_df # Run the agent on our benchmark dataset response_df = run_rag(questions_df, k_value=1) # Evaluate the results evaluated_df = run_evaluators(response_df) |
5) Experiment with Retrieval Settings
Now let’s experiment with different configurations to optimize our system:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
# Create a dataset in Arize to store our experiments from arize.experimental.datasets import ArizeDatasetsClient from uuid import uuid1 from arize.experimental.datasets.experiments.types import ( ExperimentTaskResultColumnNames, EvaluationResultColumnNames, ) from arize.experimental.datasets.utils.constants import GENERATIVE # Set up the arize client arize_client = ArizeDatasetsClient(developer_key=DEVELOPER_KEY, api_key=API_KEY) dataset_name = "rag-experiments-" + str(uuid1())[:3] dataset_id = arize_client.create_dataset( space_id=SPACE_ID, dataset_name=dataset_name, dataset_type=GENERATIVE, data=questions_df, ) dataset = arize_client.get_dataset(space_id=SPACE_ID, dataset_id=dataset_id) # Define column mappings for task and evaluation results task_cols = ExperimentTaskResultColumnNames( example_id="example_id", result="output" ) relevance_evaluator_cols = EvaluationResultColumnNames( label="relevance", explanation="relevance_explanation", ) correctness_evaluator_cols = EvaluationResultColumnNames( label="correctness", explanation="correctness_explanation", ) # Function to log experiments to Arize def log_experiment_to_arize(experiment_df, experiment_name): experiment_df["example_id"] = dataset["id"] return arize_client.log_experiment( space_id=SPACE_ID, experiment_name=experiment_name + "-" + str(uuid1())[:2], experiment_df=experiment_df, task_columns=task_cols, evaluator_columns={ "correctness": correctness_evaluator_cols, "relevance": relevance_evaluator_cols, }, dataset_name=dataset_name, ) |
Now we’ll run experiments with different configurations:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# Experiment 1: Chunks of 1024 tokens, k=2 reset_vector_store(vector_store, chunk_size=1024, chunk_overlap=20) k_2_chunk_1024_overlap_20 = run_rag(questions_df, k_value=2) k_2_chunk_1024_overlap_20 = run_evaluators(k_2_chunk_1024_overlap_20) # Experiment 2: Chunks of 1024 tokens, k=4 k_4_chunk_1024_overlap_20 = run_rag(questions_df, k_value=4) k_4_chunk_1024_overlap_20 = run_evaluators(k_4_chunk_1024_overlap_20) # Experiment 3: Smaller chunks (200 tokens), k=2 reset_vector_store(vector_store, chunk_size=200, chunk_overlap=20) k_2_chunk_200_overlap_20 = run_rag(questions_df, k_value=2) k_2_chunk_200_overlap_20 = run_evaluators(k_2_chunk_200_overlap_20) # Experiment 4: Medium chunks (500 tokens), k=2 reset_vector_store(vector_store, chunk_size=500, chunk_overlap=20) k_2_chunk_500_overlap_20 = run_rag(questions_df, k_value=2) k_2_chunk_500_overlap_20 = run_evaluators(k_2_chunk_500_overlap_20) # Log all experiments to Arize log_experiment_to_arize(k_2_chunk_1024_overlap_20, "k_2_chunk_1024_overlap_20") log_experiment_to_arize(k_4_chunk_1024_overlap_20, "k_4_chunk_1024_overlap_20") log_experiment_to_arize(k_2_chunk_200_overlap_20, "k_2_chunk_200_overlap_20") log_experiment_to_arize(k_2_chunk_500_overlap_20, "k_2_chunk_500_overlap_20") |
6) Compare Experiments in Arize
After running all the experiments, you can now view and compare them in the Arize UI. The experiments should be visible in your Arize workspace under the dataset name we created earlier.
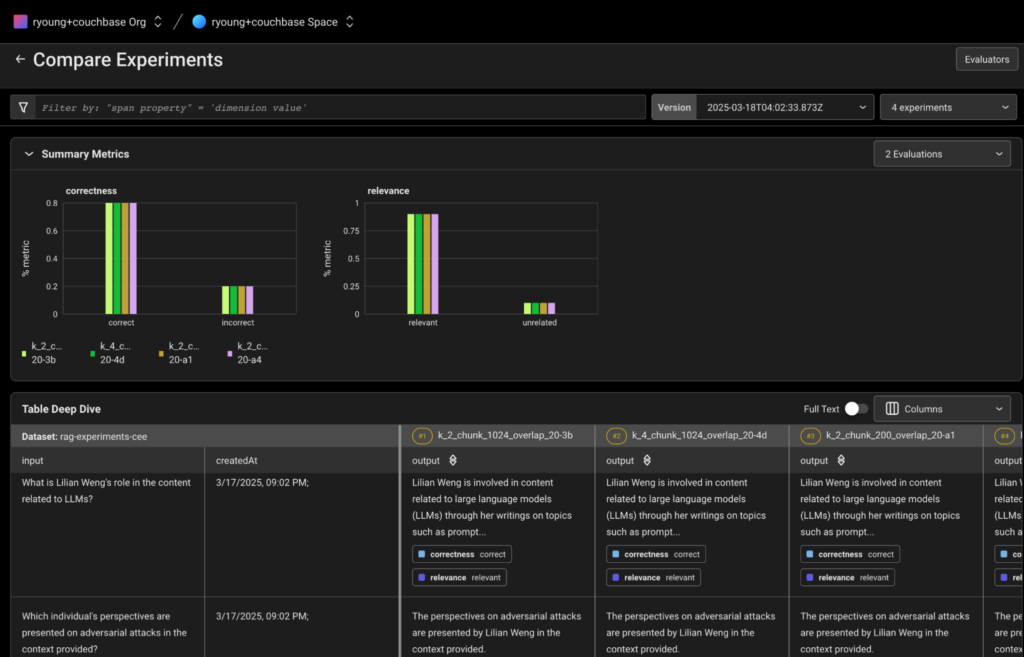
Experiments comparison view from Arize Platform
In Arize, you can:
-
- Compare the overall performance metrics between different configurations
- Analyze per-question performance to identify patterns
- Examine trace details to understand execution flow
- View relevance and correctness scores for each experiment
- See explanations for evaluation decisions
- Evaluate outputs using an LLM as a judge to score response relevance and correctness.
- Optimize retrieval settings by experimenting with chunk sizes, overlap configurations, and document retrieval limits.
- Compare and analyze experiments in Arize to determine the best-performing configurations.
Innovate with Couchbase and Arize AI
The integration of Couchbase and Arize empowers enterprises to build robust, production-ready GenAI applications with strong observability and optimization capabilities. By leveraging Agentic RAG with monitored retrieval decisions, organizations can improve accuracy, reduce hallucinations, and ensure optimal performance over time.
As enterprises continue to push the boundaries of GenAI, combining high-performance vector storage with AI observability will be key to deploying reliable and scalable applications. With Couchbase and Arize, organizations have the tools to confidently navigate the challenges of enterprise GenAI deployment.
Additional Resources
-
- Get started with Couchbase Capella developer platform for free
- Reach out to Arize AI for a demo here
- Read more posts and tutorials on Generative AI (GenAI)