
We are thrilled to announce the launch of Couchbase 7.6, a groundbreaking update poised to redefine the landscape of database technology. This latest release is a testament to our commitment to enhancing database technology, with a significant leap in AI and machine learning integration with Vector Search, LangChain integration, empowering developers to build more intelligent and responsive applications.
Key to this version is the introduction of advanced Graph Traversal capabilities, opening new avenues for complex data relationships and network analysis. Enhancing developer efficiency, and seamlessly integrating RDBMS use cases with the agility and scalability of NoSQL.
Alongside these innovations, we’ve focused on elevating the user experience with enhanced monitoring of Query and Search performance, ensuring optimal efficiency and responsiveness in real-time data operations. This release also expands our BI capabilities with enriched BI Visualization tools, enabling deeper data insights and more powerful analytics.
Couchbase 7.6 is not just an update; it’s a transformation, delivering the tools and features that developers, SREs, and data scientists need to drive the future of database technology. Here are some of them.
AI integration
Vector Search
Couchbase introduces a new Vector Search capability with release 7.6, a significant enhancement to our search capabilities that aligns with the evolving technological demands of modern applications. As data complexity grows, the need for advanced search mechanisms becomes critical. Vector Search provides a solution, allowing developers to implement semantic search, enrich machine learning models, and support AI applications directly within their Couchbase environment.
With Vector search, the search goes beyond matching keywords or term frequency search. It allows the search to be based on the semantic meaning, the context in which it is used in the queries. In effect, it captures the intent of the queries, providing more relevant results even when exact keywords or terms are not present in the content.
For more information, please refer to the Couchbase documentation.
Vector Search with SQL++
You can use Couchbase’s NoSQL database capabilities to store any content, such as user profiles, historical interaction data, or content metadata. Then use a Machine Learning Model, like OpenAI, to generate the embeddings. Couchbase Vector Search can then index the embeddings and provide semantic and hybrid search.
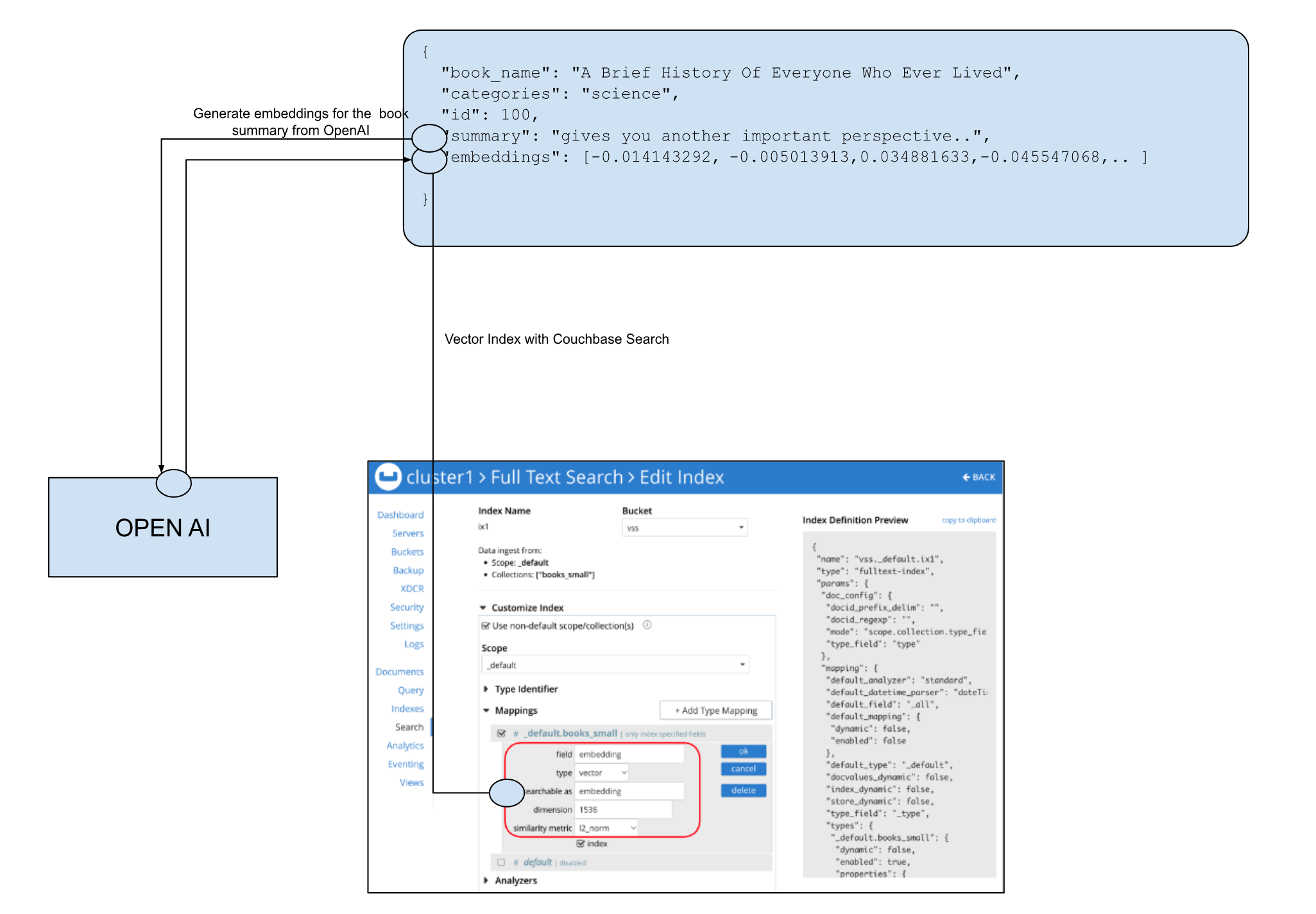
You can also use SQL++ to perform the vector search directly, and combine the search predicates with the flexibility of Couchbase SQL++ for hybrid search:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT b.book_name, b.categories, b.summaries FROM `books` AS b WHERE SEARCH(b, { /* calling Couchbase SEARCH() */ “query”: {“match_none”: {} }, “knn”: [{ “field”: “embedding”, “vector”: [ –0.014143292,–0.005013913,..], “k”: 3 }], “fields”: [“book_name”, “summaries”], “sort”: [“-_score”], “limit”: 5 }) AND b.catogories=‘Non fiction’; |
Why we do not want to add a section on how to get the embeddings for the above query? The reason is that to do so in a UDF would require UDF/JS to support CURL, something that is not supported in Capella. Users can obtain the embeddings in their application layer.
Recursive CTE
Graph Traversal
The introduction of Recursive CTE to the Couchbase SQL++ capabilities, means you can now perform complex data analysis and manipulation, particularly in the area of graph data. You can effortlessly navigate and analyze hierarchical and networked data structures, unlocking insights with unprecedented ease and efficiency. Whether it’s exploring social networks, organizational hierarchies, or interconnected systems, our new feature simplifies these tasks, making your data analysis more intuitive and productive than ever before.
Here is an example of Couchbase SQL++ Recursive CTE query to find all flights from LAX to MAD with less than two stops from this sample dataset. Note that this sample data is not based on the travel-sample, but on a simplified version of the AA routes for 2008.
| source_airport_code | destination_airport_code | airline |
| LAX | MAD | AA |
| LAX | LHR | AA |
| LHR | MAD | AA |
| LAX | OPO | AA |
| OPO | MAD | AA |
| MAD | OPO | AA |
| SQL++ Query | Results |
| /* List all routes from LAX to MAD with < 2 stops */ WITH RECURSIVE RouteCTE AS ( SELECT [r.source_airport_code, r.destination_airport_code] AS route, r.destination_airport_code AS lastStop, 1 AS depth FROM routes r WHERE r.source_airport_code = ‘LAX’ UNION ALL SELECT ARRAY_APPEND(r.route,f.destination_airport_code) AS route, f.destination_airport_code AS lastStop, r.depth + 1 AS depth FROM RouteCTE r JOIN routes f ON r.lastStop = f.source_airport_code WHERE f.destination_airport_code != ‘LAX’ AND r.depth < 3 )OPTIONS {“levels”:3} SELECT r.* FROM RouteCTE AS r WHERE r.lastStop = ‘MAD’ AND r.depth < 3; |
[ { “route”: [ “LAX”, “MAD” ] }, { “route”: [ “LAX”, “LHR”, “MAD” ] }, { “route”: [ “LAX”, “OPO”, “MAD” ] } ] |
Hierarchical Data Structure
You can also use Recursive CTE to traverse a hierarchical data structure such as an organization hierarchy.
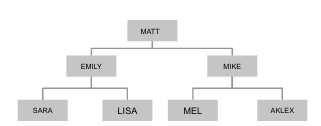
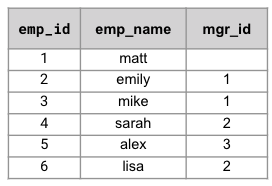
| SQL++ Query | Results |
| /* List all employees and their org hierarchy */ WITH RECURSIVE orgHier as ( SELECT [e.emp_name] hier, e.emp_id, 0 lvl FROM employee e WHERE e.manager_id is null UNION SELECT ARRAY_APPEND(o.hier, e1.emp_name) hier, e1.emp_id, o.lvl+1 lvl FROM employee e1 JOIN orgHier o ON e1.manager_id=o.emp_id ) SELECT o.* FROM orgHier o; |
[ { “emp_id”: 1, “hier”: [ “matt” ], “lvl”: 0 }, { “emp_id”: 2, “hier”: [ “matt”, “emily” ], “lvl”: 1 }, { “emp_id”: 3, “hier”: [ “matt”, “mike” ], “lvl”: 1 }, { “emp_id”: 5, “hier”: [ “matt”, “mike”, “alex” ], “lvl”: 2 }, { “emp_id”: 4, “hier”: [ “matt”, “emily”, “sarah” ], “lvl”: 2 }, { “emp_id”: 6, “hier”: [ “matt”, “emily”, “lisa” ], “lvl”: 2 } ] |
For more information, please refer to the Couchbase documentation on recursive querying.
Developer Efficiency
KV Range Scan
Key/Value (K/V) operations in Couchbase are the most efficient way to access data stored in the database. These operations use the unique key of a document to perform read, write, and update actions. However, these operations work on an individual document basis. For larger data retrieval use cases, we recommend using the Query service’s SQL++ for your applications.
However, there are cases where it is not economically feasible to set up query and indexing nodes, you now have the option to use KV Range Scan. The new feature allows your applications to iterate over all the documents based on a key range, a key prefix, or a random sampling. The APIs internally send the requests to multiple vbuckets based on the max_concurrency setting, to load balance across the data nodes. The vbucket streams are then logically merged and returned as one stream to the application.
| KV Get | KV Range Scan |
| public class CouchbaseReadHotelExample { public static void main(String[] args) { // Connect to the cluster Cluster cluster = Cluster.connect(“couchbase://localhost”, “username”, “password”); // Get a reference to the ‘travel-sample’ bucket Bucket bucket = cluster.bucket(“travel-sample”); // Access the ‘inventory’ scope and ‘hotel’ collection Scope inventoryScope = bucket.scope(“inventory”); Collection hotelCollection = inventoryScope.collection(“hotel”); String documentKey = “hotel_12345”; GetResult getResult = hotelCollection.get(documentKey); |
public static void main(String… args) { Cluster cluster = Cluster.connect(“couchbase://localhost”, “username”, “password”); Bucket bucket = cluster.bucket(“travel-sample”); Scope scope = bucket.scope(“_default”); Collection collection = scope.collection(“_default”); System.out.println(“nExample: [range-scan-range]”); // tag::rangeScanAllDocuments[] |
For more information, please refer to the Couchbase KV Operations documentation.
Query Sequential Scan
Building on the KV Range Scan functionality, Query Sequential Scan now allows you to perform all database CRUD operations using SQL++ without the need for an index. This capability allows developers to start working with the database with small datasets without having to consider the indexes required for the operations.
From the query perspective, the query plan will choose any available indexes for the query. But if none were found, then it will fall back to using Sequential Scan. The query plan will also show the use of Sequential Scan, instead of Index Scan.
| // Number of flights from SFO->LHR by airline SELECT a.name, array_count(r.schedule) flights FROM route r INNER JOIN airline a ON r.airline = a.iata WHERE r.sourceairport=‘SFO’ AND r.destinationairport=‘LHR’; |
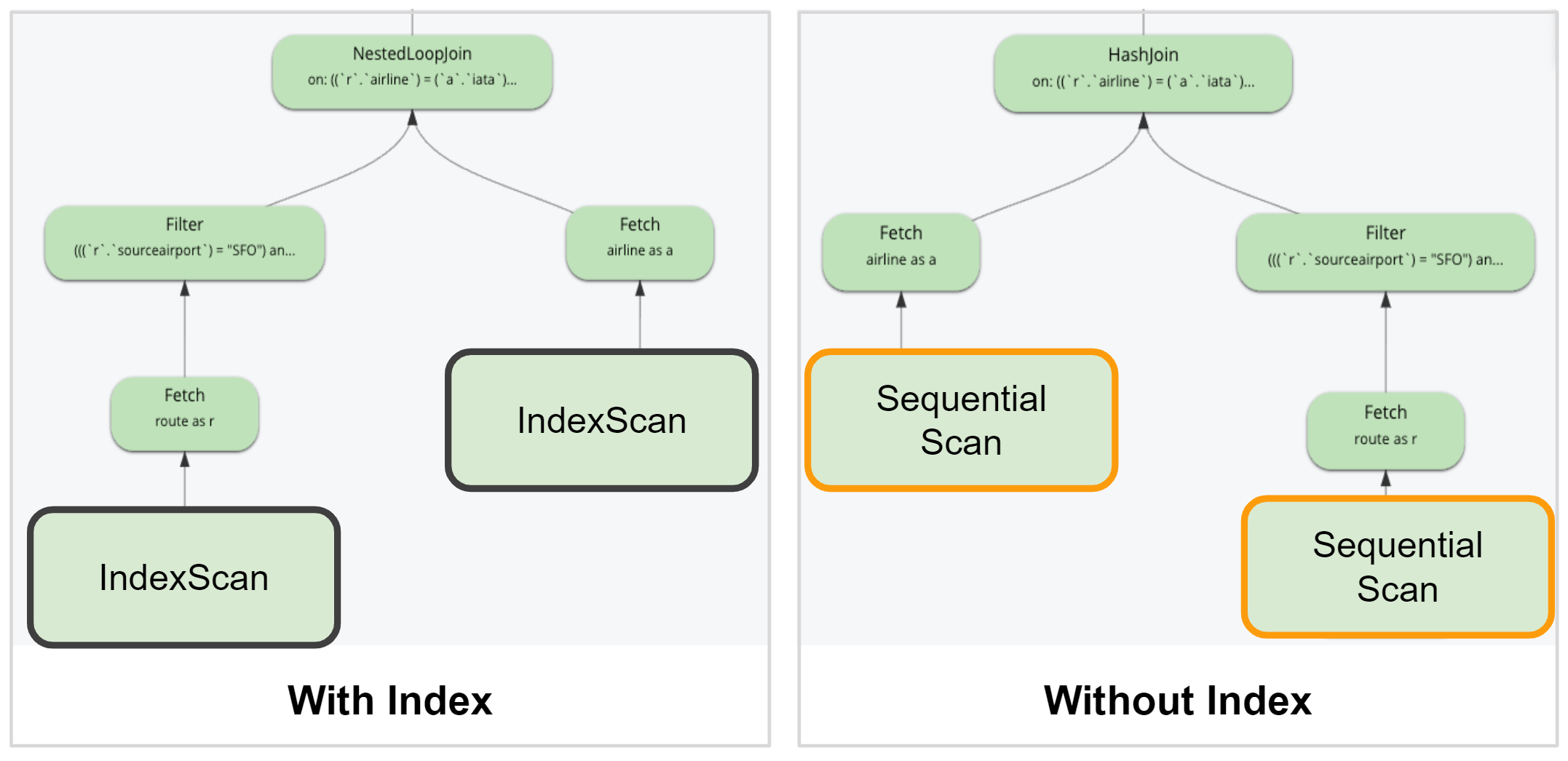
Please note that Sequential Scan is suitable for small development datasets. Indexes should still be used where query performance is a priority.
For more information, please refer to the Couchbase documentation on sequential scans.
Query Read from Replica
Read from Replica is part of the High Availability feature that is available with all Couchbase services. When using the SDK for the KV operations, a replica read allows the application to read from a data node with replica vbucket when the active copy might not be available, such as during failover.
| try { // Attempt to read from the active node GetResult result = collection.get(documentKey); System.out.println(“Document from active node: “ + result.contentAsObject()); } catch (DocumentNotFoundException activeNodeException) { System.out.println(“Active node read failed, attempting replica read…”); // If the active node read fails, attempt to read from any available replica try { GetReplicaResult replicaResult = collection.getAnyReplica(documentKey); System.out.println(“Document from replica: “ + replicaResult.contentAsObject()); } catch (Exception replicaReadException) { System.err.println(“Error fetching document from replica: “ + replicaReadException.getMessage()); } |
However this approach can’t be applied when the application uses the SDK to execute a SQL++ query. This is because the data fetch operation happens in the query service layer. In the example below, without Query Read from Replica, if there is a problem with the active data node where the query is fetching from, the query will return a timeout error to the application. Perform a retry in the application below would mean re-executing the entire query all over again.
| try { // Execute a N1QL query String statement = “SELECT * FROM QueryResult result = cluster.query(statement); // Iterate through the rows in the result set for (QueryRow row : result.rows()) { System.out.println(row); } } catch (QueryException e) { System.err.println(“Query failed: “ + e.getMessage()); } |
Couchbase 7.6 now supports Query Read from Replica. This means the query service could switch the connection to an alternative data node, if it receives a kvTimeout from the data node that it was fetching from. The logic of switching to a different data node is performed transparently within the query service, no action is required by the application.
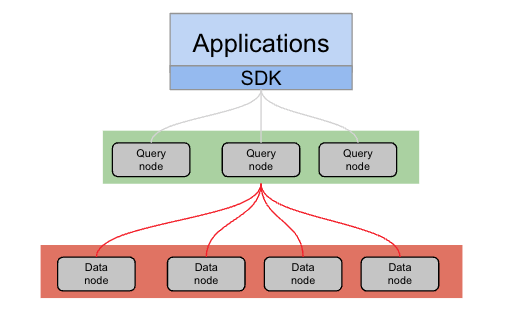
When using Query Read from Replica, applications should be mindful of potential data inconsistencies, especially in environments with heavy write activity. Continuous data replication across data nodes means that as the query service switches between nodes during the fetch operations, inconsistencies may arise. This scenario is more likely in systems experiencing frequent data updates, where the replication process could lead to slight delays in synchronization across nodes.
For this reason, the application has the option to control the Query Read from Replica. This can be enabled/disabled at the request, node or cluster level setting.
For more information, please refer to the Couchbase query settings documentation.
SQL++ Sequence
You can now use SQL++ to create a sequence object that is maintained within the Couchbase server. The sequence object generates a sequence of numeric values that are guaranteed to be unique within the database. The applications can use Couchbase SQL++ sequence to ensure a single counter to serve multiple clients.
| // Create SEQUENCE syntax
CREATE SEQUENCE [IF NOT EXISTS] <name> [IF NOT EXISTS] [ WITH <options>] |
For more information, please refer to the Couchbase sequence documentation.
Thank you for reading, we hope you enjoy these new features. More 7.6-related posts will be coming out soon.
Leave a comment
You must be logged in to post a comment.