M. David Allen is a full-stack software engineer and entrepreneur who, for more than a decade, has been working with just about every different programming language and database system he could get his hands on. David has previously worked across many industries including finance, healthcare, and government, typically focusing on large-scale data integration challenges, transitioning applied research, and new technology innovation. He holds a master’s degree from Virginia Commonwealth University, but since leaving formal education remains a permanent student of technology.

Couchbase’s History of Everything: DCP
Hiding behind an acronym DCP (database change protocol), Couchbase has a secret superpower. Most people think of databases as storage locations data in a certain moment in time. But with Database Change Protocol (DCP), a Couchbase cluster can be viewed as an ongoing stream of changes.
Essentially Couchbase can “rewind history” and replay everything that happened to the database from the beginning. In doing so, it can resolve any internal state since. In this article we’re going to cover why anyone would want to do such a crazy thing in the first place, and how we can exploit this superpower to do extra cool stuff with our documents.
What is DCP?
As a clustered database, Couchbase addresses a whole host of specialized problems that the database architecture has to solve. It has to keep multiple nodes in sync with one another, even if one temporarily hiccups or there’s a network interruption between them. It also has to be fast – fast enough to take large volumes of new documents coming in and also handle queries as they arise.
Part of the underlying design of Couchbase and how this is made possible is through stream changes in an append-only approach[1]. This means that when you change a document, Couchbase doesn’t go look up the document and modify it in place on disk. Rather, it just appends to a log of keys and values whatever the result of your mutation is, and keeps moving. In this way, writes can be made very fast, and it’s easier to coordinate multiple nodes.
If you’re familiar with relational databases, DCP’s approach is somewhat similar to the write-ahead logging you see in other software.
Why care how Couchbase does it internally?
At some level, you want your database to worry about these things for you so that you don’t have to. But in the case of DCP, we care about it because we can vampire tap into that stream of events and do all kinds of cool stuff with it, like:
Replicating data to completely different databases. Couchbase already has a number of available connectors, such as Elasticsearch. You can set up a separate Elasticsearch cluster, and have it contain a copy of all of the data from Couchbase, exposing all of your data to the features that the other database can provide to you. Keeping these two clusters would normally be a pretty hairy synchronization problem, but as the connectors are mostly fed by DCP, we can think of the DCP messages as a stream of “git commits” that continuously keep the other database up to date.
Using queue-based approaches, and integrating with other microservices. If you can write a piece of code to listen into that DCP stream, you can also filter it down to only the messages you’re interested in. Maybe it’s just when something is deleted, or only updates to a certain type of document. In either case, you can use a DCP client to filter that stream of messages, and publish extra messages onto a RabbitMQ queue, a Kafka topic, or whatever you need. This can be very useful for implementing other complex business logic. For example, imaging an insurance company that, depending on the client’s state, needs to trigger some additional logic related to compliance. Listen for mutations to client documents, filter by state, publish to the right queue, and let some other service worry about the difference between what should be done for Virginia vs. Maryland clients.
Time series/revision analysis. Each value in your database is changing through time. Some are written once and forgotten. Others may be updated frequently. For those that are updated frequently, DCP lets you treat every item as a time series. You know what the value used to be, when it changed, and what it changed to. This enables entire families of interesting downstream data analytics. Would you guess that people are doing the most rating of beers on your site on Friday and Saturday nights, or Tuesday mornings?
Essentially, DCP can be used as a kind of architectural glue; a way of getting data out of Couchbase and on to other systems, and that makes Couchbase easier and more flexible to integrate with other systems.
Finally, it should be said that Couchbase’s standard cross datacenter replication (XDCR) feature, which lets you replicate to another Couchbase cluster for backup and disaster recovery can use DCP in much the same way. So essentially, DCP is not just a “nice to have extra feature,” it’s really baked into the core, from the basics of how the storage architecture works, all the way to providing a basis for other Couchbase features like XDCR.
What if I wanted to do <exotic use case here>?
You’re going to need a DCP client, which is just a software module that lets you accept DCP messages and process them. As of this writing, there is a good one ready for Java, and one for Python as well, although it may be out of date.
A few details of DCP …
DCP can basically be thought of as a stream of mutation and deletion messages. A mutation is any time a key or the content behind it changes in any way. A deletion is just what it sounds like. There are other types of DCP messages, but let’s just keep it to deletions and mutations for now.
What’s in a DCP message? Two important items include:
- A vBucket identifier. Behind the scenes, Couchbase is just a big key/value store. Since we know it’s a distributed database, Couchbase chops up all of the keys in the database and assigns them to different “partitions,” called vBuckets. The vBucket identifier just tells the database which segment of the keyspace is changing. There’s a lot more information available on this topic if you want to go deeper, but there is a lot of configurability in Couchbase around vBuckets. In this image, we can see that 9 vBuckets are being distributed across 3 servers, with no redundancy.
- An incrementing number. The number’s value isn’t very important, but what is important is that it always goes up. This is how Couchbase can order all of the DCP messages in time, which is pretty important.
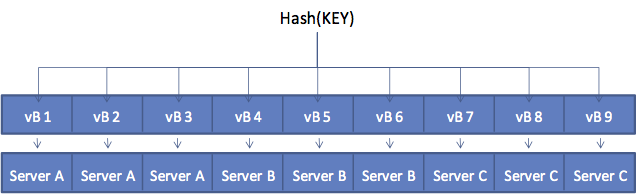
Source of image: http://static.couchbaseinc.hosting.ca.onehippo.com/images/server/3.x/20170420-170703/vbuckets.png
Our simple use case
Let’s take Couchbase’s beer-sample data bucket as an example. Users can rate beers; when a beer’s aggregate rating hits a certain threshold, the marketing guys want to know. They’ll probably call up the brewer and ask them if they want to advertise on our beer website. Or better yet, maybe if some beer hits 5 stars they’ll just stock up for the next company gathering. Either way, they want to know about the 5-star beers.
The problem is that the marketing guys have a separate lead system. We can notify them by making a simple HTTP post to their system. When a beer hits 5 stars, we notify their lead system to check out Foo Brew.
Code
The code below is adapted from the tutorial on the Java DCP client. Once you understand what’s going on, it’s quite simple to adapt it to your needs.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 |
package com.foo.app; import com.couchbase.client.dcp.Client; import com.couchbase.client.dcp.message.DcpMutationMessage; import com.couchbase.client.dcp.DataEventHandler; import com.couchbase.client.dcp.ControlEventHandler; import com.couchbase.client.deps.io.netty.buffer.ByteBuf; import com.couchbase.client.dcp.transport.netty.ChannelFlowController; import com.couchbase.client.dcp.message.DcpDeletionMessage; import com.couchbase.client.dcp.StreamFrom; import com.couchbase.client.dcp.StreamTo; import java.util.concurrent.TimeUnit; import com.couchbase.client.deps.io.netty.util.CharsetUtil; import com.google.gson.JsonParser; import com.google.gson.JsonObject; public class App { public static void main(String[] args) throws Exception { final JsonParser parser = new JsonParser(); final Client client = Client.configure().hostnames("localhost").bucket("beer-sample").build(); // Don't do anything with control events in this example client.controlEventHandler(new ControlEventHandler() { public void onEvent(ChannelFlowController flowController, ByteBuf event) { event.release(); } }); client.dataEventHandler(new DataEventHandler() { public void onEvent(ChannelFlowController flowController, ByteBuf event) { if (DcpMutationMessage.is(event)) { JsonObject obj = parser.parse(DcpMutationMessage.content(event).toString(CharsetUtil.UTF_8)).getAsJsonObject(); if (obj.get("rating") != null && obj.get("rating").getAsInt() > 4) { // OMG, marketing guys gonna love this stuff... System.out.println("Tasty beer located: " + obj.get("name").getAsString()); } } else if (DcpDeletionMessage.is(event)) { // System.out.println("Goodbye, tasty beer! " + DcpDeletionMessage.toString(event)); } event.release(); } }); // Connect the sockets client.connect().await(); // Initialize the state (start now, never stop) client.initializeState(StreamFrom.BEGINNING, StreamTo.INFINITY).await(); // Start streaming on all partitions client.startStreaming().await(); // Sleep for some time to print the mutations // The printing happens on the IO threads! Thread.sleep(TimeUnit.MINUTES.toMillis(10)); // Once the time is over, shutdown. client.disconnect().await(); } } |
What’s happening in this code?
- Connecting to a client instance (and a particular bucket)
- Tell the client which time range of messages we’re interested in. We’re going for the full cluster history, but we could pick any time period we like: StreamFrom.BEGINNING, StreamTo.INFINITY
- Tell the client how to process an individual message; that’s the dataEventHandler code.
- In our case, we’re parsing the JSON of the underlying document, and checking the beer’s rating.
- In this case, our process runs forever, continuously getting new messages as they occur.
Gotchas to keep in mind
In our simplified example, what we’re storing in Couchbase is always a JSON document. But this need not be the case. So into your application, you’ll probably need to build a few more smarts into it to filter based on the keys you’re interested in, and not try to parse everything as JSON. The DCP event’s content is a buffer of bytes, it isn’t a string or a JSON document. This is true to form of what Couchbase is actually storing under the hood.
DCP also reports to you mutations at single points in time. One detail we glossed over a bit is that while certain beer’s ratings may get above 4, this isn’t a guarantee that the beer is rated that way right now, only a guarantee that it was once mutated into that state. A more sophisticated build-out might take this into account.
Finally, please keep in mind that it really can be long, depending on the size and mutation speed of the cluster. So you may want to take a look into flow control techniques so that your client can keep up with the stream of events.
Where to next?
Now that you’re familiar with DCPs, you might want to first check out Couchbase’s available connectors, which mostly rely on DCP already, and provide you a way to take advantage of all of this without any coding.
Another topic to look into is streaming data systems, and the types of analytics that can be done “on the fly” on data streams rather than on data in place. Most of the cloud computing providers like AWS, Google Compute Engine, and others are doing some remarkable things in this space, and with DCP you’re fully able to put anything you’ve got in your Couchbase cluster into a data stream which can be connected with any of these powerful downstream tools.
[1] It’s a little more complicated, but I’m simplifying and linking the storage architecture so you can go deeper into learning more about this topic.
This post is part of the Couchbase Community Writing Program