This article introduces Data Structures and how they work with Couchbase Server 7.0 Scopes and Collections features.
What are data structures?
Couchbase Data Structures is an API feature that aligns the language of the database interface with a programming language.
Data structures help simplify data models for NoSQL system developers. They are basic data management units for storing and retrieving data quickly and efficiently. Document databases, and other key-value databases, often support indexing of this data for query use cases.
Simplifying NoSQL application development
Interaction with full JSON documents is not required. If all the software developer needs, for example, is a single item in a list. After authenticating the database connection, a simple get or set function should be all that is needed.
A range of data structure functions provide access to these native programming objects:
- Documents – full JSON hierarchical document support
- Sub-documents – subsets of objects within a document
- Counters – a single incrementing integer
- Maps – key-value dictionary mappings
- Lists/collections – indexed and ordered lists of items
- Sets – unique value sets of list items
- Queues – first-in-first-out access to list items
Direct Data Access Methods
Couchbase manages its data as flexible JSON documents which can be exposed as atomic pieces of data through simple functions. For example, you can fetch a sub-component of the document, create a numbered item in a list, or add values to an ordered list. Data documents can be called directly their ID names after they are persisted and distributed to the cluster.
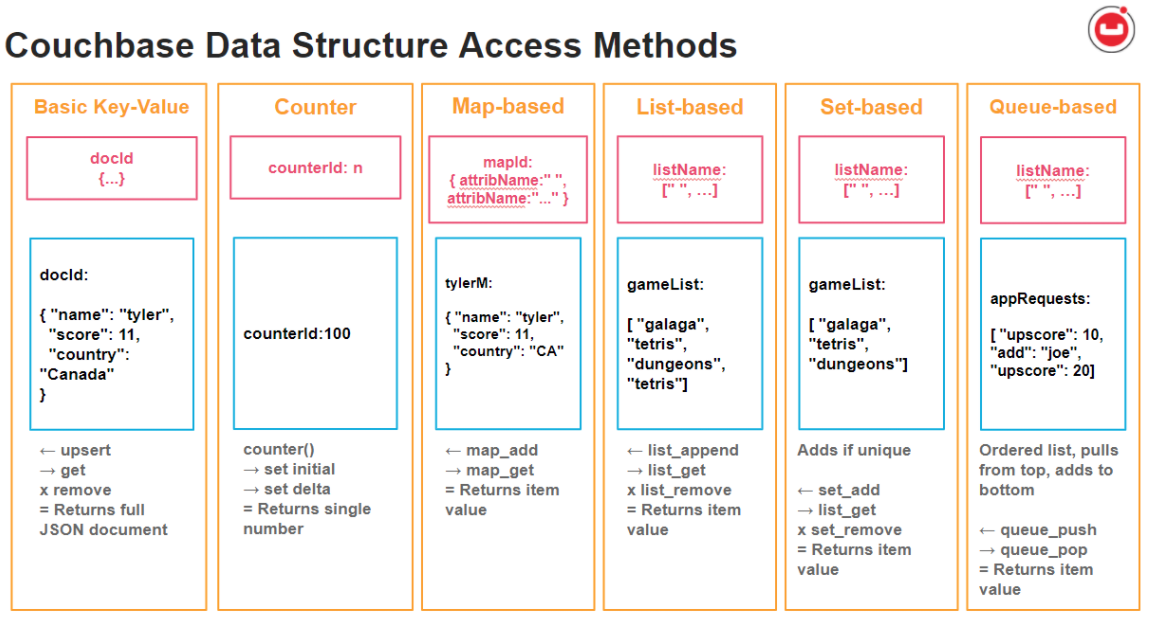
Summary of Couchbase Data Structure types and JSON samples.
Python examples are used to show basic usage of these data structure types, though all SDK languages are supported. See the complete code example at the end of this post for the preamble code, imports, etc.
Key-value access
General KV operations include get and set/upsert functions. JSON-compliant documents are saved or updated with a specific document ID.
|
1 2 3 |
>>> db.upsert("docId", { "name": "tyler", "score": 11, "country": "CA" }) >>> sb.get("docId").content '{ "name": "tyler", "score": 11, "country": "CA"}' |
Counters
Even simpler is a named counter object that stores a single integer value. When the item is called, an initial value is defined and then incremented. This simple method is perfect for a global incrementing number across applications.
|
1 2 3 4 5 |
>>> db.counter("currentScore",delta=1,initial=0).value # Creates at 0 0 >>> db.counter("currentScore").value # Adds 1 1 |
Map-based access
Maps (aka dictionaries) assign an object key with a value. The value of the map entry can be any JSON compliant object. You can create a new map and value combination in one call and have it saved into its own document.
For example, a user profile map may have the ID of a username. That user profile may also have several uniquely named mappings within it such as name or address. Each can be managed independently of others.
|
1 2 3 |
>>> db.map_add("tylerM","name","Tyler", create=True) >>> db.map_add("tylerM","country","Canada") |
In this case, the ID for the map is also accessible through the basic KV get function.
|
1 2 3 |
>>> db.get("tylerM").content {'name': 'Tyler', 'country': 'Canada'} |
There are also map-specific functions for checking if it exists and removing or fetching items.
List-based access
Other JSON objects and values can be stored in a simple list structure without having to use JSON at all. List functions add items to a list and let you pull them back out using an index number.
You provide a list ID and the new value all in one step. Removal or retrieval needs the list ID and the item index number. The complete list is also accessible with the KV get function.
|
1 2 3 4 5 6 7 8 9 10 11 |
>>> db.list_append("gameList","galaga",create=True) >>> db.list_append("gameList","tetris") >>> db.list_append("gameList","dungeons") >>> db.list_get("gameList",0) 'galaga' >>> db.get("gameList").content ['galaga', 'tetris', 'dungeons', 'tetris'] |
Note that duplicate item values in the list are acceptable and a list_prepend option is available too.
Set-based access
“Set” data structures make it easier to manage unique values in a list. New values are only added if it does not already exist. This reduces the need to retrieve and compare values to the existing list, instead, it is done in a single call.
|
1 2 3 4 |
>>> db.set_add("gameList","tetris") # Trying to add tetris twice is ignored >>> db.get("gameList").content ['galaga', 'tetris', 'dungeons', 'horizon'] |
Queue-based access
Queue data structures are another type of list that maintains items in a particular order. An application can easily add a new item, which goes at the end of the list. An item in the list can then be pulled off the top of the list and is subsequently removed from the list.
You can see why these are called queues – e.g., some kind of work management program may be processing requests as they can get “queued up” in a list and need to operate in a first-in-first-out (FIFO) scenario as an application calls it.
Each value can be any JSON object, so they can include another map, list, etc.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
>>> db.queue_push("appRequests",{"updatescore":10},create=True) >>> db.queue_push("appRequests",{"adduser":"joe"}) >>> db.queue_push("appRequests",{"updatescore":20}) >>> db.get("appRequests").content [{'updatescore': 20}, {'adduser': 'joe'}, {'updatescore': 10}] >>> db.queue_pop("appRequests") # Value is returned as it is removed from list {'updatescore': 10} >>> db.get("appRequests").content # First value is now removed [{'updatescore': 20}, {'adduser': 'joe'}] |
You may want to use sets or queues for convenience in some cases, but you can always go back and use list or KV functions to add/remove and manage more directly with your code as needed.
One Step Deeper – Sub-documents
What do you do when you want to query for a specific sub-object in a deeper hierarchical JSON document? The map and list functions cannot extract from subitems in a single document call. You can, of course, request the whole document and process it in your application but that would be unnecessarily inefficient.
Couchbase SDK provides a sub-document API for making single update/get requests for values at deeper levels.
For example, a user profile may have an address mapping with sub-items for street, city, and country. These cannot be accessed with the normal map functions but can be using the sub-document API instead.
There are several potent sub-document functions, but only a quick retrieval example is shown here using the lookup_in function.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
>>> import couchbase.subdocument as SD >>> db.map_add("tylerM","contact", {"address":{"country":"Canada","city":"Vancouver"}}) >>> country = db.lookup_in("tylerM",[SD.get("contact.address")]) >>> country.content_as[str](0) "{'country': 'Canada', 'city': 'Vancouver'}" >>> country = db.lookup_in("tylerM",[SD.get("contact.address.country")]) >>> country.content_as[str](0) 'Canada' |
Using Scopes and Collections with Data Structures
The introduction of Scopes and Collections in Couchbase 7.0 enables finer levels of control over all aspects of document management. Scopes are a subset of all documents in the bucket and collections are a subset of a scope.
For more information on these topics in general see the blog Introducing Collections – Developer Preview in Couchbase Server 6.5.
The scope and collections must already exist – create new ones using tools on the bucket definition page of the web console.
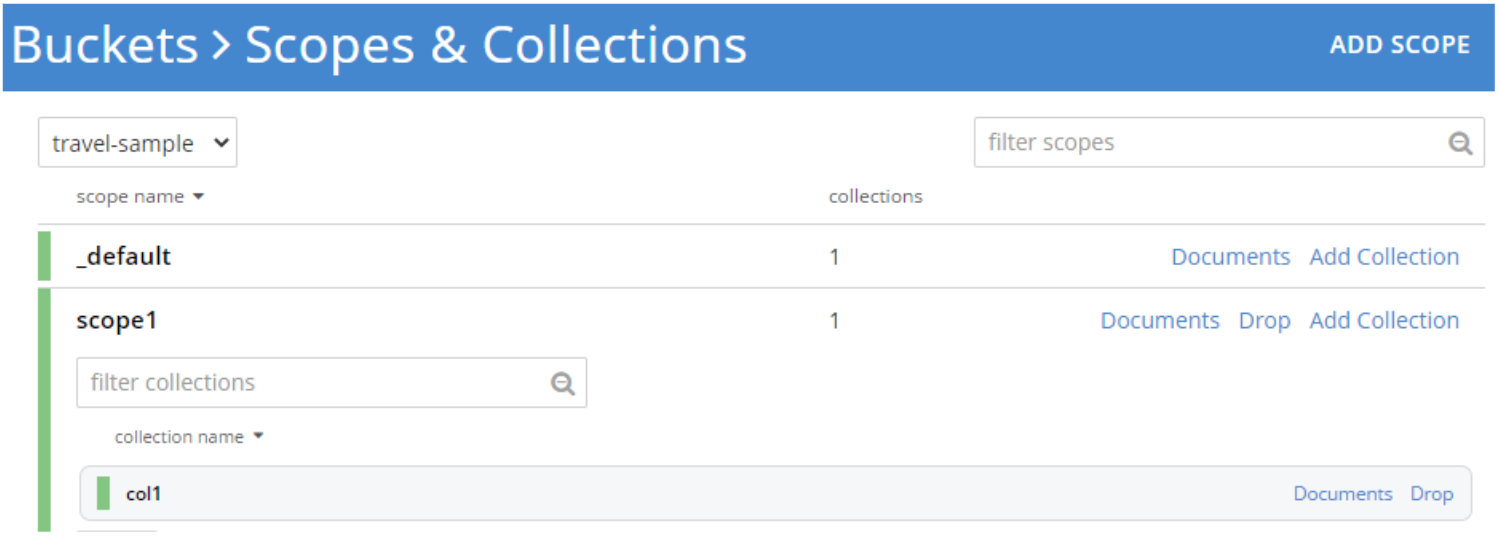
The above code examples used a default scope instead of a specific scope, or collection. Bucket-level connections define the scopes/collections to be used. A link to a full, commented code example for scopes is included at the end of this article. Here is an example of specifying these parameters:
|
1 |
dbscoped = cluster.bucket('travel-sample').scope('scope1').collection('col1') |
Instead of selecting the “default_collection” option for the bucket, the code uses a specific scope and collection. Instead of using the db object, use the dbscoped objects for data operations instead.
|
1 2 3 |
dbscoped.list_append("newlist",1,create=True) dbscoped.list_append("newlist",2) |
Review the documents page on the web console and filter by collection names to confirm which one you’re using:
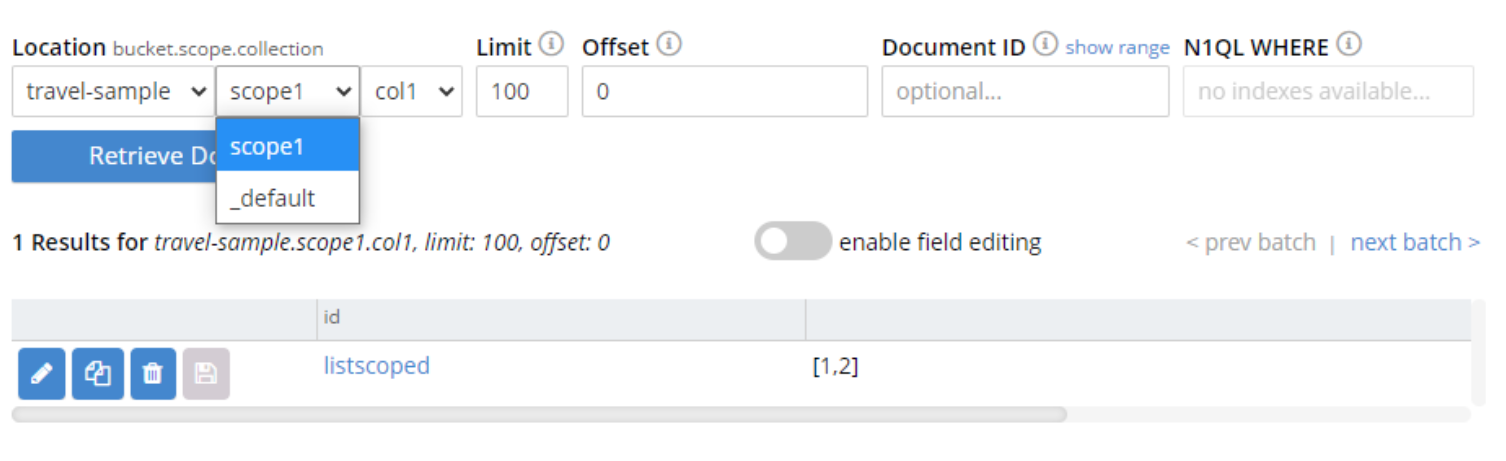
NOTE: At the time of writing, the Python API for counters did not support the use of scopes.
Indexing data structures for efficient SQL or full-text search
Couchbase is about way more than managing raw data structures through the Key-value (KV) engine or JSON data structures. Many applications, especially customer-facing web and mobile NoSQL applications, need more sophistication to integrate with other applications.
Couchbase does this using NoSQL data indexing and SQL-based querying services as well as full-text searching.
What is database indexing? It means examining parts of the data and understanding how to find those elements again within the documents. Searching occurs through a SQL-like query or a full-text search request.
We will cover both of these scenarios in subsequent posts focusing on indexing of native collections in Couchbase data structures.
In the meantime, see this post that covers indexing: NoSQL Database Indexing Best Practices.
Bringing it all together
As you can see, creating documents, counters, and related subcomponents is very simple, using Couchbase. Likewise, through the strategic use of indexes, there are even more ways to access the database.
N1QL queries and full-text searching are common methods that also make use of basic JSON arrays, strings, etc. when mapped properly.
Because Couchbase is an all-inclusive platform, your system architecture can be greatly simplified. Developers can get started right away without a lot of heavy lifting or database management.
- Download the complete Python code example here
- Data structures API docs: Java, .NET, Node.js, Go, PHP, Python, C, Ruby, Scala
- Sub-document operations docs (Python SDK)