Couchbase is the world’s leading NoSQL document database. It offers unmatched performance, flexibility and scalability on the edge, on-premise and in the cloud. Spark is one of the most popular in-memory computing environments. The two platforms can be combined to execute blazingly fast query, data engineering, data science and machine learning functions.
In this QuickStart, I will guide you through the simple steps to set up Couchbase with Databricks* and run Couchbase data queries and Spark SQL queries.
*Note: The steps in this QuickStart have been validated against Databricks runtime 10.4 LTS.
Setup
Prerequisites
To complete this QuickStart, you will need the following:
-
- A Couchbase cluster and travel-sample bucket accessible to the Databricks cluster. I used a Couchbase cluster on an AWS EC2 machine.
- A Databricks account – free trials that require an AWS, Azure, or GCP account are available.
- The Couchbase spark-connector library, version 3.2.2 – available via Maven:
- In the cluster creation screen under the Libraries tab. Select Install new and search for the package on Maven Central. See the example below:
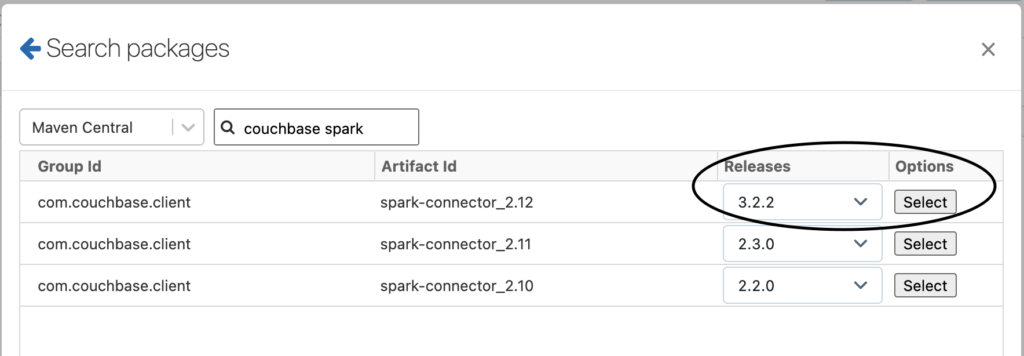
-
- The Install library setting will be configured as in the example below:
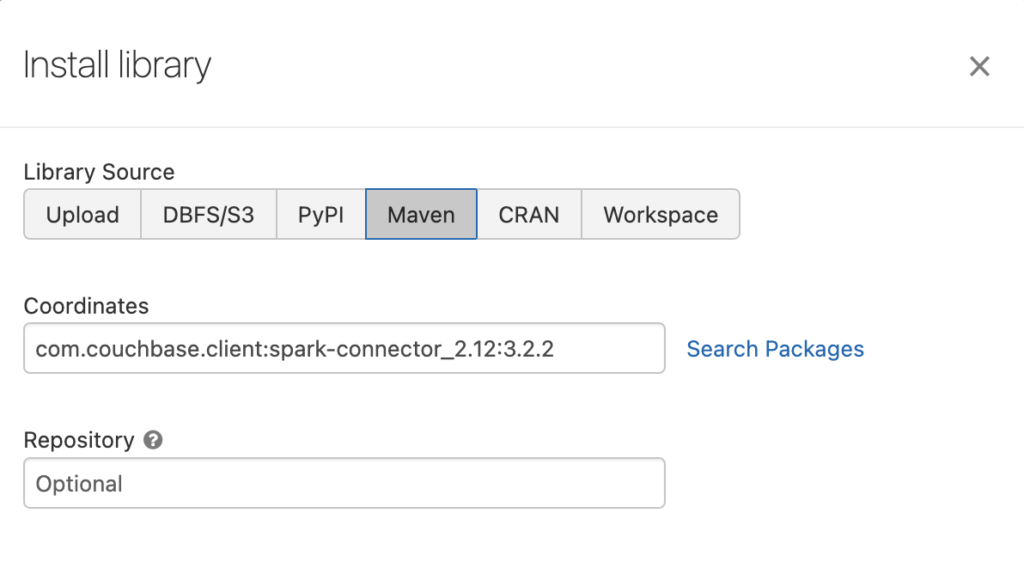
Configuration
Before we begin, we need to configure the following parameters in the Databricks cluster advanced options Spark config. This can be done when you create a cluster (please see screen print below):
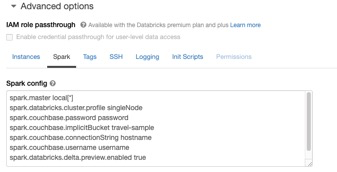
You can copy and paste the settings below and replace parameters in <> with the values for your Couchbase cluster in the advanced options Spark config:
|
1 2 3 4 5 |
spark.couchbase.password <password> spark.couchbase.implicitBucket <travel-sample> spark.couchbase.connectionString <hostname> spark.couchbase.username <username> spark.databricks.delta.preview.enabled true |
First, let’s run the necessary imports. Copy the sample code below to a blank notebook attached to a cluster with the configuration above
|
1 2 3 4 5 6 7 8 9 10 11 |
import com.couchbase.spark._ import org.apache.spark.sql._ import com.couchbase.client.scala.json.JsonObject import com.couchbase.spark.kv.Get import com.couchbase.client.scala.kv.MutateInSpec import com.couchbase.spark.kv.MutateIn import com.couchbase.client.scala.kv.LookupInSpec import com.couchbase.spark.kv.LookupIn import com.couchbase.client.scala.query.QueryOptions import com.couchbase.spark.query.QueryOptions import com.couchbase.client.scala.analytics.AnalyticsOptions |
Now, let’s get some documents by keys from the Couchbase travel-sample database using the code below:
|
1 2 3 4 |
sc .couchbaseGet(Seq(Get("airline_10"), Get("airline_10642"))) .collect() .foreach(result => println(result.contentAs[JsonObject])) |
Great, we have connected to the cluster and returned our first RDD (Resilient Distributed Dataset).
We can query the data using SQL++ (Couchbase Query language based on SQL). Run the code below as an example:
|
1 2 3 4 |
sc .couchbaseQuery[JsonObject]("select country, count(*) as count from `travel-sample` where type = 'airport' group by country order by count desc") .collect() .foreach(println) |
Analytics Service Query
Couchbase also offers an Analytics service for operational analytics and real-time analytics below is an example of an analytics query:
|
1 2 |
val query = "SELECT ht.city,ht.state,COUNT(*) AS num_hotels FROM `travel-sample`.inventory.hotel ht GROUP BY ht.city,ht.state HAVING COUNT(*) > 30" sc.couchbaseAnalyticsQuery[JsonObject](query).collect().foreach(println) |
Now on to some Spark SQL
Use the code below to create temp views for airlines and airports DataFrames:
|
1 2 3 4 5 6 7 8 9 |
val airlines = spark.read.format("couchbase.query") .option(QueryOptions.Filter, "type = 'airline'") .load() airlines.createOrReplaceTempView("airlines") val airports = spark.read.format("couchbase.query") .option(QueryOptions.Filter, "type = 'airport'") .load() airports.createOrReplaceTempView("airports") |
We can now run Spark SQL queries on the views, for example:
Get airlines in ascending order:
|
1 |
%sql select * from airlines order by name asc limit 10 |
Get airlines grouped by country:
|
1 |
%sql select country, count(*) from airlines group by country; |
And finally, let’s visualize the airports per country using a UDF (User Defined Function) along with the Databricks mapping feature. Create the UDF using the SQL++ below:
|
1 2 3 4 5 6 7 8 |
val countrymap = (s: String) => { s match { case "France" => "FRA" case "United States" => "USA" case "United Kingdom" => "GBR" } } spark.udf.register("countrymap", countrymap) |
Select the airport counts by country and visualize the results:
|
1 |
%sql select countrymap(country), count(*) from airports group by country; |
After completing this Quickstart, your result should be similar to the visualization below:
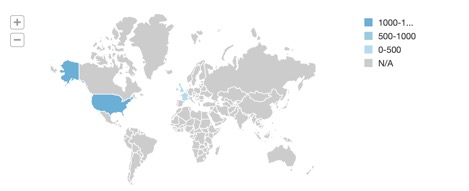
What we have accomplished
In this QuickStart, I have outlined how to utilize the Couchbase spark-connector with Databricks to create RDDs, run Couchbase and Spark SQL queries, create a UDF, and utilize the Databricks mapping feature to visualize the results. These steps demonstrate the process used to access, analyze and visualize data in a Couchbase cluster from a Databricks notebook interface.
Next steps
Learn more about Couchbase Capella:
-
- Take Capella for a test drive by signing up for a free 30-day trial.
- Connect your trial cluster to the Playground or connect a project to test it out for yourself.
- Vist the Couchbase Developer Portal which tons of tutorials/quickstart guides and learning paths to help you get started!
- See the documentation to learn more about the Couchbase SDKs.
Thank you for reading this post! If you have any questions or comments, please connect with us on the Couchbase Forums!