Couchbase Server 6.5 brings a host of new features [1] to the leading NoSQL database. One of the key additions to the N1QL query language is support for window functions. These functions were originally introduced in the SQL:2003 standard and provide a performant way of answering many complex business queries. Window functions were previously discussed in the series of posts [2], [3], [4], and in this installment we’ll deep dive into their implementation in Couchbase Analytics.
The Couchbase Analytics service [5] is designed to handle complex ad-hoc queries in the Couchbase data platform. Its key component is the MPP query engine that runs on a separate set of nodes in the cluster to guarantee workload isolation for the operational data nodes. Data is ingested into Analytics using the DCP change protocol [6] and is hash-partitioned among all available Analytics nodes. The MPP query processor divides a single query into subtasks and schedules those to run in parallel on all nodes, repartitioning data if necessary. More information on the overall service architecture is available in our recent VLDB 2019 paper [7] and on our video channel [8].
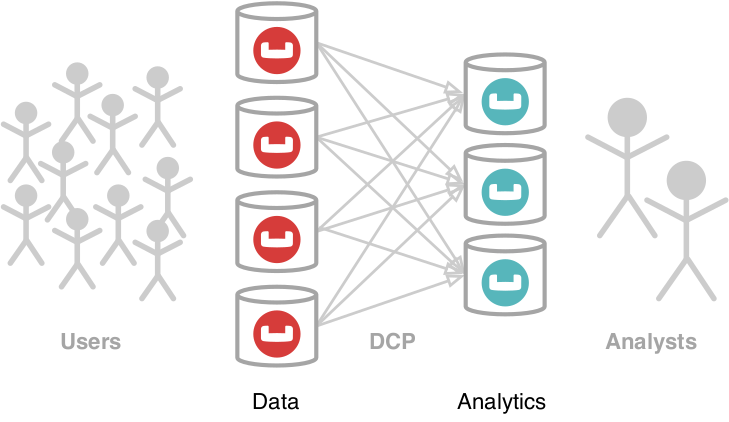
Figure 1: Couchbase Analytics Service
Window functions are also evaluated in a distributed, partition-parallel fashion by the Analytics query engine. The query compiler creates an execution plan that contains several operators working together to compute the result of the window function call. This execution plan is then sent to all Analytics nodes in the cluster where each operator works on a partition of the input data. The execution engine coordinates operator execution and delivers the query result to the client. For example, consider the following query which ranks employees in each department by their salaries.
|
1 2 3 4 5 |
SELECT RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS rank, employee_id, department_id, salary FROM employee |
The query processor evaluates this function in three steps as illustrated by Figure 2.
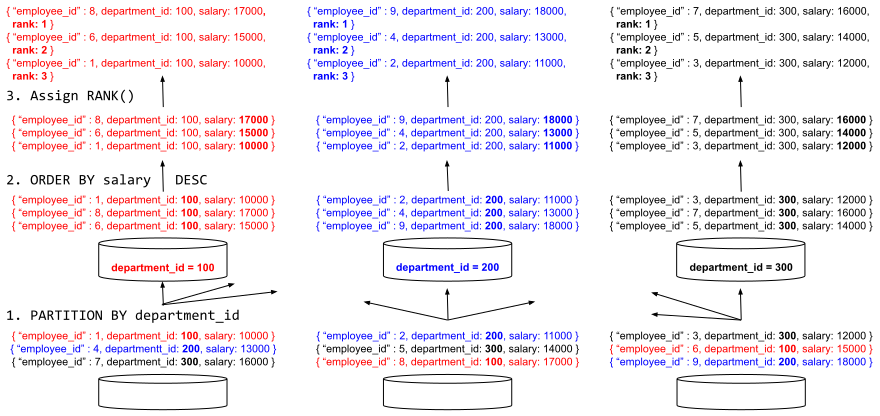
Figure 2: Distributed, parallel query execution of window functions
- After the data is selected from the employee dataset it is repartitioned according to the PARTITION BY subclause of the OVER clause. The initial data layout might have each of the department records scattered across different storage partitions on several Analytics nodes. After the repartitioning step all employee records from a single department arrive into the same computation partition. The repartitioning step is executed in parallel on all nodes/partitions in the cluster. In the most common Analytics configuration there is a one to one relationship between the number of data partitions and the number of CPU cores available in the cluster.
- Records within each department are sorted according to the ORDER BY subclause of the OVER clause. Once each department’s records have arrived at their corresponding computation partitions, the query processor starts sorting the data. This sorting step is also performed in parallel on all Analytics nodes.
- The RANK() function is then computed on sorted records within each department. This particular function only needs to look at the current record and compare it with the previous one, so it can be evaluated in a streaming fashion without requiring any additional data materialization.
Executing these steps in parallel across all available nodes enables Analytics to utilize all computational resources of the cluster. This allows Analytics to achieve linear scalability as more nodes are added to meet the required performance targets.
Let’s see how the above stages can be identified within a query execution plan. The Analytics explain plan feature was described in a previous post [9], so here we only focus on the plan fragment related to the window function evaluation. (Recall that Analytics query plans are to be read bottom up.)
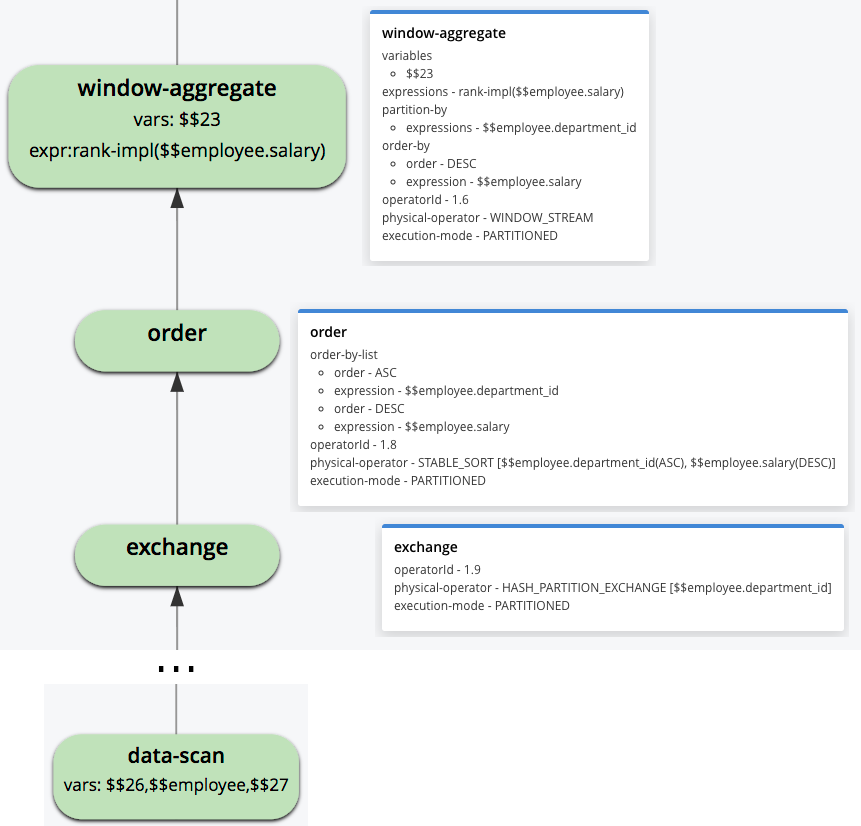
Figure 3: Fragment of the query execution plan
Data is read from the employee dataset by the “data-scan” operator and is passed to the “exchange” operator which is responsible for data repartitioning. The repartitioning field is “department_id” as requested by the PARTITION BY subclause. The “order” operator then sorts the data according to the ORDER BY subclause. Finally, the “window-aggregate” operator computes the RANK() function. Notice how the “physical-operator” value for this operator is set to “WINDOW_STREAM”, which means that the operator works in a streaming manner and does not require any additional data materialization. The “execution-mode” field is set to “PARTITIONED” for all operators, so they will all be executed on all available computation partitions in the cluster.
Evaluation of some window functions might require information pertaining to a whole logical partition (its total number of tuples for NTILE() and PERCENTILE_RANK() functions, for example) or multiple iterations over the whole partition (when computing window frames for aggregate functions). Such functions are processed by non-streaming window operators. A non-streaming window operator is identified by “physical-operator” value of “WINDOW” in the query execution plan. The operator materializes one logical partition at a time, then starts the window function computation for each tuple in that partition. In order to handle arbitrary amounts of incoming data the operator follows the memory management model of the Analytics execution engine. The query planner assigns a memory budget to each operator. This budget cannot be exceeded during query execution. Operational data beyond the budget is spilled to disk by each operator and read back later when memory becomes available. A query usually consists of multiple operators and therefore has a global memory budget that cannot be exceeded at runtime. The Analytics query processor implements resource-based load control for incoming queries, only admitting those that can be executed within the available memory across all nodes.
N1QL for Analytics also places fewer restrictions on the syntactic context of window function calls. Unlike SQL, queries in N1QL for Analytics permit window functions in WHERE and HAVING clauses as well as in N1QL-specific LET clauses.
Our original query, for example, can be easily modified to return only the top-ranked employee in each department:
|
1 2 3 4 5 |
SELECT employee_id, department_id, salary FROM employee WHERE RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) = 1 |
To conclude, window functions in Analytics provide a powerful mechanism for parallel data analysis and reporting. The Couchbase N1QL query language allows users to easily evaluate those functions directly on their application’s JSON data, thereby avoiding complex ETL processing.
Download Couchbase Server 6.5 today and contact us on the Forums for any questions or comments.
References
[1] Announcing Couchbase Server 6.5 GA – What’s New and Improved
https://www.couchbase.com/blog/announcing-couchbase-server-6-5-0-whats-new-and-improved/
[2] On Par with Window Functions
https://www.couchbase.com/blog/on-par-with-window-functions-in-n1ql/
[3] Get a Bigger Picture with N1QL Window Functions and CTE
https://www.couchbase.com/blog/get-a-bigger-picture-with-n1ql-window-functions-and-cte/
[4] Window functions in Couchbase Analytics
https://www.couchbase.com/blog/window-functions-in-couchbase-analytics/
[5] Announcing Couchbase Server 6.0 with Analytics
https://www.couchbase.com/blog/announcing-couchbase-6-0/
[6] Couchbase’s History of Everything: DCP
https://www.couchbase.com/blog/couchbases-history-everything-dcp/
[7] Murtadha Al Hubail, Ali Alsuliman, Michael Blow, Michael Carey, Dmitry Lychagin, Ian Maxon, and Till Westmann. Couchbase Analytics: NoETL for Scalable NoSQL Data Analysis. PVLDB, 12(12): 2275-2286, 2019
http://www.vldb.org/pvldb/vol12/p2275-hubail.pdf
[8] Couchbase Analytics: Under the Hood – Connect Silicon Valley 2018
https://www.youtube.com/watch?v=1dN11TUj58c
[9] Analytics Explain Plan – Part 1
https://www.couchbase.com/blog/analytics-explain-plan-part-1/
Nice post!