Unlock advanced reasoning at a lower TCO for Enterprise AI
Today, we’re excited to share that DeepSeek-R1 is now integrated into Capella AI Services, available in preview! This powerful distilled model, based on Llama 8B, enhances your ability to build agentic applications with advanced reasoning while ensuring privacy compliance.
In this blog, we’ll demonstrate how to leverage these models by building a chatbot to enhance enterprise search and knowledge management. With DeepSeek’s powerful inference abilities, organizations can improve:
-
- Legal and compliance review
- Customer support automation
- Technical troubleshooting
For this demo, we’re using DeepSeek Distill-Llama-3-8B, but Capella AI Services at GA plans to introduce higher-parameter variants of the model to further expand your capabilities.
🚀 Interested in testing DeepSeek-R1? Check out Capella AI Services or Sign up for the Private Preview.
Understanding the DeepSeek model
Distillation approach
DeepSeek Distill-Llama-3-8B is trained using knowledge distillation, where a larger teacher model (DeepSeek-R1) guides the training of a smaller, more efficient student model (Llama 3 8B). This results in a compact yet powerful model that retains strong reasoning capabilities while reducing computational costs.
Dataset: benchmarking with BEIR
We are evaluating the model’s reasoning capabilities using the BEIR dataset, an industry-standard benchmark for retrieval-based reasoning. The dataset consists of 75K documents across various domains, structured as follows:
|
1 2 3 4 5 6 |
{ "_id": "632589828c8b9fca2c3a59e97451fde8fa7d188d", "title": "A hybrid of genetic algorithm and particle swarm optimization for recurrent network design", "text": "An evolutionary recurrent network which automates the design of recurrent neural/fuzzy networks using a new evolutionary learning algorithm is proposed in this paper...", "query": "what is gappso?" } |
The model’s ability is tested by determining which documents contain the correct answers to specific queries, demonstrating its reasoning strength.
Getting started: deploying DeepSeek in Capella AI Services
Step 1: Ingest the documents
You can now generate vector embeddings for unstructured and structured documents using Capella AI services. We’re going to import the BEIR dataset’s structured documents into a couchbase collection first before deploying a Vectorization workflow.
Set up a 5-node (or larger!) operational database cluster on Couchbase Capella with the search and eventing functions enabled. You can leverage a preconfigured multi-node deployment option or create a custom configuration.

Once the cluster is deployed, head over to the Import tab under the Data Tools section and click on the import option. For large datasets, you can use the cb-import function.
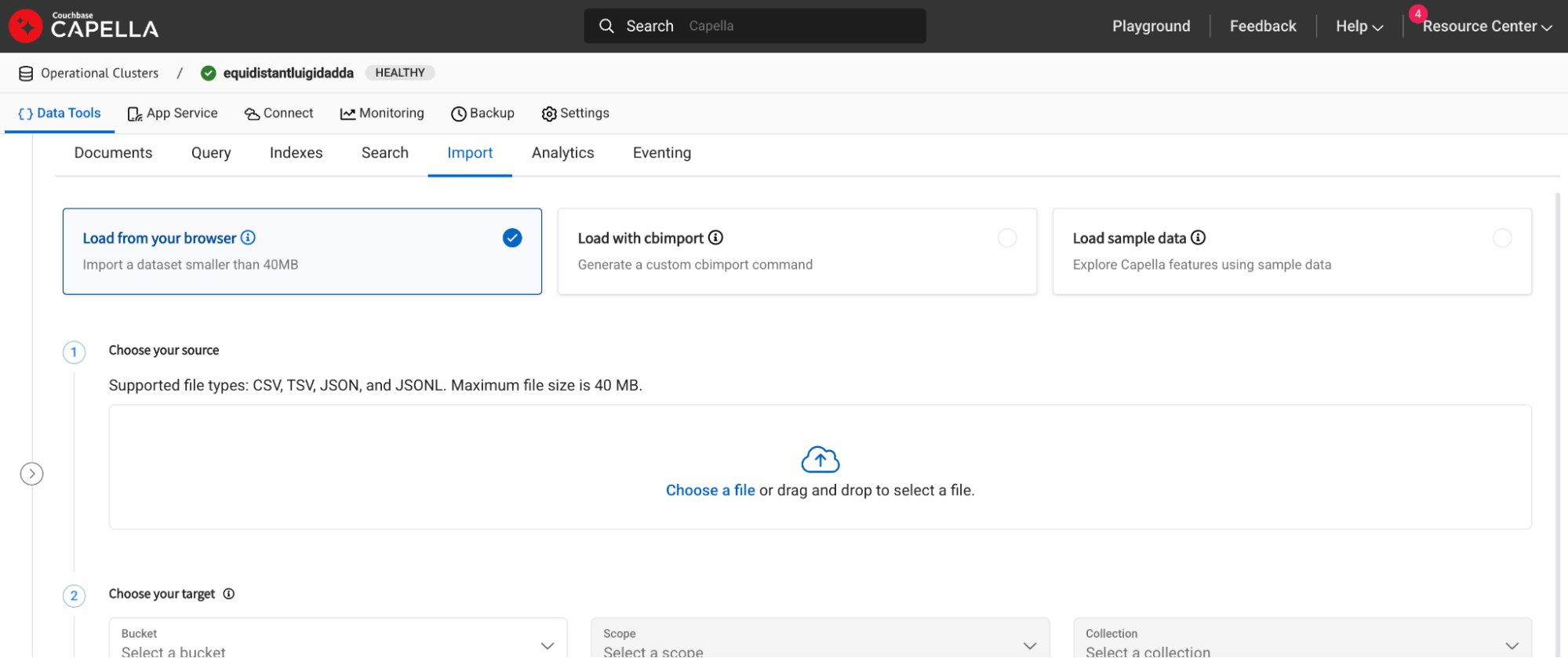 Set up an additional bucket, scope and collection in your operational cluster. We will use this later as a store for the conversational cache.
Set up an additional bucket, scope and collection in your operational cluster. We will use this later as a store for the conversational cache.

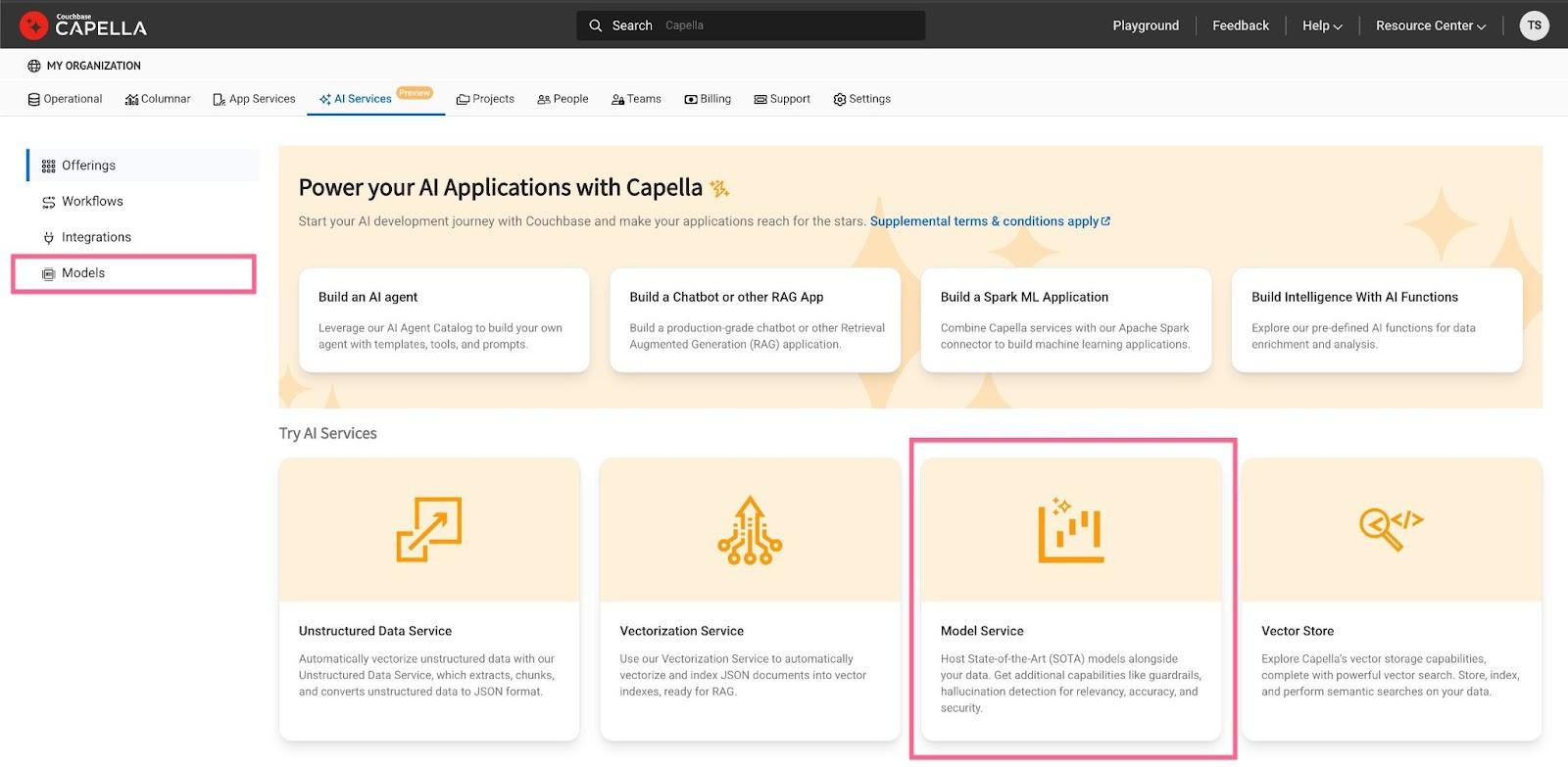
Step 2: Set up an embedding model
Head back to the models tab on the Capella AI services tab. Click the Model Service tile before selecting the following options:

Step 3: Set up a vectorization workflow
Now that the documents have been ingested, refer to this post for details on how to deploy a vectorization workflow.
Name your workflow and specify the collection containing the ingested documents.

Select the embedding model deployed in the previous step.
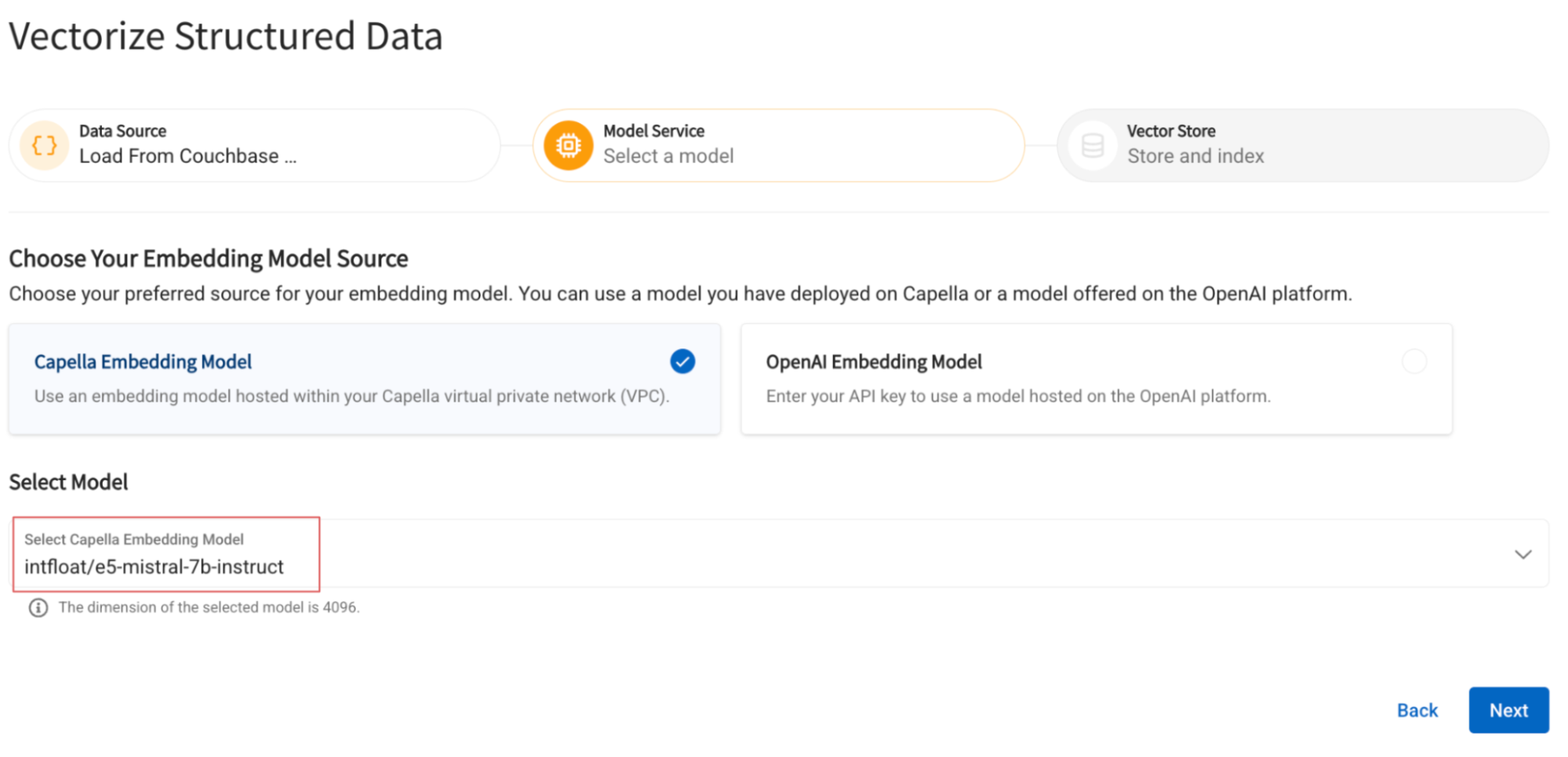
Specify the name of the field that the generated vectors will be inserted into and the name of the index to be built on top of it:
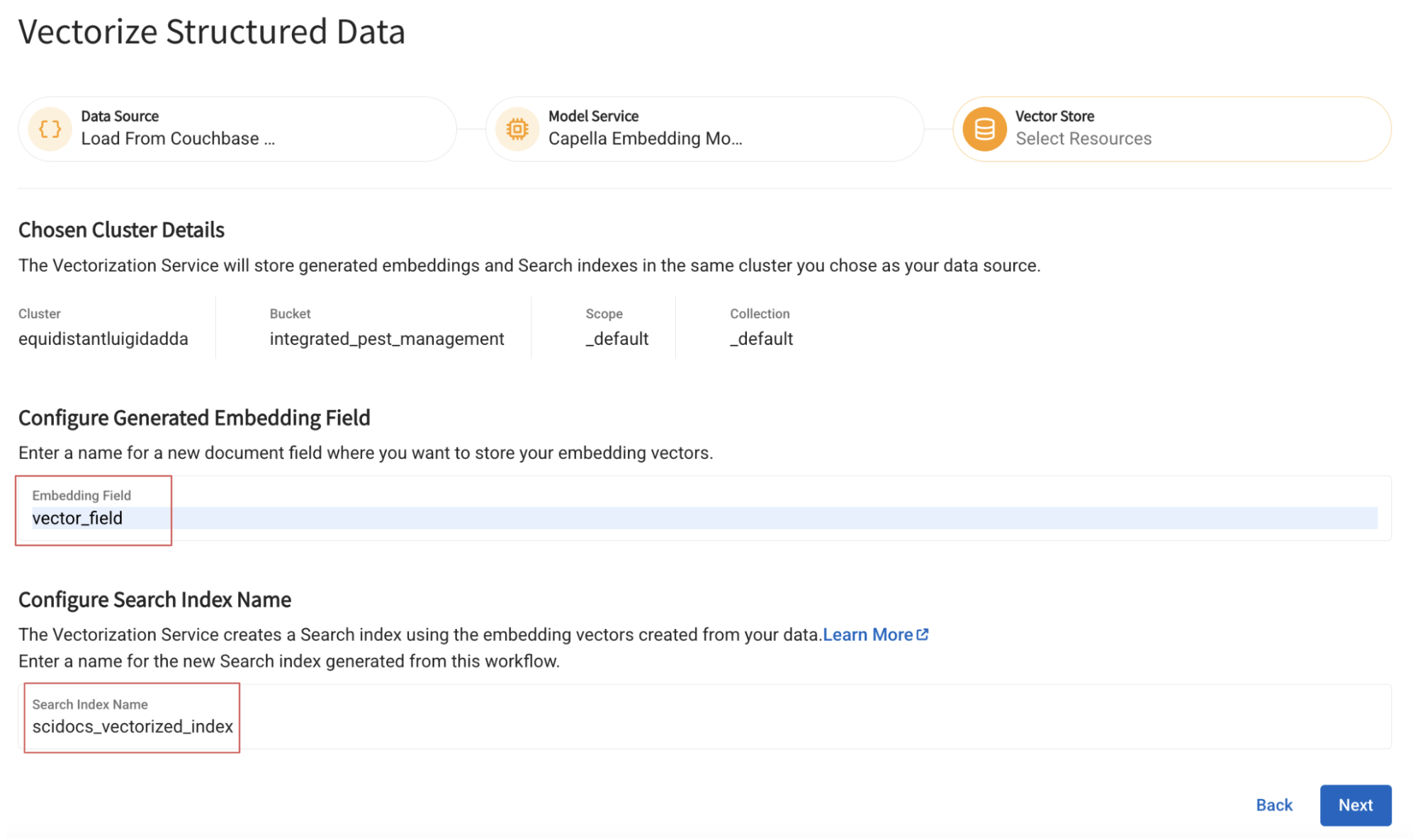
Step 4: Set up the DeepSeek model
Head back to the Capella AI services section and click on the models tab and click on the Model Service tile before selecting the following options:
Select the previously created operational database cluster from the dropdown, select the Capella Small compute instance and the DeepSeek Distill-LLama-3-8B from the model dropdown.

Configure the cache by selecting a bucket-scope-collection and by checking the Conversational Caching box.

Building an application with DeepSeek
Step 1: Configure the settings for application to access the data
Ensure that your IP address is whitelisted to access the documents in your operational DB. You can do this by navigating to the Connect tab of the operational cluster that was created earlier.

Step 2: Run the application
Use the example provided here to set up an application that retrieves the BEIR dataset documents stored in your operational database and then generates a response. Be sure to correctly specify your base64 encoded DB credentials and the model endpoint. You can find the model endpoint by navigating to the AI Services -> Models and then clicking on the downward arrow button which will reveal the model settings.
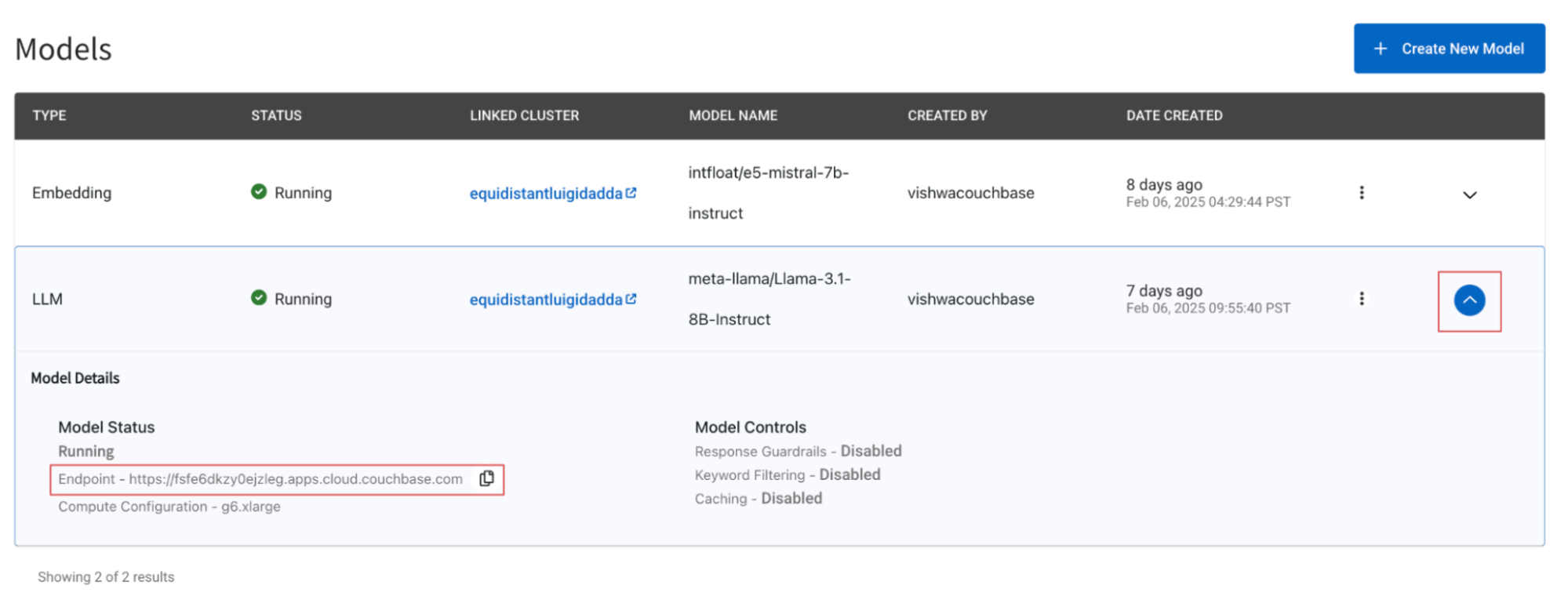
Step 3: Test out the DeepSeek-R1-Distill-Llama-8B
Send an example query to the model and check the results. Once you have verified the response from the model, you can run the entire dataset through the model.
Next steps
-
- 🚀 Get Early Access to DeepSeek-R1 – Join the waitlist
- 📖 Read more about DeepSeek models – DeepSeek Research Paper
- 🔗 Explore the BEIR Dataset – BEIR Official Repository
Capella AI Services is here to help you build AI-powered applications with best-in-class models. Let’s innovate together!