Apart from all the recent discussions about Kubernetes and whether you should Dockerize your database or not, today I would like to show you why those two things might be good solutions when scalability and elasticity is a big requirement in your architecture.
The secret sauce here is simple: Spring Boot with Kubernetes for deploying both your application and database using NoSQL.
Why NoSQL and Spring Data?
With document databases, you can avoid lots of unnecessary joins as the whole structure is stored in a single document. Therefore, it will naturally perform faster than a relational model as your data grows.
If you are using any of the JVM languages, Spring Data and Spring Boot might be something quite familiar to you. Thus, you can quickly start with NoSQL even without any previous knowledge.
Why Kubernetes?
Kubernetes (K8s) allows you to scale up and down your stateless application in a cloud-agnostic environment. In the last few versions, K8s also added the ability to run stateful applications such as databases in it, that is one of the (many) reasons why it is such a hot topic nowadays.
I have shown in my previous blog post how to deploy Couchbase on K8s and how to make it “elastic” by easily scaling up and down. If you haven’t read it yet, please spend a few extra minutes going through the video transcript as it is an important part of what we are going to talk about here.
Creating a User Profile Microservice
In the majority of the systems, the user (and all related entities) is the most frequently accessed data. Consequently, it is one of the first parts of the system that has to go through some sort of optimization as your data grows.
Adding a Cache layer is the first type of optimization we can think of. However, it is not the “final solution” yet. Things might get a little bit more complicated if you have thousands of users, or if you need to store user-related entities also in memory.
Managing massive amounts of user profiles is a well-known good fit for document databases. Just take a look at the Pokémon Go use case, for instance. Therefore, building a highly scalable and elastic User Profile Service seems to be a challenge good enough to demonstrate how to design a highly scalable microservice.
What you are going to need:
- Couchbase
- JDK and Lombok’s plugin for Eclipse or Intellij
- Maven
- A Kubernetes cluster – I’m running this example on 3 nodes on AWS (I do not recommend using minikube). If you don’t know how to set up one, watch this video.
The Code
You can clone the whole project here:
|
1 |
https://github.com/couchbaselabs/kubernetes-starter-kit |
Let’s start by creating our main entity called User:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
@Document @Data @AllArgsConstructor @NoArgsConstructor @EqualsAndHashCode public class User extends BasicEntity { @NotNull @Id private String id; @NotNull @Field private String name; @Field private Address address; @Field private List<Preference> preferences = new ArrayList<>(); @Field private List<String> securityRoles = new ArrayList<>(); } |
In this entity we have two important properties:
- securityRoles: All roles the user can play within the system.
- preferences: All possible preferences the user might have, such as language, notifications, currency, etc.
Now, let’s play a little bit with our Repository. As we are using Spring Data, you can use pretty much all its capabilities here:
|
1 2 3 4 5 |
@N1qlPrimaryIndexed @ViewIndexed(designDoc = "user") public interface UserRepository extends CouchbasePagingAndSortingRepository<User, String> { List<User> findByName(String name); } |
If you want to know more about Couchbase and Spring Data, check out this tutorial.
We also implemented two other methods:
|
1 2 3 4 5 6 |
@Query("#{#n1ql.selectEntity} where #{#n1ql.filter} and ANY preference IN " + " preferences SATISFIES preference.name = $1 END") List<User> findUsersByPreferenceName(String name); @Query("#{#n1ql.selectEntity} where #{#n1ql.filter} and meta().id = $1 and ARRAY_CONTAINS(securityRoles, $2)") User hasRole(String userId, String role); |
- hasRole: Check if a user has a specified role:
- findUsersByPreferencyName: As the name says, it finds all users that contain a given preference.
Notice that we are using N1QL syntax in the code above as it makes things much simpler to query than using plain JQL.
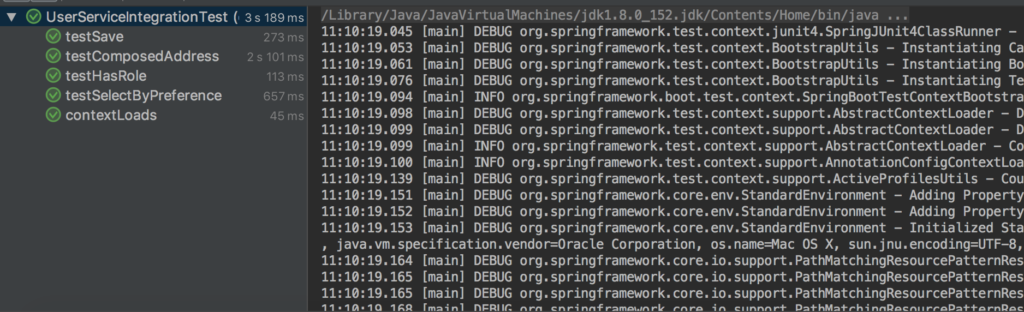
Additionally, you can run all tests to make sure that everything is working properly:
Don’t forget to change your application.properties with the correct credentials of your database:
|
1 2 3 4 |
spring.couchbase.bootstrap-hosts=localhost spring.couchbase.bucket.name=test spring.couchbase.bucket.password=couchbase spring.data.couchbase.auto-index=true |
In order to test our microservice, I added a few Restful endpoints:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
@RestController @RequestMapping("/api/user") public class UserServiceController { @Autowired private UserService userService; @RequestMapping(value = "/{id}", method = GET, produces = APPLICATION_JSON_VALUE) public User findById(@PathParam("id") String id) { return userService.findById(id); } @RequestMapping(value = "/preference", method = GET, produces = APPLICATION_JSON_VALUE) public List<User> findPreference(@RequestParam("name") String name) { return userService.findUsersByPreferenceName(name); } @RequestMapping(value = "/find", method = GET, produces = APPLICATION_JSON_VALUE) public List<User> findUserByName(@RequestParam("name") String name) { return userService.findByName(name); } @RequestMapping(value = "/save", method = POST, produces = APPLICATION_JSON_VALUE) public User findUserByName(@RequestBody User user) { return userService.save(user); } } |
Dockerizing Your Microservice
First, change your application.properties to get the connection credentials from environment variables:
|
1 2 3 4 |
spring.couchbase.bootstrap-hosts=${COUCHBASE_HOST} spring.couchbase.bucket.name=${COUCHBASE_BUCKET} spring.couchbase.bucket.password=${COUCHBASE_PASSWORD} spring.data.couchbase.auto-index=true |
And now we can create our Dockerfile:
|
1 2 3 4 5 6 |
FROM openjdk:8-jdk-alpine VOLUME /tmp MAINTAINER Denis Rosa <denis.rosa@couchbase.com> ARG JAR_FILE ADD ${JAR_FILE} app.jar ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"] |
Then, we build and publish our image on Docker Hub:
- Create your image:
|
1 |
./mvnw install dockerfile:build -DskipTests |
- Log into the Docker Hub from the command line
|
1 |
docker login |

- Let’s grab the imageId of our recently created image:
1docker images

- Create your new tag using the imageId:
|
1 2 |
//docker tag YOUR_IMAGE_ID YOUR_USER/REPO_NAME docker tag 3f9db98544bd deniswsrosa/kubernetes-starter-kit |
- Finally, push your image:
1docker push deniswsrosa/kubernetes-starter-kit
 Your image should now be available at Docker Hub:
Your image should now be available at Docker Hub:

Configuring the Database
I wrote a whole article about it here, but to keep it short. Just run the following commands inside the kubernetes directory.
|
1 2 3 4 |
./rbac/cluster_role.sh kubectl create -f secret.yaml kubectl create -f operator.yaml kubectl create -f couchbase-cluster.yaml |
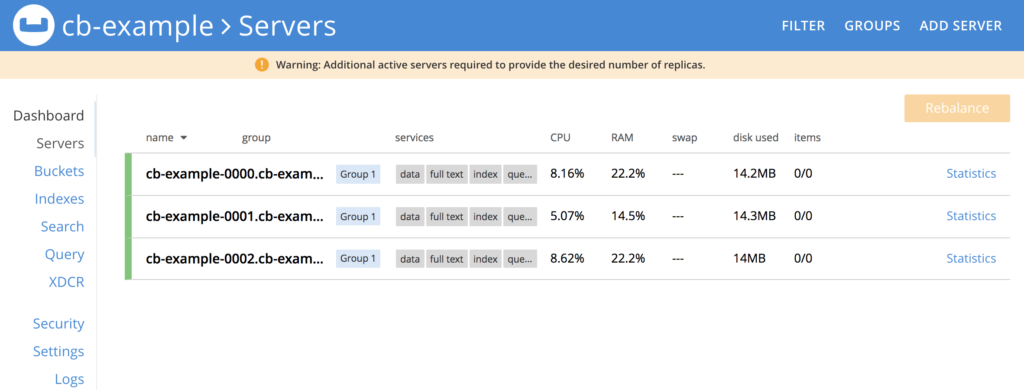
After a while, all the 3 instances of our database should be running:

Let’s forward the Web Console’s port to our local machine:
|
1 |
kubectl port-forward cb-example-0000 8091:8091 |
And now we can access the web console at https://localhost:8091. You can log in using the username Administrator and the password password
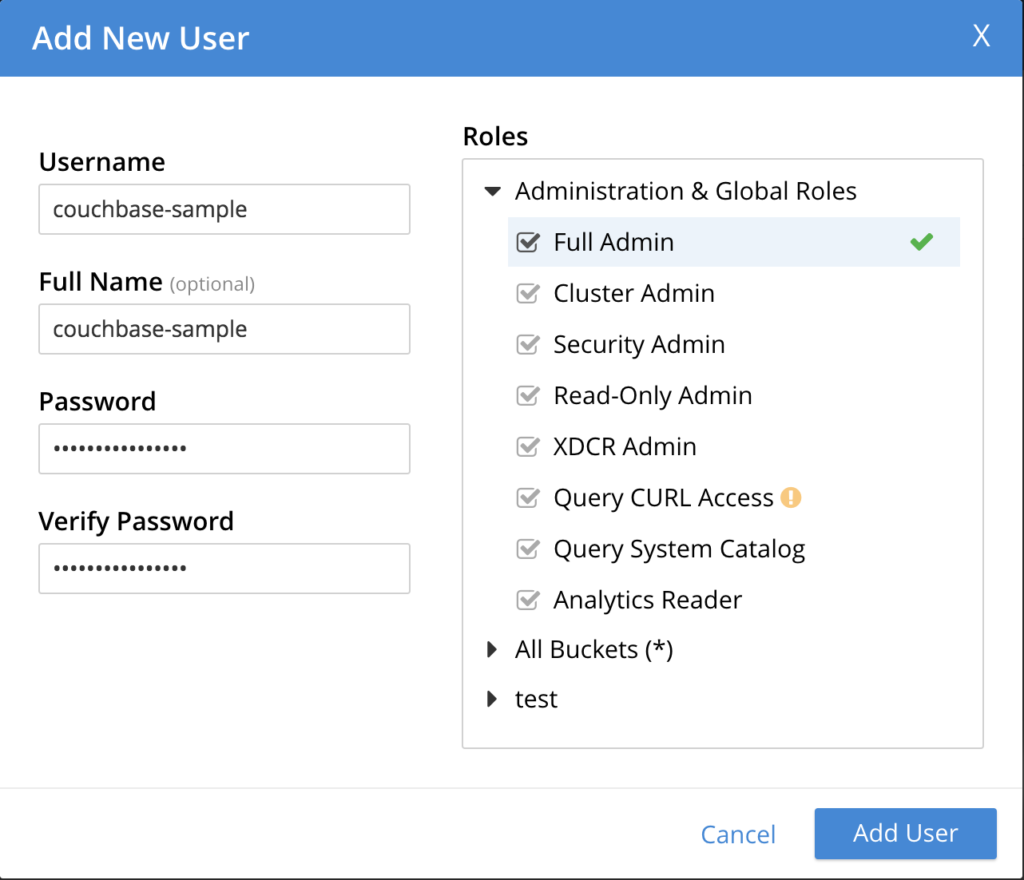
Go to Security -> ADD USER with the following properties:
- Username: couchbase-sample
- Full Name: couchbase-sample
- Password: couchbase-sample
- Verify password: couchbase-sample
- Roles: According to the image below:
OBS: In a production environment, please don’t add your app as an admin
Deploying Your Microservice
First, let’s create a Kubernetes secret where we will store the password to connect to our database:
|
1 2 3 4 5 6 7 |
apiVersion: v1 kind: Secret metadata: name: spring-boot-app-secret type: Opaque data: bucket_password: Y291Y2hiYXNlLXNhbXBsZQ== #couchbase-sample in base64 |
Run the following command to create the secret:
|
1 |
kubectl create -f spring-boot-app-secret.yaml |
The file spring-boot-app.yaml is the one responsible for deploying our app. Let’s take a look at its contents:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
apiVersion: apps/v1beta1 kind: Deployment metadata: name: spring-boot-deployment spec: selector: matchLabels: app: spring-boot-app replicas: 2 # tells deployment to run 2 pods matching the template template: # create pods using pod definition in this template metadata: labels: app: spring-boot-app spec: containers: - name: spring-boot-app image: deniswsrosa/kubernetes-starter-kit imagePullPolicy: Always ports: - containerPort: 8080 name: server - containerPort: 8081 name: management env: - name: COUCHBASE_PASSWORD valueFrom: secretKeyRef: name: spring-boot-app-secret key: bucket_password - name: COUCHBASE_BUCKET value: couchbase-sample - name: COUCHBASE_HOST value: cb-example |
I would like to highlight some important parts of this file:
- replicas: 2 -> Kubernetes will launch 2 instances of our app
- image: deniswsrosa/kubernetes-starter-kit -> The docker image we have created before.
- containers: name: -> Here is where we define the name of the container running our application. You will use this name in Kubernetes whenever you want to define how many instances should be running, autoscaling strategies, load balancing, etc.
- env: -> Here is where we define the environment variables of our app. Note that we are also referring to the secret we created before.
Run the following command to deploy our app:
|
1 |
kubectl create -f spring-boot-app.yaml |
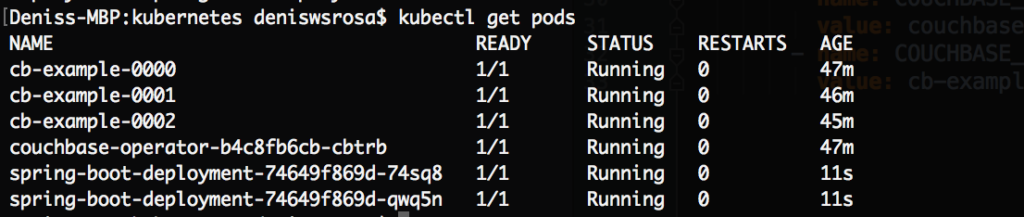
In a few seconds, you will notice that both instances of your application are already running:
Finally, let’s expose our microservice to the outside world. There are dozens of different possibilities of how it can be done. In our case, let’s simply create a Load Balancer:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
apiVersion: v1 kind: Service metadata: name: spring-boot-load-balancer spec: ports: - port: 8080 targetPort: 8080 name: http - port: 8081 targetPort: 8081 name: management selector: app: spring-boot-app type: LoadBalancer |
The selector is one of the most important parts of the file above. It is where we define the containers to which the traffic will be redirected. In this case, we are just pointing to the app we have deployed before.
Run the following command to create our load balancer:
|
1 |
kubectl create -f spring-boot-load-balancer.yaml |
The load balancer will take a few minutes to be up and redirecting traffic to our pods. You can run the following command to check its status:
|
1 |
kubectl describe service spring-boot-load-balancer |
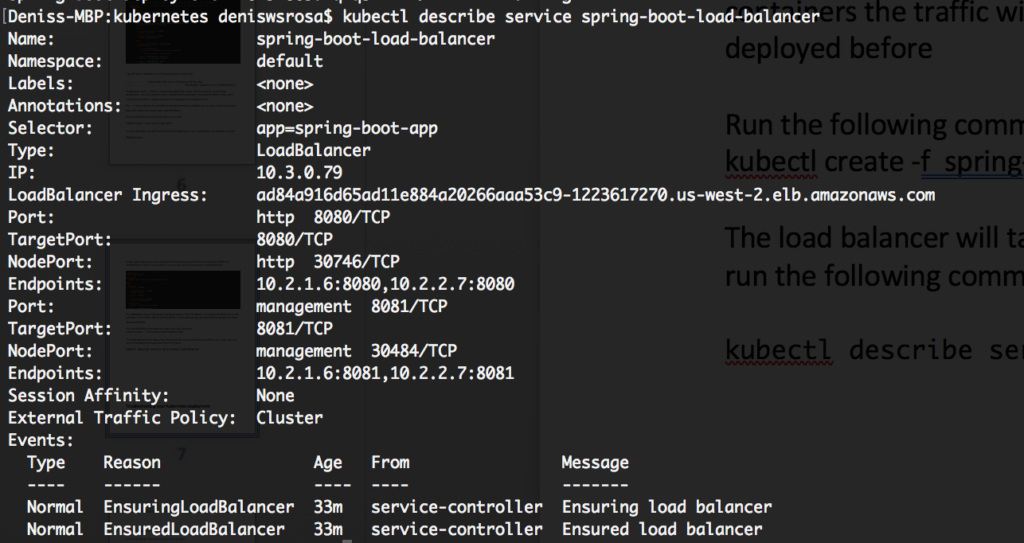
As you can see in the image above, our Load Balancer is accessible at ad84a916d65ad11e884a20266aaa53c9-1223617270.us-west-2.elb.amazonaws.com, and the targetPort 8080 will redirect traffic to two endpoints: 10.2.1.6:8080 and 10.2.2.7:8080
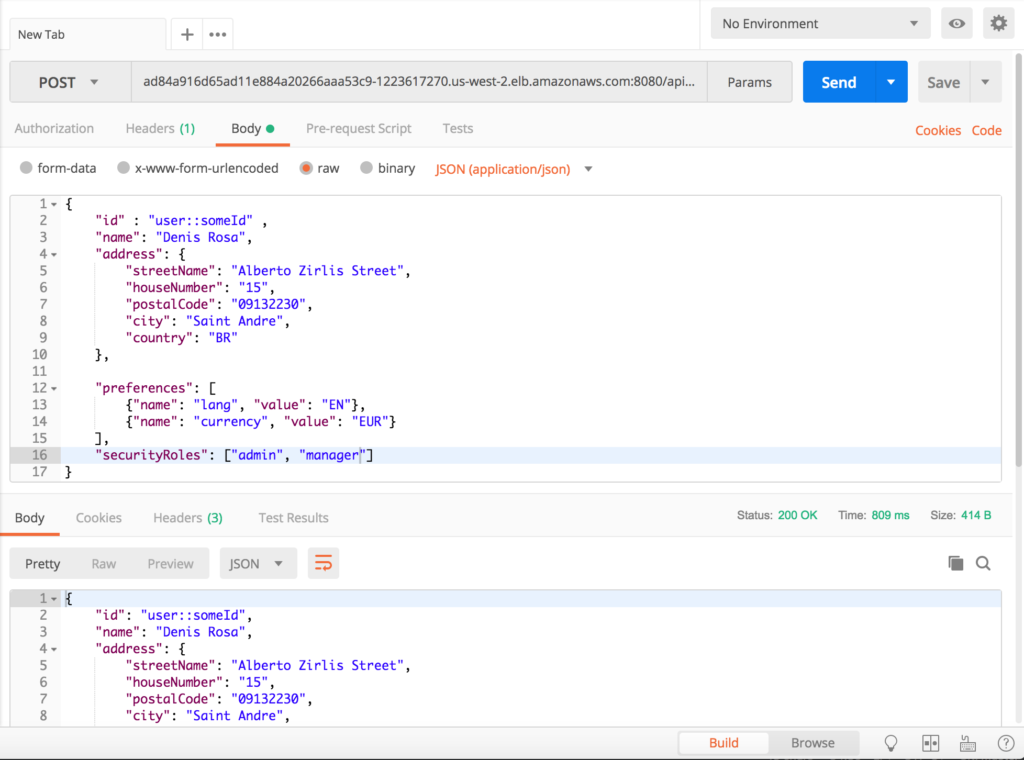
Finally, we can access our application and start sending requests to it:
- Inserting a new user:
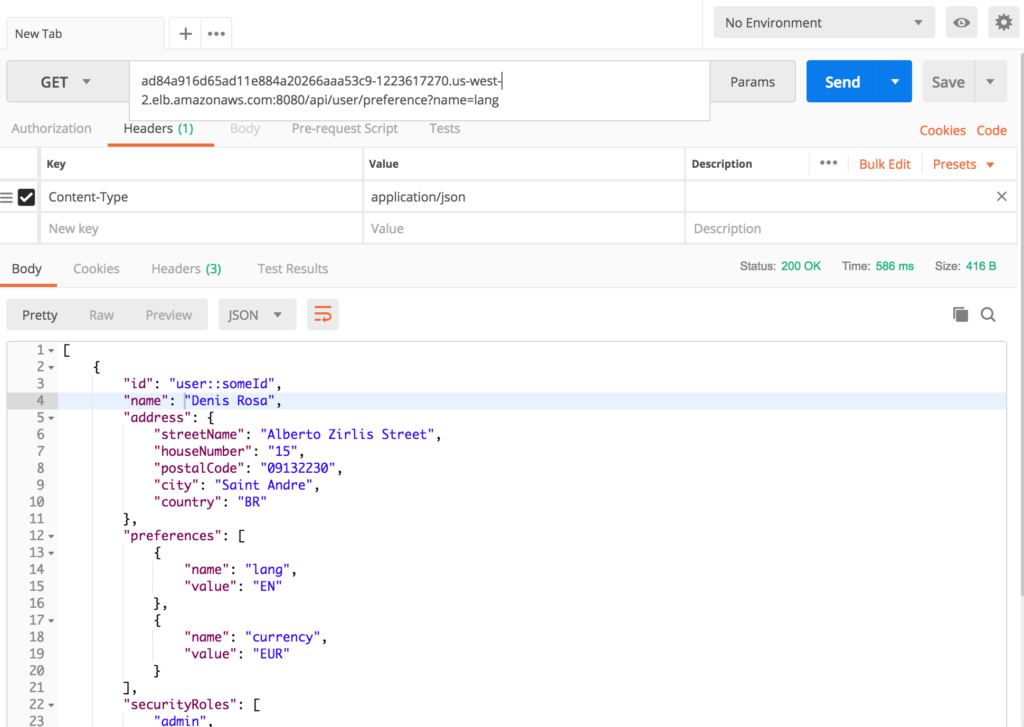
- Searching for users:
What About Being Elastic?
This is where things get really interesting. What if we need to scale up the whole of our microservice? Let’s say the Black Friday is coming and we need to prepare our infrastructure to support this massive flow of users coming to our website. Well, that is an easy problem to solve:
- To scale up our application, we just need to change the number of replicas in the spring-boot-app.yaml file.
12345678910...spec:selector:matchLabels:app: spring-boot-appreplicas: 6 # tells deployment to run 6 pods matching the templatetemplate: # create pods using pod definition in this templatemetadata:labels:...
And then, run the following command:
|
1 |
kubectl replace -f spring-boot-app.yaml |
Is there anything missing? Yes. What about our database? We should scale it up as well:
- Change the size attribute in the couchbase-cluster.yaml file:
|
1 2 3 4 5 6 7 8 9 |
... enableIndexReplica: false servers: - size: 6 name: all_services services: - data - index ... |
Finally, run the following command:
|
1 |
kubectl replace -f couchbase-cluster.yaml |
How Can I Scale It Down?
Scaling down is as easy as scaling up; you just need to change both couchbase-cluster.yaml and spring-boot-app.yaml:
- couchbase-cluster.yaml
|
1 2 3 4 5 6 7 8 9 |
... enableIndexReplica: false servers: - size: 1 name: all_services services: - data - index ... |
- spring-boot-app.yaml:
|
1 2 3 4 5 6 7 8 9 10 |
... spec: selector: matchLabels: app: spring-boot-app replicas: 1 template: metadata: labels: ... |
And run the following commands:
|
1 2 |
kubectl replace -f couchbase-cluster.yaml kubectl replace -f spring-boot-app.yaml |
Auto-Scaling Microservices on Kubernetes
I will make a deep dive into this topic in part 2 of this article. In the meantime, you can check this video about pod autoscaling.
Troubleshooting Your Kubernetes Deployment
If your Pods fail to start, there are many ways to troubleshoot the problem. In the case below, both applications failed to start:
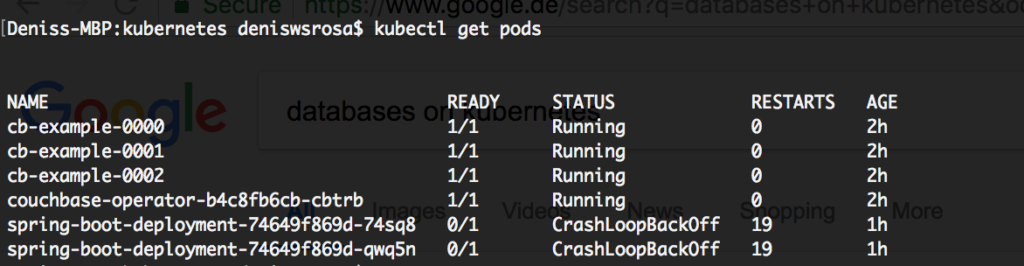
Since they are part of the deployment, let’s describe the deployment to try understanding what is happening:
|
1 |
kubectl describe deployment spring-boot-deployment |
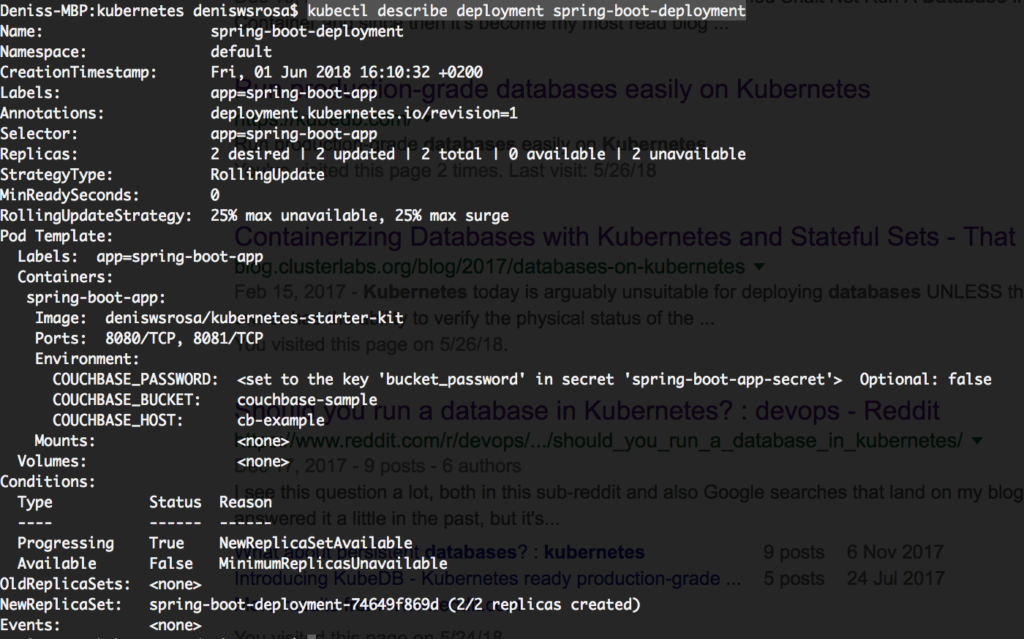
Well, nothing is really relevant in this case. Let’s look at one of the pod’s logs then:
|
1 |
kubectl log spring-boot-deployment-74649f869d-74sq8 |
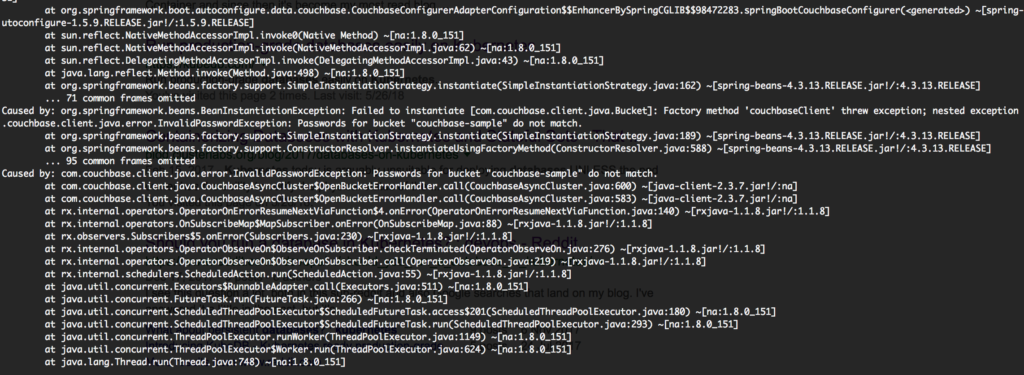
Gotcha! The application did not start because we forgot to create the user on Couchbase. By just creating the user, the pods will be up in a few seconds:
Conclusion
Databases are stateful applications, and scaling them is not as fast as scaling stateless ones (and probably it will never be), but if you need to make a truly elastic architecture, you should plan to scale all components of your infrastructure. Otherwise, you are just creating a bottleneck somewhere else.
In this article, I tried to show just a small introduction about how you can make both your application and database on Kubernetes elastic. However, it is not a production-ready architecture yet. There are plenty of other things to consider still, and I will address some of them in the upcoming articles.
In the meantime, if you have any questions, tweet me at @deniswsrosa or leave a comment below.