New Standard, Semantic and Conversational Cache With LangChain Integration
In the rapidly evolving landscape of AI application development, integrating large language models (LLMs) with enterprise data sources has become a critical focus. The ability to harness the power of LLMs for generating high-quality, contextually relevant responses is transforming various industries. However, teams face significant challenges in delivering trustworthy responses at high speed, while lowering costs – especially as the volume of user prompts increases. Additionally, as most LLMs have limited memory, an opportunity exists to store LLM conversations for an extended time period and prevent users from starting over from scratch after an LLM’s memory times out.
Couchbase, a leader in highly scalable and low-latency caching (Read the LinkedIn story), addresses these challenges with innovative solutions. New enhancements to our vector search and caching offering, as well as a dedicated LangChain package for developers, make it easier to elevate the performance and reliability of generative AI applications.
Couchbase Vector Search and Retrieval-Augmented Generation (RAG)
Couchbase vector search enables users to find similar objects without the need to have an exact match. It is an advanced capability that allows for efficient search and retrieval of data based on vector embeddings, which are mathematical representations of objects across a very large number of dimensions. As an example, searching a product catalog for shoes that are “brown” and “leather,” would return those results as well as “suede” shoes, with colors including “mahogany, chestnut, coffee, bronze, auburn, and cocoa.”
Retrieval-augmented generation (RAG) combines vector search, retrieving information from the Couchbase database related to the user prompt, and delivers both the prompt and relevant related information to a generative model to produce LLM responses that are more informed and contextually appropriate. This is often faster and less costly than training a custom model. Couchbase’s highly scalable in-memory architecture provides fast and efficient access to search for relevant vector embedding data. To make a RAG application more performant and efficient, developers can use semantic and conversational caching capabilities.
Semantic Caching
Semantic caching is a sophisticated caching technique that uses vector embeddings to understand the context and intent behind queries. Unlike traditional caching methods that rely on exact matches, semantic caching leverages the meaning and relevance of data. This means that similar questions, that would otherwise get the same response from an LLM, don’t need to make additional requests to the LLM. Following on from the example above, a user searching for “I am looking for brown leather shoes in size 10” would get the same results as another user requesting “I want to buy size 10 shoes in leather that are the color brown.”

Benefits of semantic caching, especially at higher volumes, include:
- Improved efficiency – Faster retrieval times due to the understanding of query context
- Lower costs – Reduced calls to the LLM save time and money
Conversational Caching
Whereas semantic caching reduces the number of calls to an LLM across a wide variety of users, a conversational cache improves the overall user experience by extending the lifetime conversational knowledge of the interactions between the user and the LLM. By leveraging historical questions and answers, the LLM is able to provide better context as new prompts are submitted.
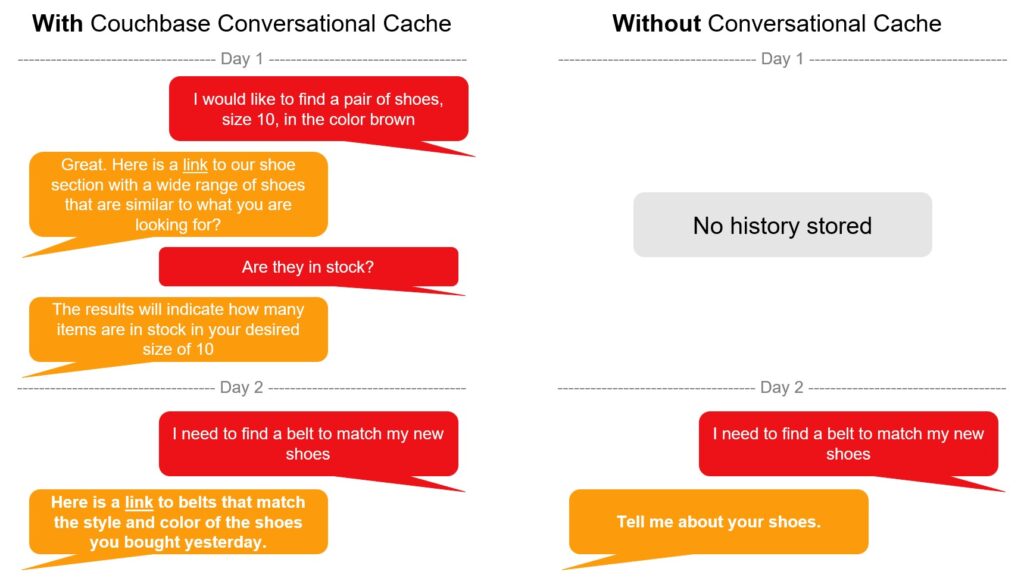
Additionally, conversational caching can be used to help apply reasoning to AI agent workflows. A user may ask, “How well will this item work with my past purchased products?“ First, this requires resolution of the reference “this item” followed by reasoning how to determine how well it will work with past purchases.”
Dedicated LangChain-Couchbase Packages
Couchbase has recently introduced LangChain modules designed for Python developers. This package simplifies the integration of Couchbase’s advanced capabilities into generative AI applications via LangChain, making it easier for developers to implement powerful features like vector search and semantic caching.
The LangChain-Couchbase package seamlessly integrates Couchbase’s vector search, semantic cache, and conversational cache capabilities into generative AI workflows. This integration allows developers to build more intelligent and context-aware applications with minimal effort.
By providing a dedicated package, Couchbase ensures that developers can easily access and implement advanced features without dealing with complex configurations. The package is designed to be developer-friendly, enabling quick and efficient integration.
Key Features
The LangChain-Couchbase package offers several key features, including:
-
- Vector search – Efficient retrieval of data based on vector embeddings
- Standard cache – For faster exact matches
- Semantic cache – Context-aware caching for improved response relevance
- Conversation cache – Management of conversation context to enhance user interactions
Use Cases and Examples
Couchbase’s new enhancements can be applied in various scenarios, like:
-
- E-commerce chatbots – Providing personalized shopping recommendations based on user preferences
- Customer support – Delivering accurate and contextually relevant responses to customer queries
Code Snippets or Tutorials
Developers can find code snippets and tutorials for implementing semantic caching and the LangChain-Couchbase package on LangChain’s website. There are also code examples of vector search on Couchbase’s GitHub repository. These resources provide guidance to help developers get started quickly.
Benefits
Couchbase’s enhancements in vector search and caching offerings for LLM-based applications provide numerous benefits, including improved efficiency, relevance, and personalization of responses. These features are designed to address the challenges of building reliable, scalable, and cost-effective generative AI applications.
Couchbase is committed to continuous innovation, ensuring that our platform remains at the forefront of AI application development. Future enhancements will further expand the capabilities of Couchbase, enabling developers to build even more advanced and intelligent applications.
Additional Resources
-
- Blog: An Overview of RAG
- Docs: Install Langchain-Couchbase Integration
- Docs: Couchbase as Vector Store With LangChain
- Video: Vector and Hybrid Search
- Video: Vector Search for Mobile Apps
- Docs: Vector Search in Capella DBaaS
- Models Supported by LangChain and Couchbase