In today’s data-driven world, the ability to efficiently gather and prepare data is crucial for the success of any application. Whether you’re developing a chatbot, a recommendation system, or any AI-driven solution, the quality and structure of your data can make or break your project. In this article, we’ll take you on a journey to explore the process of information gathering and smart chunking, focusing on how to prepare data for Retrieval-Augmented Generation (RAG) in any application with your database of choice.
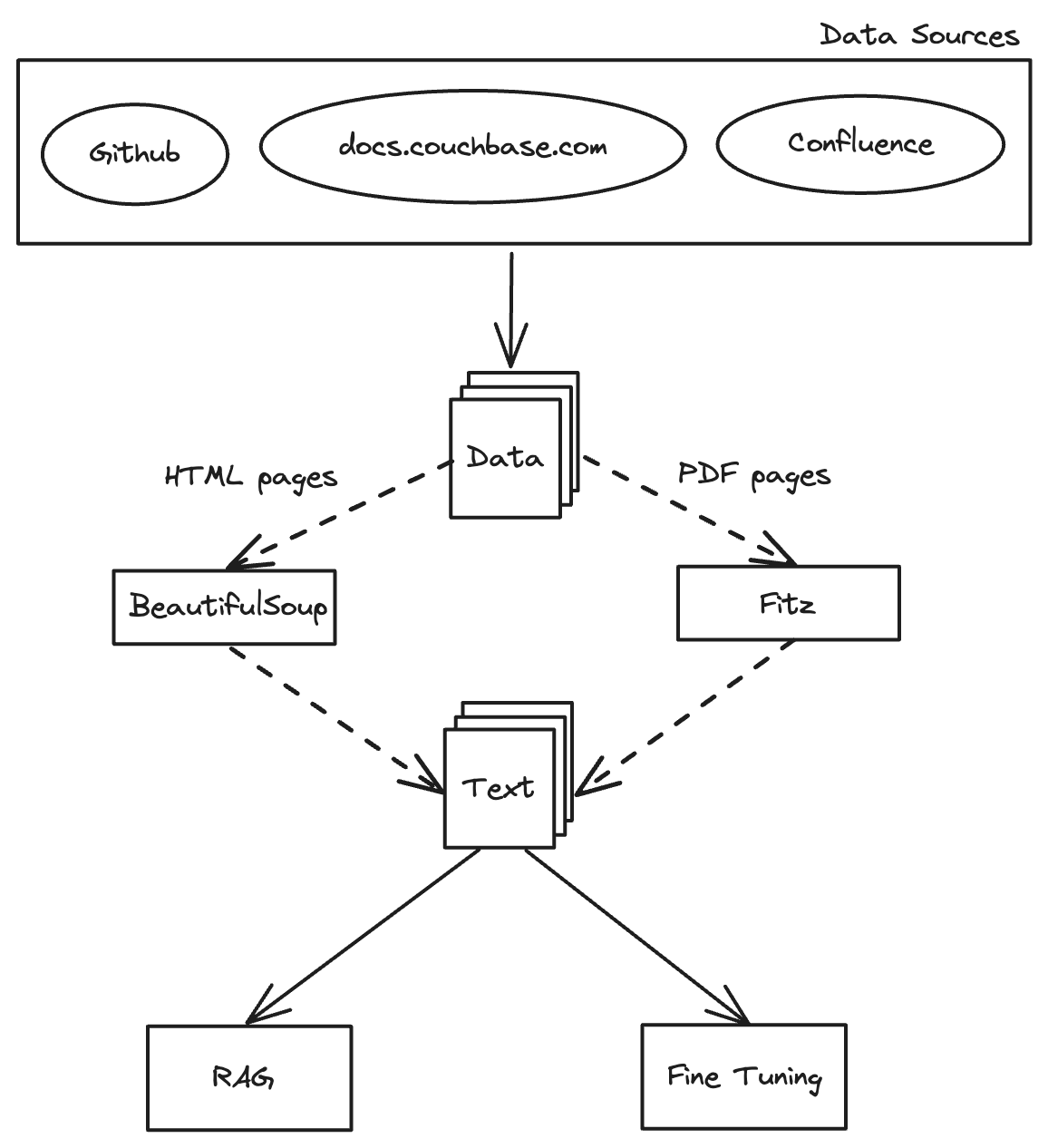
High level overview of converting docs for RAG
Data Collection: The Foundation of RAG
The Magic of Scrapy
Imagine a spider, not the creepy kind, but a diligent librarian spider in the massive library of the internet. This spider, embodied by Scrapy’s Spider class, starts at the entrance (the starting URL) and methodically visits every room (webpage), collecting precious books (HTML pages). Whenever it finds a door to another room (a hyperlink), it opens it and continues its exploration, ensuring no room is left unchecked. This is how Scrapy works—systematically and meticulously gathering every piece of information.
Leveraging Scrapy for Data Collection
Scrapy is a Python-based framework designed to extract data from websites. It’s like giving our librarian spider superpowers. With Scrapy, we can build web spiders that navigate through web pages and extract desired information with precision. In our case, we deploy Scrapy to crawl the Couchbase documentation website and download HTML pages for further processing and analysis.
Setting Up Your Scrapy Project
Before our spider can start its journey, we need to set up a Scrapy project. Here’s how you do it:
- Install Scrapy: If you haven’t already installed Scrapy, you can do so using pip:
1pip install scrapy
- Create a New Scrapy Project: Set up your new Scrapy project with the following command:
1scrapy startproject couchbase_docs
Crafting the Spider
With the Scrapy project set up, we now create the spider that will crawl through the Couchbase documentation website and download HTML pages. Here’s how it looks:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from pathlib import Path import scrapy class CouchbaseSpider(scrapy.Spider): name = "couchbase" start_urls = ["https://docs.couchbase.com/home/index.html",] def parse(self, response): # Download HTML content of the current page page = response.url.split("/")[-1] filename = f"{page}.html" Path(filename).write_bytes(response.body) self.log(f"Saved file {filename}") # Extract links and follow them for href in response.css("ul a::attr(href)").getall(): if href.endswith(".html") or "docs.couchbase.com" in href: yield response.follow(href, self.parse) |
Running the Spider
To run the spider and initiate the data collection process, execute the following command within the Scrapy project directory:
|
1 |
scrapy crawl couchbase |
This command will start the spider, which will begin crawling the specified URLs and saving the HTML content. The spider extracts links from each page and follows them recursively, ensuring comprehensive data collection.
By automating data collection with Scrapy, we ensure all relevant HTML content from the Couchbase documentation website is retrieved efficiently and systematically, laying a solid foundation for further processing and analysis.
Extracting Text Content: Transforming Raw Data
After collecting HTML pages from the Couchbase documentation website, the next crucial step is to extract the text content. This transforms raw data into a usable format for analysis and further processing. Additionally, we may have PDF files containing valuable data, which we’ll also extract. Here, we’ll discuss how to use Python scripts to parse HTML files and PDFs, extract text data, and store it for further processing.
Extracting Text from HTML Pages
To extract text content from HTML pages, we’ll use a Python script that parses the HTML files and retrieves text data enclosed within <p> tags. This approach captures the main body of text from each page, excluding any HTML markup or structural elements.
Python Function for Text Extraction
Below is a Python function that demonstrates how to extract text content from HTML pages and store it in text files:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from bs4 import BeautifulSoup def get_data(html_content): soup = BeautifulSoup(html_content, "html.parser") title = str(soup).split('<title>')[1].split('</title>')[0] if " | Couchbase Docs" in title: title = title[:(title.index(" | Couchbase Docs"))].replace(" ", "_") else: title = title.replace(" ", "_") data = "" lines = soup.find_all('p') for line in lines: data += " " + line.text return title, data |
How to Use?
To use the get_data() function, incorporate it into your Python script or application and provide the HTML content as a parameter. The function will return the extracted text content.
|
1 2 3 4 |
html_content = '<html><head><title>Sample Page</title></head><body><p>This is a sample paragraph.</p></body></html>' title, text = get_data(html_content) print(title) # Output: Sample_Page print(text) # Output: This is a sample paragraph. |
Extracting Text Content from PDFs
For extracting text content from PDFs, we’ll use a Python script that reads a PDF file and retrieves its data. This process ensures that all relevant textual information is captured for analysis.
Python Function for Text Extraction
Below is a Python function that demonstrates how to extract text content from PDFs:
|
1 2 3 4 5 6 7 8 |
from PyPDF2 import PdfReader def extract_text_from_pdf(pdf_file): reader = PdfReader(pdf_file) text = '' for page in reader.pages: text += page.extract_text() return text |
How to Use?
To use the extract_text_from_pdf() function, incorporate it into your Python script or application and provide the PDF file path as a parameter. The function will return the extracted text content.
|
1 2 |
pdf_path = 'sample.pdf' text = extract_text_from_pdf(pdf_path) |
With the text content extracted and saved, we’ve completed the process of getting data from the Couchbase documentation.
Chunking: Making Data Manageable
Imagine you have a lengthy novel and you want to create a summary. Instead of reading the entire book at once, you break it down into chapters, paragraphs, and sentences. This way, you can easily understand and process each part, making the task more manageable. Similarly, chunking in text processing helps in dividing large texts into smaller, meaningful units. By organizing text into manageable chunks, we can facilitate easier processing, retrieval, and analysis of information.
Semantic and Content Chunking for RAG
For Retrieval-Augmented Generation (RAG), chunking is particularly important. We implemented both semantic and content chunking methods to optimize the data for the RAG process, which involves retrieving relevant information and generating responses based on that information.
Recursive Character Text Splitter

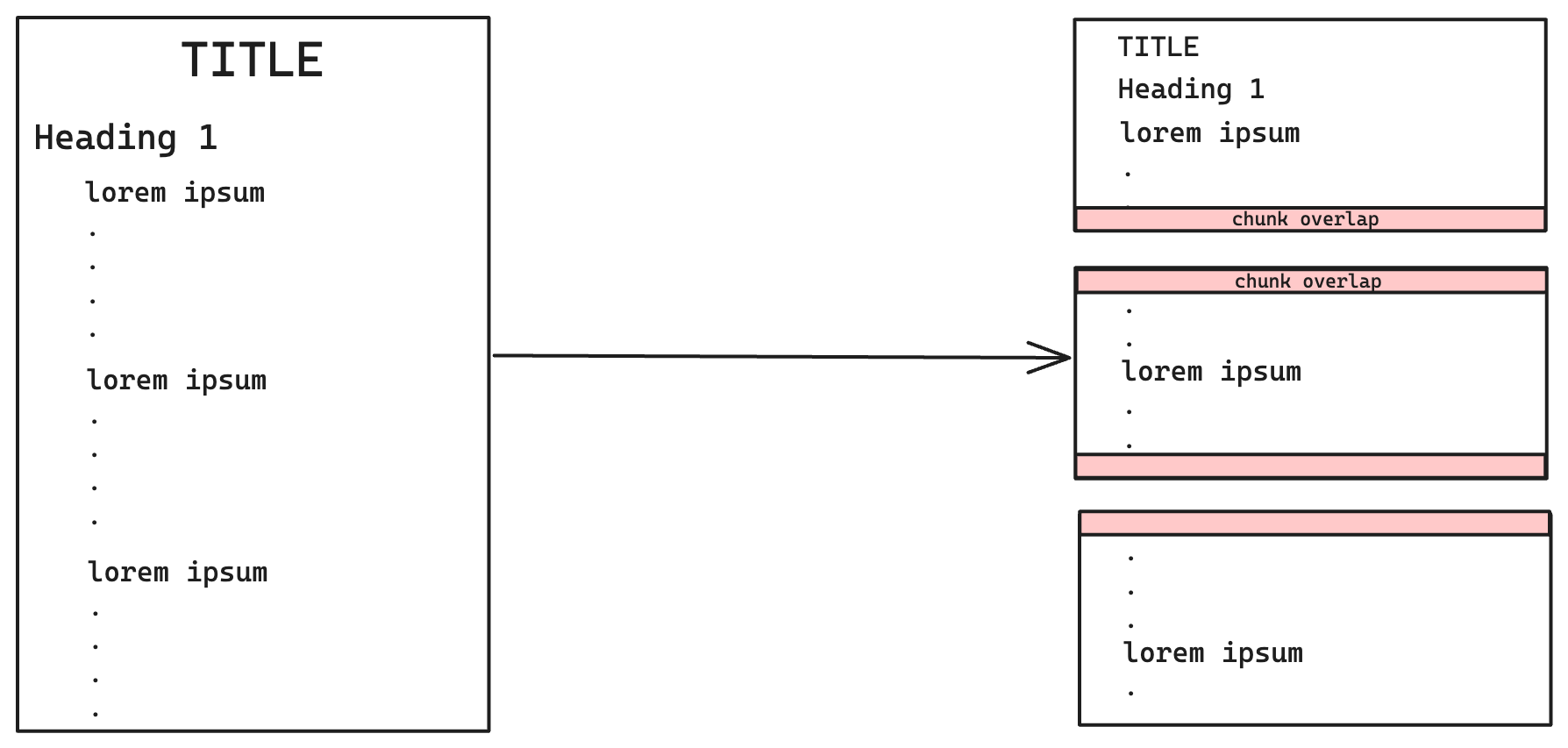
Recursive character text splitter chunking by Langchain involves breaking down a piece of text into smaller chunks using recursive patterns within the characters of the text. This technique utilizes separators such as \n\n (double newline), \n (newline), (space), and "" (empty string).
Semantic Chunking


Semantic chunking is a text processing technique that focuses on grouping words or phrases based on their semantic meaning or context. This approach enhances understanding by creating meaningful chunks that capture the underlying relationships in the text. It is particularly useful for tasks that require detailed analysis of text structure and content organization.
Implementation of Semantic and Content Chunking
For our project, we implemented both semantic and content chunking methods. Semantic chunking preserves the hierarchical structure of the text, ensuring that each chunk maintains its contextual integrity. Content chunking was applied to remove redundant chunks and optimize storage and processing efficiency.
Python Implementation
Here’s a Python implementation of semantic and content chunking:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import hashlib from langchain.text_splitter import RecursiveCharacterTextSplitter # Global set to store unique chunk hash values across all files global_unique_hashes = set() def hash_text(text): # Generate a hash value for the text using SHA-256 hash_object = hashlib.sha256(text.encode()) return hash_object.hexdigest() def chunk_text(text, title, Chunk_size=2000, Overlap=50, Length_function=len, debug_mode=0): global global_unique_hashes chunks = RecursiveCharacterTextSplitter( chunk_size=Chunk_size, chunk_overlap=Overlap, length_function=Length_function ).create_documents([text]) if debug_mode: for idx, chunk in enumerate(chunks): print(f"Chunk {idx+1}: {chunk}\n") print('\n') # Deduplication mechanism unique_chunks = [] for chunk in chunks: chunk_hash = hash_text(chunk.page_content) if chunk_hash not in global_unique_hashes: unique_chunks.append(chunk) global_unique_hashes.add(chunk_hash) for sentence in unique_chunks: sentence.page_content = title + " " + sentence.page_content return unique_chunks |
These optimized chunks are then embedded and stored in the Couchbase cluster for efficient retrieval, ensuring seamless integration with the RAG process.
By employing both semantic and content chunking techniques, we effectively structured and optimized textual data for the RAG process and storage in the Couchbase cluster. The next step is to embed the chunks we just generated.
Embedding Chunks: Mapping the Galaxy of Data
Imagine each chunk of text as a star in a vast galaxy. By embedding these chunks, we assign each star a precise location in this galaxy, based on its characteristics and relationships with other stars. This spatial mapping allows us to navigate the galaxy more effectively, finding connections and understanding the broader universe of information.
Embedding Text Chunks for RAG
Embedding text chunks is a crucial step in the Retrieval-Augmented Generation (RAG) process. It involves transforming text into numerical vectors that capture the semantic meaning and context of each chunk, making it easier for machine learning models to analyze and generate responses.
Utilizing the BAAI Model BGE-M3
To embed the chunks, we use the BAAI model BGE-M3. This model is capable of embedding text into a high-dimensional vector space, capturing the semantic meaning and context of each chunk.
Embedding Function
The embedding function takes the chunks generated from the previous step and embeds each chunk into a 1024-dimensional vector space using the BAAI model BGE-M3. This process enhances the representation of each chunk, facilitating more accurate and contextually rich analysis.
Python Script for Embedding
Here’s a Python script that demonstrates how to embed text chunks using the BAAI model BGE-M3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import json import numpy as np from json import JSONEncoder from baai_model import BGEM3FlagModel embed_model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True) class NumpyEncoder(JSONEncoder): def default(self, obj): if isinstance(obj, np.ndarray): return obj.tolist() return JSONEncoder.default(self, obj) def embed(chunks): embedded_chunks = [] for sentence in chunks: emb = embed_model.encode(str(sentence.page_content), batch_size=12, max_length=600)['dense_vecs'] embedding = np.array(emb) np.set_printoptions(suppress=True) json_dump = json.dumps(embedding, cls=NumpyEncoder) embedded_chunk = { "data": str(sentence.page_content), "vector_data": json.loads(json_dump) } embedded_chunks.append(embedded_chunk) return embedded_chunks |
How to Use?
To use the embed() function, incorporate it into your Python script or application and provide the chunks generated from the previous steps as input. The function will return a list of embedded chunks.
|
1 2 3 4 5 6 7 |
chunks = [ # Assume chunks is a list of text chunks generated previously {"page_content": "This is the first chunk of text."}, {"page_content": "This is the second chunk of text."} ] embedded_chunks = embed(chunks) |
These optimized chunks, now embedded in a high-dimensional vector space, are ready for storage and retrieval, ensuring efficient utilization of resources and seamless integration with the RAG process. By embedding the text chunks, we transform raw text into a format that machine learning models can efficiently process and analyze, enabling more accurate and contextually aware responses in the RAG system.
Storing Embedded Chunks: Ensuring Efficient Retrieval
Once the text chunks have been embedded, the next step is to store these vectors in a database. These embedded chunks can be pushed into vector databases or traditional databases with vector search support, such as Couchbase, Elasticsearch, or Pinecone, to facilitate efficient retrieval for Retrieval-Augmented Generation (RAG) applications.
Vector Databases
Vector databases are designed specifically to handle and search through high-dimensional vectors efficiently. By storing embedded chunks in a vector database, we can leverage advanced search capabilities to quickly retrieve the most relevant information based on the context and semantic meaning of queries.
Integrating with RAG Applications
With the data prepared and stored, it is now ready to be used in RAG applications. The embedded vectors enable these applications to retrieve contextually relevant information and generate more accurate and meaningful responses, enhancing the overall user experience.
Conclusion
By following this guide, we have successfully prepared data for Retrieval-Augmented Generation. We covered data collection using Scrapy, text content extraction from HTML and PDFs, chunking techniques, and embedding text chunks using the BAAI model BGE-M3. These steps ensure that the data is organized, optimized, and ready for use in RAG applications.
For more such technical and engaging content, check out other vector search-related blogs on our website and stay tuned for the next part in this series.