Welcome back everyone, this will be the last post in this series around sizing. In the previous posts I provided an overview of the considerations when sizing a Couchbase Server cluster, a deeper look at how various features/versions affect this sizing and provided some specific hardware considerations and recommendations.
In this last post, I will be discussing the various metrics that should be used to understand the sizing needs of a running Couchbase Server cluster. I’ll also attempt to provide guidance around thresholds and alerts where appropriate. Grab a coffee, this is gonna be a long one…
After you’ve used the first three posts to understand what your initial sizing should be and have moved into production, it’s very important to continue monitoring your cluster and making any sizing changes related to that monitoring. One of the widely accepted benefits of Couchbase Server is the ability to upgrade and expand without any disruption to your application and this is used heavily across our entire customer base.
As a quick recap, the 5 main factors that we used for sizing in the first place are the same 5 that we will be monitoring:
- RAM
- Disk (IO and space)
- CPU
- Network
- Data Distribution
Many metrics will come directly from within Couchbase itself and are related only to our software. However, it is also important to have extensive monitoring of the system from a perspective outside of Couchbase (for the first 4). Also keep in mind that while many metrics get aggregated across the whole cluster (per bucket) and that is usually the easiest way for a human to consume them, everything is happening on a per-node/per-bucket basis and so it is important to monitor at the granularity of a single node. Tying these all together into a centralized monitoring system would be the best approach.
Tracking and Thresholds
Every application is going to be a little bit different and so the values and behaviors of these statistics will vary. It’s up to the administrator to understand which ones are important for their application, and at what levels they should be concerned about.
You should also be expecting that each node has basically the same values (+/-) across all these metrics and possibly create some alert if any one node diverges by too much.
While a hard threshold for most of these is certainly valuable, in many cases it makes more sense to track these metrics over time so that you can be prepared with sizing changes before reaching any critical point. This also allows you to gather accurate baselines for what you should be expecting.
For each statistic below I’ve tried to give a sense of what levels and/or thresholds would be appropriate for different classes of application. Please don’t hesitate to leverage the hundreds of man years of experience built up within Couchbase, Inc. to answer any questions specific to your application.
Reacting to Changes
You’ll see below that I don’t give a specific “do this” action item for each area. I take the approach that it’s more important to understand what each value means and then use the combination of everything to decide whether a change is necessary. If any of the below values are not within acceptable bounds for your application, it is important to go back through the sizing calculations and adjust accordingly. In almost all situations where more resources are needed, the answer will be to add one or more nodes.
Summary
First, let’s take a look at the “Summary” section of Couchbase’s monitoring graphs:
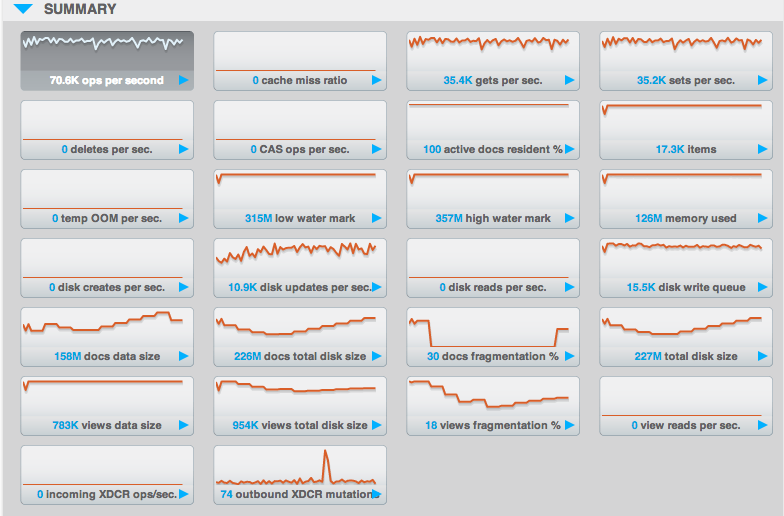
This set of statistics should be your first point of reference for monitoring Couchbase in general, as well as for sizing. It is designed to give you a high level view across many areas and we will be using many of these metrics later on in the discussion. You’ll see that I bring in some statistics that are not covered directly here but this is a great place to start, if you are looking for a starting point to import metrics into your own systems.
You’ll see a proportional relationship between the importance of each sizing factor and the number of metrics that we have to monitor it.
RAM
As you’ve no doubt recognized at this point, RAM is usually one of the most important factors related to sizing for Couchbase and is also the one that can change most dramatically based upon workload, dataset size or other factors.
There are a few different ways of looking at the memory usage within Couchbase and many are interrelated:
- “items” is the number of active documents in a particular bucket (excludes replicas). It is an indirect indication of how much memory is being used, and is also one of the primary values we use for our sizing calculations. It’s not always the most useful to monitor on an ongoing basis though.
- “memory used”: This is the memory usage metric for Couchbase and describes how much memory the software thinks it is using. This is the value that will be used to control ejections and OOM messages. (you’ll sometimes hear our engineers refer to this as “mem_used”…it’s the same)
- “high water mark” is very closely related to “memory used” and you may wish to track them together on a graph. This value tells you at what point the node will begin ejecting data.
- You always want “memory used” to be below the “high water mark”. Some applications may expect it to go slightly over but then come back down again as data is ejected, while others may expect it never to reach the “high water mark”.
- It may also be important to monitor this value against the actual amount of RAM being used by the “memcached” process within the operating system. There are a few cases where these two diverge and keeping an eye on them is important. Anything over 10% divergence would warrant some investigation, though some systems may want to allow higher percentages before taking any action.
- Working set:
- “cache miss ratio”: This is a percentage of the number of reads being served from disk as opposed to from RAM. A value of 0 means all reads are coming from RAM, while anything higher than that indicates some reads are coming from disk.
- For applications that expect everything to be served from RAM, this should always be 0.
- For applications that expect this to be non-0, it should ideally be as low as possible, most deployments are under 1% but some accept upwards of 10%. SSD’s versus spinning disks have a big effect on what is a reasonable value.
- “active docs resident %”: This is the percentage of items currently cached in RAM. 100% means all items are cached in RAM while anything less than that indicates some items have been ejected.
- Some applications expect that this is always 100% and will alert if it goes below.
- Other applications expect this to be something lower than 100%, but the actual value is up to you. I would generally recommend not going below 30% unless your application is quite comfortable with it.
- “cache miss ratio”: This is a percentage of the number of reads being served from disk as opposed to from RAM. A value of 0 means all reads are coming from RAM, while anything higher than that indicates some reads are coming from disk.
- Note that while “active docs resident %” may be significantly less than 100%, the “cache miss ratio” may still be within acceptable range depending on the working set of your application.
- “temp OOM per sec.” is a measure of how many write operations are failing due to an “out of memory” situation within the node/bucket. It will only occur if “memory used” reaches 90% of the total bucket quota.
- Unless explicitly expected, anything non-0 here should be considered very bad. However, this situation can be avoided by appropriately monitoring “memory used” as stated above.
Outside of the Couchbase specific metrics, you’ll also want to be monitoring:
- The overall free RAM available on the node. Keep in mind that Linux has some funky ways of expressing what “free” actually is.
- Alert if it goes below 1-2GB.
- Swap usage. While Linux is expected to use a little bit of swap under normal conditions, any excessive amount of swap usage or excessive swapping (look at the output of ‘vmstat’) would be considered cause for concern
- The memory usage of the beam.smp process (erl.exe on Windows). Previous versions had some potentially excessive growth possible in this process. Those issues have been fixed as of 2.5 but it’s still a good idea to keep an eye on.
- More than 4.5GB would be inappropriate here.
Disk
Split into IO versus space, overall disk resource sizing is also critically important. Depending on the nature of the workload, it can sometimes be more important than RAM.
Taking IO first, we have a few metrics worthy of tracking:
- “disk write queue”: This is the metric for understanding whether there is sufficient disk IO on a node. While there are many processes that contend for disk IO (data writing, compaction, views, XDCR, local backups, etc), we use the “disk write queue” as a general meter as insufficient IO will cause items to be written to disk slower (regardless of cause) and should be resolved.
- Anything approaching 1M items per-bucket per-node should be cause for concern, though many applications expect it to be much lower for their workload. This should be expected to be higher during a rebalance.
- This metric is also important from a trending perspective since it will be going up and down in most cases. Many applications accept it spiking during their peak workload (still should be <1M) but it’s important that it goes down during periods of lower load. A constantly rising queue over time indicates that there isn’t enough disk IO overall.
- “disk creates per sec”, “disk updates per sec”, “disk reads per sec”: These are all indications of the read/write rate and can be used in future sizing calculations
For space:
- “docs total disk size” and “views total disk size”: These measure the amount of disk space in use under the data directory and the views directory (by best practice, these should be on separate partitions). This is different than “disk data size” or “views data size”, which measure the amount of active Couchbase data within those files. The difference between these two cause “docs fragmentation %” and “views fragmentation %” which then potentially trigger compaction.
- It is very important to ensure enough available disk space not only for storing data, but also for the append-only nature of the file format, performing compaction, taking backups, etc. An appropriate alerting level would be around 75% disk usage with a critical alert at 90%.
Outside of Couchbase, the operating system will be monitoring not only disk space (think ‘df’) but also disk utilization (think ‘iostat’).
CPU
As you’ve seen in previous posts, CPU is very rarely an important area of sizing Couchbase. With that said, it’s still important to monitor the total CPU usage of a node and the CPU usage of the memcached and beam.smp/erl.exe processes.
Another important aspect of CPU usage is the distribution across multiple cores. While not related to sizing necessarily, an imbalance of CPU usage may require some investigation.
Network
While network bandwidth and latency does have a big effect on the overall performance of the system, it’s very rare for this to deviate from the expected levels and cause any issues.
The main value that we use within Couchbase to ensure a healthy network is related to the inter-node replication queue. While not present in the above “Summary”, this is known casually as the “TAP queue” and is represented by “items” within the “TAP QUEUES” section of the UI:
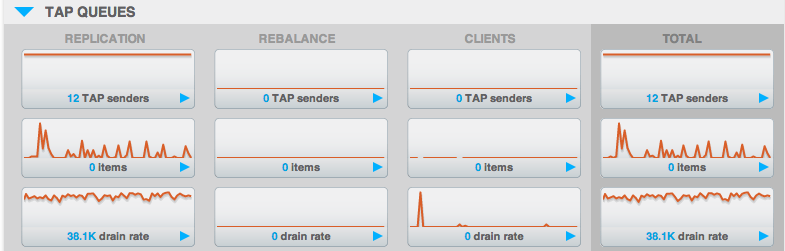
This value will almost always be 0 and even a few above 0 is not cause for concern. If this should rise to over 200 per-node, and especially if it continues rising, may indicate either a networking problem or something else within the cluster slowing down the replication.
Outside of Couchbase, you’ll also want to keep a general eye on the network bandwidth usage between Couchbase nodes and between those nodes and your application servers. Also potentially important is the number of TCP connections to the various network ports, mostly from the perspective of client-to-server communication.
Data Distribution
At the bottom of the list for good reason, there’s really not much to monitor here related to sizing. It’s also the only factor that really makes sense to look at across the whole cluster as opposed to individual nodes.
If we look at the “vbucket resources” section of the UI:
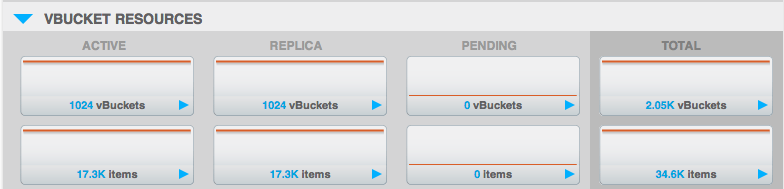
We can see how many active and how many replica “vBuckets” are present for this bucket. “Active vBuckets” should always be 1024 and “Replica vBuckets” should always be 1024*(number of replicas). If they are not, that means there is some data either unavailable or unreplicated and immediate action is required. This usually happens after a failure/failover and will require a rebalance to return to normal.
The broad recommendation of always having at least 3 nodes in the cluster holds true as well.
XDCR
If you’re using XDCR with Couchbase, the most important metric to keep an eye on is the XDCR mutation queue – “outbound XDCR mutations”. This is an indication of how many items are waiting to be replicated to buckets that are acting as destinations of this one. Like the disk write queue, this is expected to grow and shrink under load but is important to ensure eventually gets near zero over time and does not continuously grow higher and higher.
Virtualization/Cloud
With no exceptions, the discussion above applies equally to all environments across physical hardware, virtual machines and cloud deployments. The actual values may vary and certainly your thresholds and expected baselines will be different as well.
The main addition to this puzzle for virtualized and cloud environments is the impact of the underlying systems and hypervisors. I’ve provided some specific deployment guidelines in the previous post of this series so I won’t recap here. In terms of monitoring, all of the same “outside of Couchbase” apply to the underlying system.
One interesting intersection between the two deals with “stolen time”.
Conclusion
To bring this all together into one place, I’ve brought all these metrics together in one place. Not all may applicable to your environment, but they all “might” be and should be understood for your application:
| Metrics within Couchbase: | External to Couchbase | |
|---|---|---|
| RAM: |
|
|
| Disk IO: |
|
|
| Disk Space: |
|
|
| CPU: |
|
|
| Network: |
|
|
| Data Distribution: |
|
|
| XDCR: |
|
Thanks for sticking with me on this journey, I hope it’s been useful. Please don’t hesitate to reach out to me directly or the Couchbase team if you have any questions or concerns or would like some specific attention on your environment.
Hi, thanks for these articles. I have a question which I can\’t figure out if it\’s possible.
Given Server 1, 2 and 3, can I have Couchbase instances A1, B1, C1 on
Server 1; A2, B2, C2 on Server 2 and A3, B3 and C3 on Server 3, so that
A1, A2, A3 forms a cluster, B1, B2 and B3 forms a cluster, etc?
This would be required for production purposes.
Thanks!
Hi Renault, apologies for the delay in getting back to you. There\’s no technical reason why this would be a problem, but it would go against our general best practices of keeping these workloads isolated. It would also create quite an administration task for you to remember that there are 3 nodes on each physical server that are part of 3 different clusters and need to be managed/rebalanced separately.
[…] third entry in this series goes into different hardware and infrastructure choices. Finally, the fourth entry looks at the metrics that you can monitor both within and external to Cocuhbase for understanding […]