The premise is very simple: in the world of disparate technologies where one does not works or integrates well together, Couchbase & Confluent Kafka are amazing products and are extremely complementary to each other. Couchbase is linearly scalable, distributed NoSQL JSON database. Its primary use case is for any application/web service which requires single digit ms latency read/write/update response. It can be used as System of Record(SoR) or Caching layer for fast mutating transient data or offloading Db2/Oracle/SQL Server etc so that downstream services can consume data from Couchbase.
Confluent Kafka is full-fledged distributed streaming platform which is also linearly scalable and capable of handling trillions of events in a day. Confluent Platform makes it easy to build real-time data pipelines and streaming applications by integrating data from multiple sources and locations into a single, central Event Streaming Platform for your company.
In this blog post we will cover how seamlessly we can move data out Couchbase and push into a Confluent kafka topic as replication event.
Couchbase Kafka connector transfers documents from Couchbase efficiently and reliably using Couchbase’s internal replication protocol, DCP. Every change to or deletion of the document generates a replication event, which is then sent to the configured Kafka topic.
Kafka connector can be used to move data out of Couchbase and move data from kafka to Couchbase using sink connector. For this blog purpose we will be configuring and using source connector.
At high level the architecture diagram looks like below
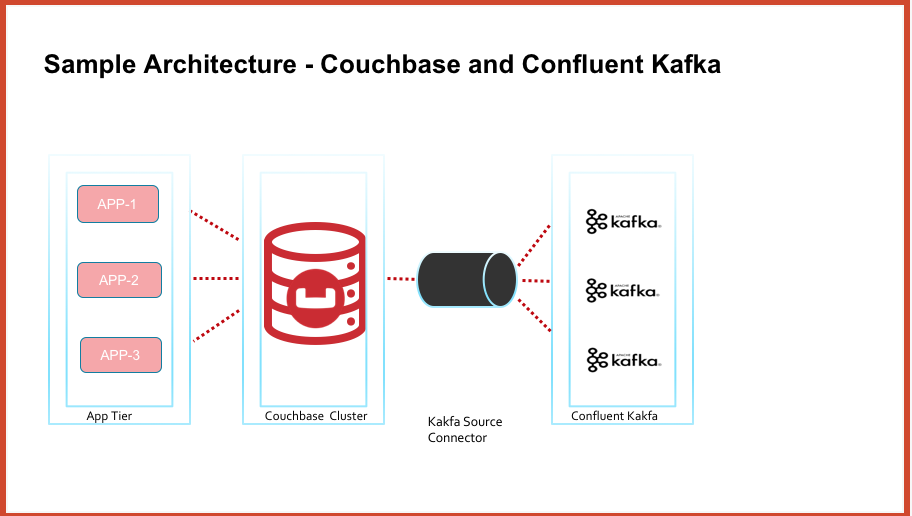
Pre-requisites
Couchbase Cluster running version 5.X or above. Download Couchbase here
Couchbase kafka connector. Download Couchbase kafka connector here
Confluent Kafka. Download Confluent Kafka here
Configuring Couchbase cluster is outside of the scope of this blog post. However we will be discussing configuring Confluent kafka and Couchbase kafka connector to move data out of Couchbase.
Configuring Confluent Kafka
Untar the package downloaded above on a VM/pod. For the purpose of this blog, I have deployed an Ubuntu Pod in kubernetes cluster running on GKE.
Make sure before installing confluent kafka machines needs to have java 8 version.
Install/start kafka
kafka has following processes, which all should be up.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<em class="markup--em markup--p-em">zookeeper is [UP]</em> <em class="markup--em markup--p-em">kafka is [UP]</em> <em class="markup--em markup--p-em">schema-registry is [UP]</em> <em class="markup--em markup--p-em">kafka-rest is [UP]</em> <em class="markup--em markup--p-em">connect is [UP]</em> <em class="markup--em markup--p-em">ksql-server is [UP]</em> <em class="markup--em markup--p-em">control-center is [UP]</em> |
Pod running confluent kafka can be exposed via NodePort service to the local machine/laptop. App pod file is here. Service yaml file is here
|
1 2 3 4 5 |
<em class="markup--em markup--p-em">$ kubectl get svc -n mynamespace</em> <em class="markup--em markup--p-em">NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE</em> <em class="markup--em markup--p-em">app-service ClusterIP 10.51.248.154 <none> 9021/TCP,8083/TCP 115s</em> |
Port-forward the service on local port 9021
|
1 2 3 4 5 |
<em class="markup--em markup--p-em">$ kubectl port-forward service/app-service 9021:9021 -- namespace cbdb</em> <em class="markup--em markup--p-em">Forwarding from 127.0.0.1:9021 -> 9021</em> <em class="markup--em markup--p-em">Forwarding from [::1]:9021 -> 9021</em> |
Hit the URL: https://localhost:9021
Configuring Couchbase Kafka Connector
Unzip the package downloaded from above
|
1 |
<em class="markup--em markup--p-em">$ unzip kafka-connect-couchbase-3.4.5.zip</em> |
|
1 |
<em class="markup--em markup--p-em">$ cd kafka-connect-couchbase-3.4.5/</em>config |
Edit file quickstart-couchbase-source.properties with (atleast) following information
Cluster Connection string
|
1 |
<em class="markup--em markup--p-em">connection.cluster_address=cb-demo-0000.cb-demo.default.svc.cluster.local</em> |
bucket name and bucket access credentials
|
1 2 3 |
<em class="markup--em markup--p-em">connection.bucket=travel-sample connection.username=Administrator connection.password=pa$$word</em> |
Note: Enter credentials for bucket you want to move data too. In my example, I am using travel-sample bucket, with bucket user credentials.
Export the variable CONFLUENT_HOME
|
1 |
<em class="markup--em markup--p-em">export CONFLUENT_HOME=/root/confluent-5.2.1</em> |
Start the kafka connector
|
1 |
<em class="markup--em markup--p-em">env CLASSPATH=./* connect-standalone $CONFLUENT_HOME/etc/schema-registry/connect-avro-standalone.properties config/quickstart-couchbase-source.properties</em> |
When connector is started it created a kafka topic with the name cb-topic and we can see all documents from Couchbase travel-sample bucket get transferred to kafka topic cb-topic as events

Conclusion
In the matter of minutes one can integrate Couchbase and Confluent Kafka. Ease of use, deployment and supportability are key factors in using technology. In this blog post we saw that one can seamlessly move data out of Couchbase into a kafka topic. Once data is in kafka topic, then using KSQL one can create real-time stream processing applications matching business needs.
References:
- https://docs.confluent.io/current/quickstart/ce-quickstart.html#ce-quickstart
- https://docs.couchbase.com/kafka-connector/3.4/quickstart.html
- https://docs.couchbase.com/kafka-connector/3.4/source-configuration-options.html