JSON data modeling is a vital part of using a document database like Couchbase. Beyond understanding the basics of JSON, there are two key approaches to modeling relationships between data that will be covered in this blog post.
The examples in this post will build on the invoices example that I showed in CSV tooling for migrating to Couchbase from Relational.
Imported Data Refresher
In the previous example, I started with two tables from a relational database: Invoices and InvoicesItems. Each invoice item belongs to an invoice, which is done with a foreign key in a relational database.
I did a very straightforward (naive) import of this data into Couchbase. Each row became a document in a “staging” bucket.

Next, we must decide if that JSON data modeling design is appropriate or not (I don’t think it is, as if the bucket being called “staging” didn’t already give that away).
Two Approaches to JSON data modeling of relationships
With a relational database, there is really only one approach: normalize your data. This means separate tables with foreign keys linking the data together.
With a document database, there are two approaches. You can keep the data normalized or you can denormalize data by nesting it into its parent document.
Normalized (separate documents)
An example of the end state of the normalized approach represents a single invoice spread over multiple documents:
|
1 2 3 4 5 6 7 8 9 10 11 |
key - invoice::1 { "BillTo": "Lynn Hess", "InvoiceDate": "2018-01-15 00:00:00.000", "InvoiceNum": "ABC123", "ShipTo": "Herman Trisler, 4189 Oak Drive" } key - invoiceitem::1811cfcc-05b6-4ace-a52a-be3aad24dc52 { "InvoiceId": "1", "Price": "1000.00", "Product": "Brake Pad", "Quantity": "24" } key - invoiceitem::29109f4a-761f-49a6-9b0d-f448627d7148 { "InvoiceId": "1", "Price": "10.00", "Product": "Steering Wheel", "Quantity": "5" } key - invoiceitem::bf9d3256-9c8a-4378-877d-2a563b163d45 { "InvoiceId": "1", "Price": "20.00", "Product": "Tire", "Quantity": "2" } |
This lines up with the direct CSV import. The InvoiceId field in each invoiceitem document is similar to the idea of a foreign key, but note that Couchbase (and distributed document databases in general) do not enforce this relationship in the same way that relational databases do. This is a trade-off made to satisfy the flexibility, scalability, and performance needs of a distributed system.
Note that in this example, the “child” documents point to the parent via InvoiceId. But it could also be the other way around: the “parent” document could contain an array of the keys of each “child” document.
Denormalized (nested)
The end state of the nested approach would involve just a single document to represent an invoice.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
key - invoice::1 { "BillTo": "Lynn Hess", "InvoiceDate": "2018-01-15 00:00:00.000", "InvoiceNum": "ABC123", "ShipTo": "Herman Trisler, 4189 Oak Drive", "Items": [ { "Price": "1000.00", "Product": "Brake Pad", "Quantity": "24" }, { "Price": "10.00", "Product": "Steering Wheel", "Quantity": "5" }, { "Price": "20.00", "Product": "Tire", "Quantity": "2" } ] } |
Note that “InvoiceId” is no longer present in the objects in the Items array. This data is no longer foreign—it’s now domestic—so that field is not necessary anymore.
JSON Data Modeling Rules of Thumb
You may already be thinking that the second option is a natural fit in this case. An invoice in this system is a natural aggregate-root. However, it is not always straightforward and obvious when and how to choose between these two approaches in your application.
Here are some rules of thumb for when to choose each model:
| If … | Then consider… |
|---|---|
|
Relationship is 1-to-1 or 1-to-many |
Nested objects |
|
Relationship is many-to-1 or many-to-many |
Separate documents |
|
Data reads are mostly parent fields |
Separate document |
|
Data reads are mostly parent + child fields |
Nested objects |
|
Data reads are mostly parent or child (not both) |
Separate documents |
|
Data writes are mostly parent and child (both) |
Nested objects |
Modeling example
To explore this deeper, let’s make some assumptions about the invoice system we’re building.
- A user usually views the entire invoice (including the invoice items)
- When a user creates an invoice (or makes changes), they are updating both the “root” fields and the “items” together
- There are some queries (but not many) in the system that only care about the invoice root data and ignore the “items” fields
Then, based on that knowledge, we know that:
- The relationship is 1-to-many (a single invoice has many items)
- Data reads are mostly parent + child fields together
Therefore, “nested objects” seems like the right design.
Please remember that these are not hard and fast rules that will always apply. They are simply guidelines to help you get started. The only “best practice” is to use your own knowledge and experience.
Transforming staging data with N1QL
Now that we’ve done some JSON Data Modeling exercises, it’s time to transform the data in the staging bucket from separate documents that came directly from the relational database to the nested object design.
There are many approaches to this, but I’m going to keep it very simple and use Couchbase’s powerful N1QL language to run SQL queries on JSON data.
Preparing the data
First, create a “operation” bucket. I’m going to transform data and move it to from the “staging” bucket (containing the direct CSV import) to the “operation” bucket.
Next, I’m going to mark the ‘root’ documents with a “type” field. This is a way to mark documents as being of a certain type, and will come in handy later.
|
1 2 3 |
UPDATE staging SET type = 'invoice' WHERE InvoiceNum IS NOT MISSING; |
I know that the root documents have a field called “InvoiceNum” and that the items do not have this field. So this is a safe way to differentiate.
Next, I need to modify the items. They previously had a foreign key that was just a number. Now those values should be updated to point to the new document key.
|
1 2 |
UPDATE staging s SET s.InvoiceId = 'invoice::' || s.InvoiceId; |
This is just prepending “invoice::” to the value. Note that the root documents don’t have an InvoiceId field, so they will be unaffected by this query.
After this, I need to create an index on that field.
Preparing an index
|
1 |
CREATE INDEX ix_invoiceid ON staging(InvoiceId); |
This index will be necessary for the transformational join coming up next.
Now, before making this data operational, let’s run a SELECT to get a preview and make sure the data is going to join together how we expect. Use N1QL’s NEST operation:
|
1 2 3 4 |
SELECT i.*, t AS Items FROM staging AS i NEST staging AS t ON KEY t.InvoiceId FOR i WHERE i.type = 'invoice'; |
The result of this query should be three total root invoice documents.
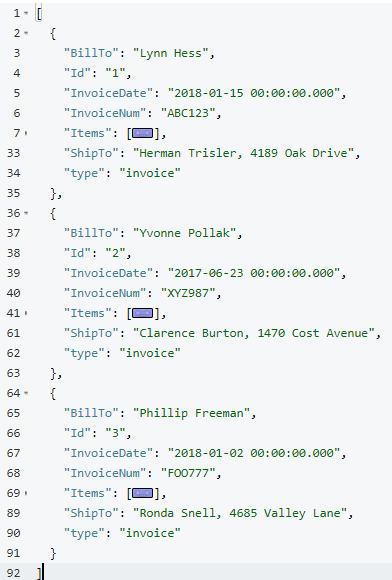
The invoice items should now be nested into an “Items” array within their parent invoice (I collapsed them in the above screenshot for the sake of brevity).
Moving the data out of staging
Once you’ve verified this looks correct, the data can be moved over to the “operation” bucket using an INSERT command, which will just be a slight variation on the above SELECT command.
|
1 2 3 4 5 |
INSERT INTO operation (KEY k, VALUE v) SELECT META(i).id AS k, { i.BillTo, i.InvoiceDate, i.InvoiceNum, "Items": t } AS v FROM staging i NEST staging t ON KEY t.InvoiceId FOR i where i.type = 'invoice'; |
If you’re new to N1QL, there’s a couple things to point out here:
INSERTwill always useKEYandVALUE. You don’t list all the fields in this clause, like you would in a relational database.META(i).idis a way of accessing a document’s key- The literal JSON syntax being SELECTed AS v is a way to specify which fields you want to move over. Wildcards could be used here.
NESTis a type of join that will nest the data into an array instead of at the root level.FOR ispecifies the left hand side of theON KEYjoin. This syntax is probably the most non-standard portion of N1QL, but the next major release of Couchbase Server will include “ANSI JOIN” functionality that will be a lot more natural to read and write.
After running this query, you should have 3 total documents in your ‘operation’ bucket representing 3 invoices.
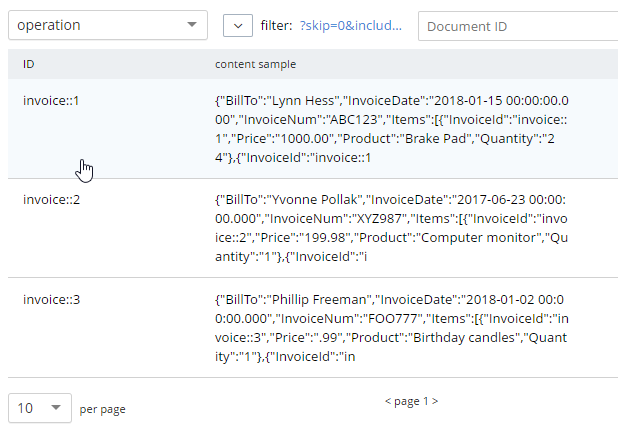
You can delete/flush the staging bucket since it now contains stale data. Or you can keep it around for more experimentation.
Summary
Migrating data straight over to Couchbase Server can be as easy as importing via CSV and transforming with a few lines of N1QL. Doing the actual modeling and making decisions requires the most time and thought. Once you decide how to model, N1QL gives you the flexibility to transform from flat, scattered relational data into an aggregate-oriented document model.
More resources:
- Using Hackolade to collaborate on JSON data modeling.
- Part of the SQL Server series discusses the same type of JSON data modeling decisions
- How Couchbase Beats Oracle, if you’re considering moving some of your data away from Oracle
- Moving from Relational to NoSQL: How to Get Started white paper.
Feel free to contact me if you have any questions or need help. I’m
@mgroves on Twitter. You can also ask questions on the Couchbase Forums. There are N1QL experts there who are very responsive and can help you write the N1QL to accommodate your JSON data modeling.