Kafka is a streaming platform that can be used to stream records to (Kafka sink) and from (Kafka source) data centers. Couchbase has created and supports a Kafka connector that allows you to easily use Couchbase as a source or a sink.
I’ve been working on a complete tutorial for a Customer 360 use case. One part of it involves Kafka. Here’s a high level diagram:
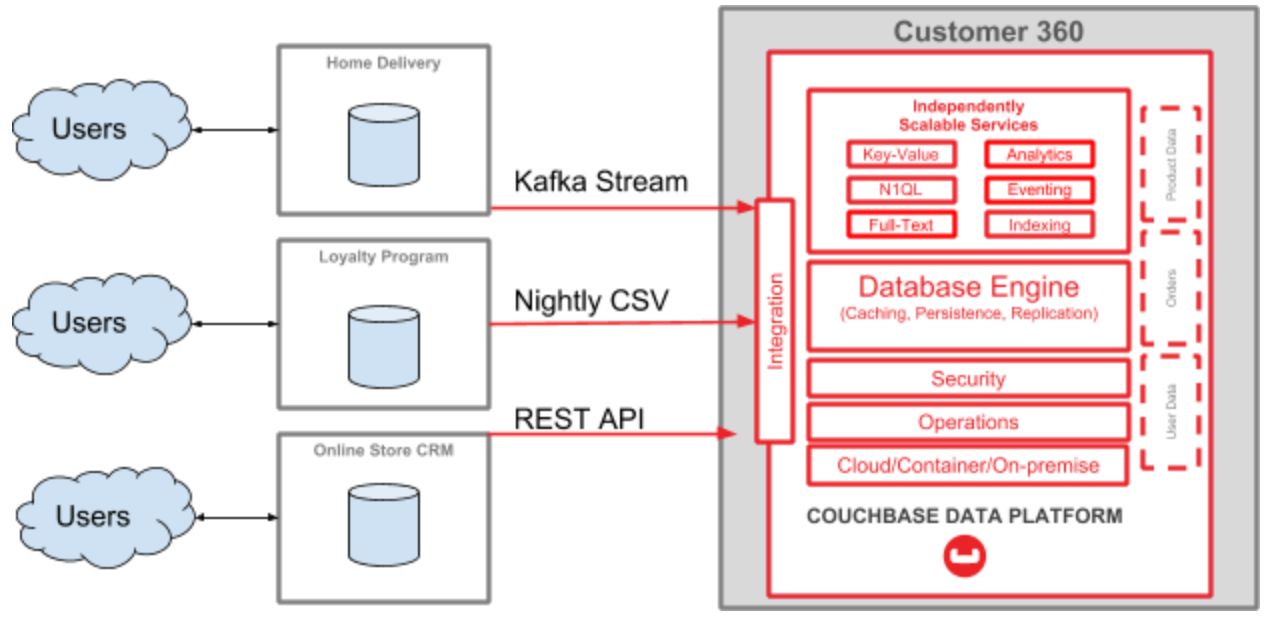
One part of this tutorial is a guide on how to start streaming data from a MySQL database (which is used for a ‘home delivery’ system in an enterprise) into the Couchbase Data platform (which will be used for Customer 360 purposes). For this blog post, I’m focusing on just this part of the diagram:
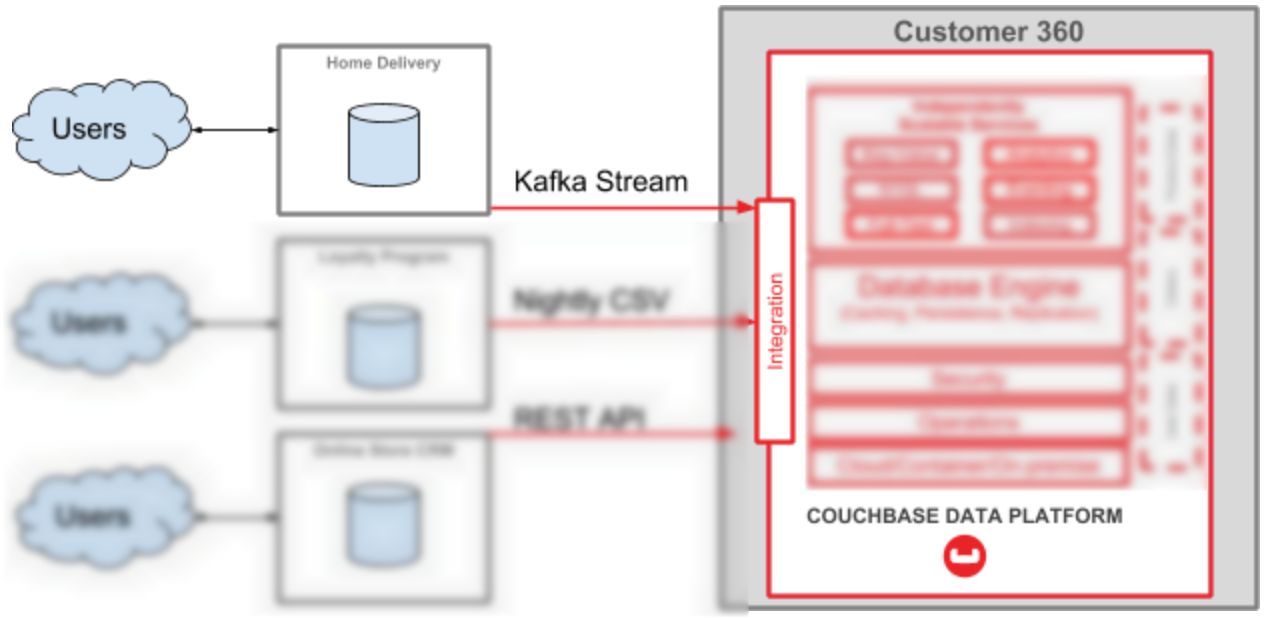
Prerequisites
I started out not knowing much about Kafka, but I was able to piece together a working proof of concept by using:
- Docker. You will need to have Docker installed to complete this tutorial. You may eventually want to move all of this into docker-compose or (more likely) Kubernetes. I am building all of the architecture in this post, but in your enterprise there will be at least some parts that are already deployed.
- Debezium’s quick start tutorial – Debezium is the connector I chose to use to configure a MySQL database as a source.
- Couchbase Docker quickstart – to run a simple Couchbase cluster within Docker
- Couchbase Kafka connector quick start tutorial – This tutorial shows how to setup Couchbase as either a Kafka sink or a Kafka source.
- Dockerfile reference – how to create a custom docker image. This may sound intimidating, but don’t worry, it’s only a couple of lines of text.
Setting up Couchbase
Install Couchbase with Docker:
docker run -d --name db -p 8091-8094:8091-8094 -p 11210:11210 couchbase
You’ll also need to setup that Couchbase cluster as normal. I created a bucket called “staging”.
Running Zookeeper, Kafka, MySQL
For the most part, you’ll just need to follow the Debezium tutorial. Make sure to read through all the details, but the short version is to take these steps:
Run a Zookeeper image (this is required for Kafka):
docker run -it --rm --name zookeeper -p 2181:2181 -p 2888:2888 -p 3888:3888 debezium/zookeeper:0.9
Run a Kafka image (linked to Zookeeper):
docker run -it --rm --name kafka -p 9092:9092 --link zookeeper:zookeeper debezium/kafka:0.9
Start a MySQL database (Debezium supplies a Docker image that already contains some sample data):
docker run -it --rm --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=debezium -e MYSQL_USER=mysqluser -e MYSQL_PASSWORD=mysqlpw debezium/example-mysql:0.9
After this, you can connect to the MySQL database using the above credentials. The Debezium tutorial provides another Docker image for doing that, or you can use the MySQL tool of your choice. You don’t need to do this right now, but eventually you’ll want to connect to it and insert/update data to test the process end-to-end.
Preparing Kafka Connectors
At this point in my journey, I must diverge slightly from the Debezium tutorial. That tutorial shows you how to start a Debezium MySQL Connector (with another Docker image and a REST request). However, I want to introduce the Couchbase Kafka Connector.
The easiest way to do this is to create a custom Docker image. This will use the Debezium Kafka connect image as a base, and simply add the Couchbase Kafka Connect JAR file to it. To do this, create a text file called Dockerfile:
|
1 2 3 4 |
FROM debezium/connect:0.9 # put the kafka-connect-couchbase-3.4.3.jar into # a /kafka/connect/couchbase folder ADD kafka-connect-couchbase-3.4.3.jar /kafka/connect/couchbase/kafka-connect-couchbase-3.4.3.jar |
Once you’ve done that, build the image: docker build . --tag couchbasedebezium. I called the image couchbasedebezium, but you can call it whatever you like. After this completes, run docker images, and couchbasedebezium should appear in your local repository:
|
1 2 3 4 5 6 7 8 9 10 |
PS C:\myfolder> docker images REPOSITORY TAG IMAGE ID CREATED SIZE couchbasedebezium latest a48fa903cc7d 3 days ago 641MB debezium/connect 0.9 5a5e60b3f50a 2 weeks ago 633MB debezium/kafka 0.9 b4b130f4bb9c 2 weeks ago 612MB debezium/zookeeper 0.9 4ba823930ede 2 weeks ago 519MB debezium/example-mysql 0.9 ba801de1fe22 3 weeks ago 372MB couchbase enterprise-6.0.1 5403ed5c6ef4 2 months ago 940MB ... etc ... |
Starting Kafka Connect
To start Kafka Connect:
docker run -it --rm --name connect -p 8083:8083 -e GROUP_ID=1 -e CONFIG_STORAGE_TOPIC=my_connect_configs -e OFFSET_STORAGE_TOPIC=my_connect_offsets -e STATUS_STORAGE_TOPIC=my_connect_statuses --link zookeeper:zookeeper --link kafka:kafka --link mysql:mysql --link db:db couchbasedebezium
This will start a Docker image that we will use to connect Kafka to both MySQL and Couchbase. Notice that I’m using the couchbasedebezium image and I’m also using –link db:db, but otherwise this is identical to the Debezium tutorial.
There are two more steps:
- Tell Kafka Connect to use MySQL as a source.
- Tell Kafka Connect to use Couchbase a sink.
There are multiple ways to do this, but I decided to use Kafka’s REST API.
Connect to MySQL as a source
Create a POST request to http://localhost:8083/connectors/ with the body:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
{ "name": "inventory-connector", "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "tasks.max": "1", "database.hostname": "mysql", "database.port": "3306", "database.user": "debezium", "database.password": "dbz", "database.server.id": "184054", "database.server.name": "dbserver1", "database.whitelist": "inventory", "database.history.kafka.bootstrap.servers": "kafka:9092", "database.history.kafka.topic": "schema-changes.inventory" } } |
This is directly from the Debezium tutorial. Take special note of database.server.name and database.whitelist. After you POST this, data will immediately start flowing from MySQL into Kafka.
Connect to Couchbase as a sink
Create another POST request to http://localhost:8083/connectors/ with the body:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
{ "name": "home-delivery-sink", "config": { "connector.class": "com.couchbase.connect.kafka.CouchbaseSinkConnector", "tasks.max": "2", "topics" : "dbserver1.inventory.customers", "connection.cluster_address" : "db", "connection.timeout.ms" : "2000", "connection.bucket" : "staging", "connection.username" : "Administrator", "connection.password" : "password", "couchbase.durability.persist_to" : "NONE", "couchbase.durability.replicate_to" : "NONE", "key.converter" : "org.apache.kafka.connect.storage.StringConverter", "value.converter" : "org.apache.kafka.connect.json.JsonConverter", "value.converter.schemas.enable" : "false" } } |
This configuration is largely pulled from the Couchbase Quickstart. Instead of being a text file for the command line, it’s an HTTP POST. Take special note of:
connector.class– This is the connector class that lives in the JAR filetopics– The topics that Couchbase will sink from.connection.cluster_address– When I started Couchbase in Docker, I gave it a name of “db”connection.bucket,connection.username,connection.password– These are all settings I created when setting up Couchbase.
Data is now flowing
Now, data should be flowing into your Couchbase bucket. Connect to Couchbase, and you’ll see 4 documents in the staging bucket (this corresponds to the 4 rows of data in the MySQL sample database). Add or update data in the MySQL database and more records will start to roll into the Couchbase bucket automatically.
I went through this whole process on my Live Code stream on Twitch. If you’d like to see this whole process in action, I’ve cut together a highlight reel to show all the steps:
[youtube https://www.youtube.com/watch?v=HCAY7EMm3pg&w=560&h=315]
Resources and next steps
Now that you’ve completed this tutorial, there are other directions you can go to continue exploring.
- Orchestration: this sample contains a lot of Docker images that are run manually. In a production environment, you’d likely want to orchestrate and scale some or all of these pieces with something like Kubernetes. There is a Kubernetes operator for Couchbase Enterprise.
- Customer 360: Streaming data from a MySQL database into Couchbase is just one step in this direction. A Customer 360 application will likely be pulling data from a variety of other databases. Stay tuned to the Couchbase Blog and the Couchbase Tutorials for more information on building a Customer 360 ingestion architecture.
If you have questions for me, you can reach me on Twitter @mgroves, leave a comment below, or tune in to my next Live Code stream.
If you have technical questions about Couchbase or the Couchbase Kafka Connector, be sure to check out the Couchbase Forums.