When we developers hear the term data sprawl, it may sound a little bit like a business term like TCO, ROI and the likes. All these terms have a reality for developers, outside of the analyst and manager realm. So today I want to tell you about the reality of Data Sprawl for developers. How it impacts our work.
Data Sprawl can be summed up as we have data, a tremendous amount, stored in many different data stores. And on top of that, we as developers have to make those datastores interact with each other. And of course the more, the merrier, right 😬?
Usually it’s associated with higher financial costs in:
-
- Infrastructure
- Licenses
- Integration
- Training
- Operational
- Support costs
Separate platforms with multiple interfaces will give you headaches because of:
-
- Independent deployment and management
- Different data model and programming interfaces
- Integration between multiple products
- Support tickets with different vendors
And we need to spend more time, efforts and cost because of:
-
- License & agreement
- Training for Developers and Operations
- Support
- Build API or connector to database
- Purchase infrastructure
It is a little grim when you look at it like this but it is a day-to-day challenge for many companies. And not just with different data workloads, this is also true for the cloud applications.
Let’s take a look at a specific example. I have created an application that uses CRUD from a document database, Cache from a caching store, and search from a fulltext search engine. (GitHub source)
Taking a look at this schema you can basically count every arrow you see as one interaction between different systems that developers have to think about and code.
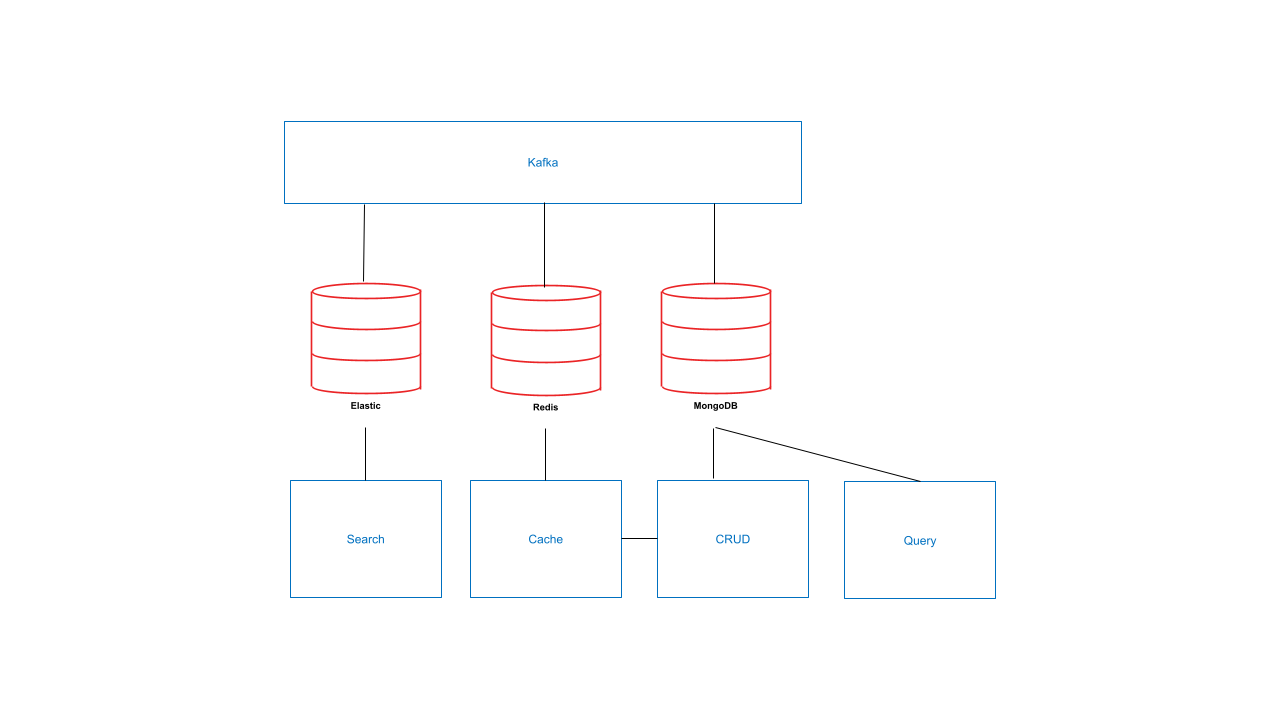
Here we are synchronizing automatically the Cache and Search databases using event streaming. That is 8 interactions and 4 data stores to learn and manage. Because you need to make sure that every store is plugged with the streaming service, and that it gets the right updates, you need to manage the streaming service, the search, cache and data store. You also need to integrate the cache with your CRUD service (ideally with the other services but let’s keep that simple. In short: there is a lot to do.
We can limit those interactions by getting rid of the streaming services and making sure other services are updated manually. This is one less license, thing to operate, thing to learn, thing to integrate. Still not ideal but it could look like this:
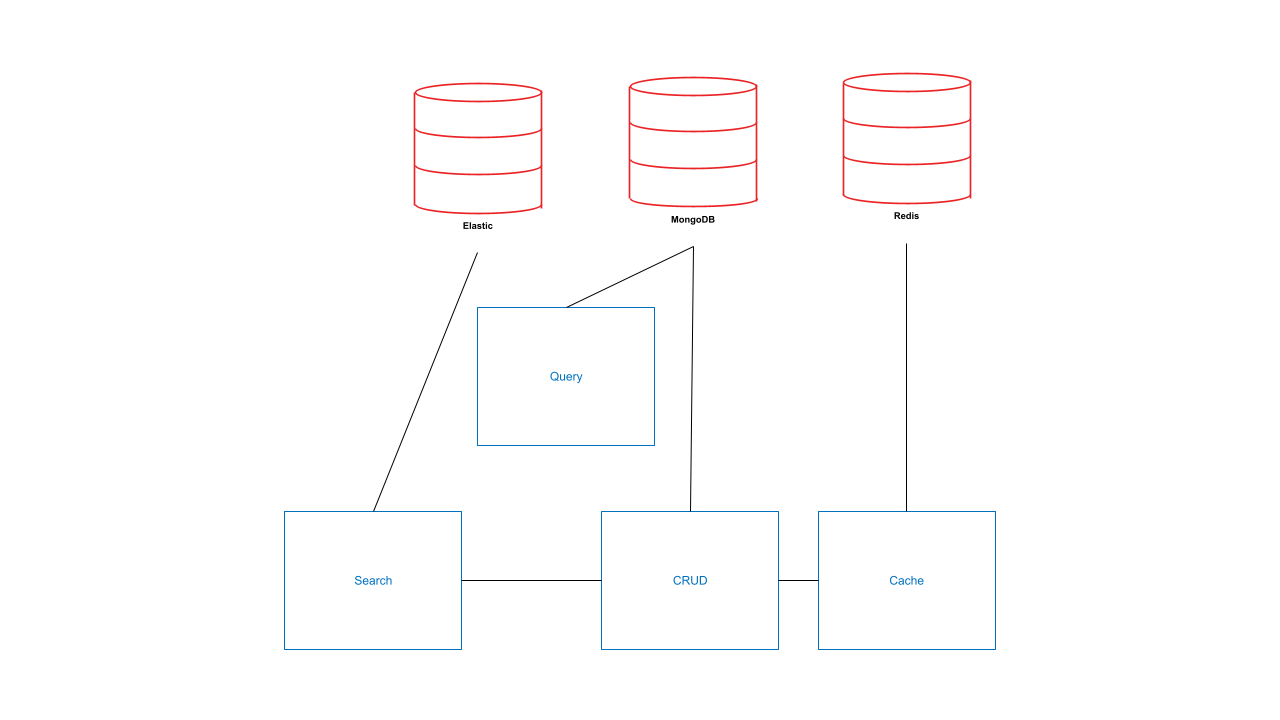
It’s a bit simpler, only 6 interactions and 3 data stores instead of 8 and 4. But then there are still a lot of interactions and part of the streaming integration has to be done manually. Whereas, before we could have learned and used existing connectors between existing services. Let’s take a quick look at the Java/Spring Boot sample code written for this.
There are 4 interfaces representing what developers can do with data stores. CRUD, Cache, Query and Search.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
public interface CRUD { StoredFileDocument read(String id); void create(String id, StoredFileDocument doc); void update(String id, StoredFileDocument doc); void upsert(String id, StoredFileDocument doc); void delete(String id); } public interface Cache { void writeInCache(StoredFileDocument doc); StoredFileDocument readFromCache(String id); void touch(String id); void evict(String id); } public interface Query { List<Map<String, Object>> query(String whereClause); List<Map<String, Object>> findAll(); } public interface Search { List<Map<String, Object>> search(String term); void index(StoredFileDocument doc); void delete(String id); } |
We are not going to show all the code in this post, but just a few of the interesting pieces.
We are in a configuration where the CRUD service has links to the Search and Cache services. Let’s see how it would look like with a simplified version. We have to import the Cache and Search service as they are required. From there, every method is impacted by it. Read needs to first query the cache, update the last time the object has been found in cache or get it from the database and insert it in the cache. Then Create, Update and Delete methods all impact Cache and Search as the newly created, updated or deleted data needs to be propagated to the Cache or the Search data store indexes.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
@Service public class MongoCRUD implements CRUD { private MongoCollection<StoredFileDocument> collection; private Cache cache; private Search search; public MongoCRUD(MongoCollection<StoredFileDocument> collection, Cache cache, Search search) { this.collection = collection; this.cache = cache; this.search = search; } @Override public StoredFileDocument read(String id) { StoredFileDocument doc = cache.readFromCache(id); if (doc == null) { System.out.println(id); doc = collection.find(eq("fileId", id)).first(); cache.writeInCache(doc); } else { cache.touch(id); } return doc; } @Override public void create(String id, StoredFileDocument doc) { doc.setFileId(id); collection.insertOne(doc); cache.writeInCache(doc); search.index(doc); } @Override public void update(String id, StoredFileDocument doc) { collection.findOneAndReplace(eq("fileId", id), doc); cache.touch(id); search.index(doc); } @Override public void upsert(String id, StoredFileDocument doc) { FindOneAndReplaceOptions options = new FindOneAndReplaceOptions().upsert(true); collection.findOneAndReplace(eq("fileId", id), doc, options); cache.touch(id); search.index(doc); } @Override public void delete(String id) { collection.deleteOne(eq("fileId", id)); cache.evict(id); search.delete(id); } } |
With Couchbase this would be closer to something like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
@Service @Profile("couchbase") public class CouchbaseCRUD implements CRUD { private Collection collection; public CouchbaseCRUD(Collection collection) { this.collection = collection; } @Override public StoredFileDocument read(String id) { GetResult res = collection.get(id); return res.contentAs(StoredFileDocument.class); } @Override public void create(String id, StoredFileDocument doc) { MutationResult res = collection.insert(id, doc); } @Override public void update(String id, StoredFileDocument doc) { MutationResult res = collection.replace(id, doc); } @Override public void upsert(String id, StoredFileDocument doc) { MutationResult res = collection.upsert(id, doc); } @Override public void delete(String id) { MutationResult res = collection.remove(id); } } |
The reason we don’t need a dependency to the Cache and Search service is because Couchbase already integrates a cache and a search engine. There is no need to implement the Cache interface, and no need to implement the delete and index method from the search interface. It’s all automated and integrated.
Usually when I explain that to someone, a conversation follows about how bad it must be, because you have to make trade-offs to be able to do all the things. All Data Platforms, multi-model, multi-workload, however you want to talk about them, are not created equal, or at least not with the same architecture in mind.
Couchbase can be seen as several, different databases, all responsible for different workloads and all integrated together through its internal streaming service. This way every part of Couchbase is kept up to date automatically and every part can specialize in its own data workload. In the end, you get 3 interactions and 1 datastore.
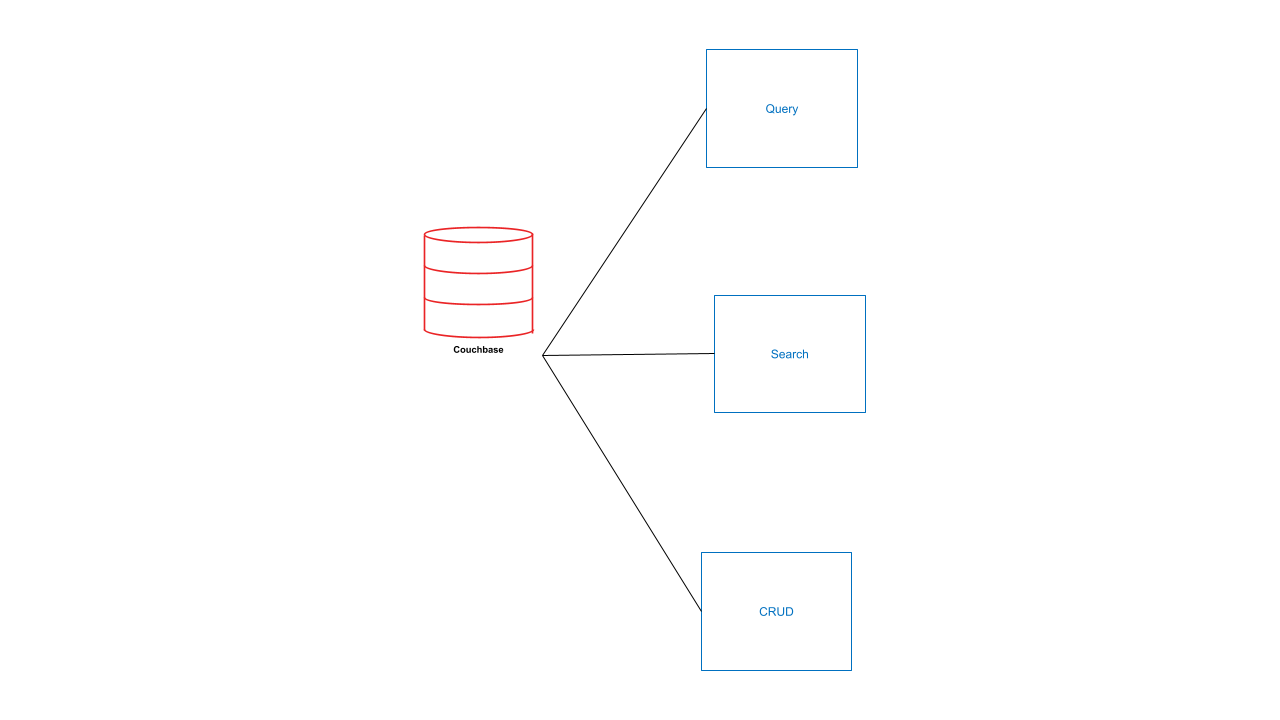
Now this is already quite nice, but we do have one more thing. Our services are integrated into our query language SQL++. Let’s take an example. You have a CMS that holds a tree of documents, with various permissions on each document, and those permissions can be inherited by child documents on which you want to run a search as a connected user with a specific set of permissions. If you are using an external Search Engine, what usually happens is:
-
- Run a search query to the search engine
- Gather the identifiers of the returned documents because not all the doc content is indexed
- Run a query to get the complete documents
- If your Query service does not support JOIN, run another query to get inherited permissions and filter out the docs
If we wanted to make things more complicated (and maybe also more real) we could add a custom caching logic to each step. But it’s already complicated enough.
Couchbase can do everything in one step. In one SQL++ query we can search, select the fields we want, and JOIN on other documents to sort out the permissions. It’s as simple as that. Because Couchbase is a well integrated data platform, its query language allows you to leverage all of its powers. If you are interested, the details might come in another post.
Wrap up
So what did we learn today? Using a well architected Data Platform can save you lots of time, money, effort and headache. Because, in the end, you have less things to think about, less code to write, which means less code to maintain, and a faster ability to ship to production. Thankfully, it also simplifies and saves on things like licenses, training, compliance and all those things that managers, analysts, your boss, your boss’s boss care about!
- Watch my talk with RedMonk: What is Data Sprawl? How to Leverage a Platform to Wrangle it
- Check out the code for my data sprawl example
- Learn more about how Couchbase services are designed to make development smooth and simple.
- Try out the Couchbase Capella DBaaS to put it to the test