Couchbase is all about enabling more and more enterprise applications to leverage and adopt NoSQL/JSON data model. N1QL simplifies this transition from traditional Relational databases, and is built with tons of features to achieve best of both worlds. Continuing the train of Couchbase Server 4.5, the 4.5.1 release brings multiple functionality, usability and performance improvements in N1QL. These enhancements address many of our customer critical issues, and in general showcase the strength & sophistication of N1QL.
While some of the new improvements enhance existing functionality, others such as SUFFIXES() function enrich N1QL querying with magnitude performance improvement to LIKE queries. Further improvements enhance dynamic creation & manipulation of JSON objects, precision of numbers, UPDATE syntax for nested arrays etc.,
I am sure, this will need a series, but in this blog I will highlight LIKE-query and UPDATE enhancements. See Couchbase Server 4.5.1 what’s new and release notes for full list of N1QL enhancements. Kudos to N1QL team !!
Efficient pattern matching LIKE queries with SUFFIXES()
Pattern matching is a widely used functionality in SQL queries, and is typically achieved using the LIKE operator. Especially, efficient wildcard matching is very important. LIKE ‘foo%’ can be implemented efficiently with a standard index, but not LIKE ‘%foo%’. Such pattern matching with leading wildcard is vital, for every application that has a search box to match partial words or to smart-suggest matching text. For example,
- A travel booking site, that wants to pop-up matching airports as the user starts to enter few letters of the airport name.
- A user finding all e-mails with a specific word or partial word in the subject.
- Finding all topics of a forum or blog posts with specific keywords in the title.
In Couchbase Server 4.5.1, N1QL addresses this problem by adding a new string function SUFFIXES(), and combining that with the Array Indexing functionality introduced in Couchbase Server 4.5. Together, it brings magnitude difference to performance of LIKE queries with leading wildcards such as LIKE “%foo%”. Core functionality of SUFFIXES() is very simple, basically it produces an array of all possible suffix substrings of a given string. For example,
|
1 |
SUFFIXES("N1QL") = [ "N1QL", "1QL", "QL", "L" ] |
Following picture depicts a unique technique to combine SUFFIXES() function with Array Indexing to magically boost LIKE query performance.
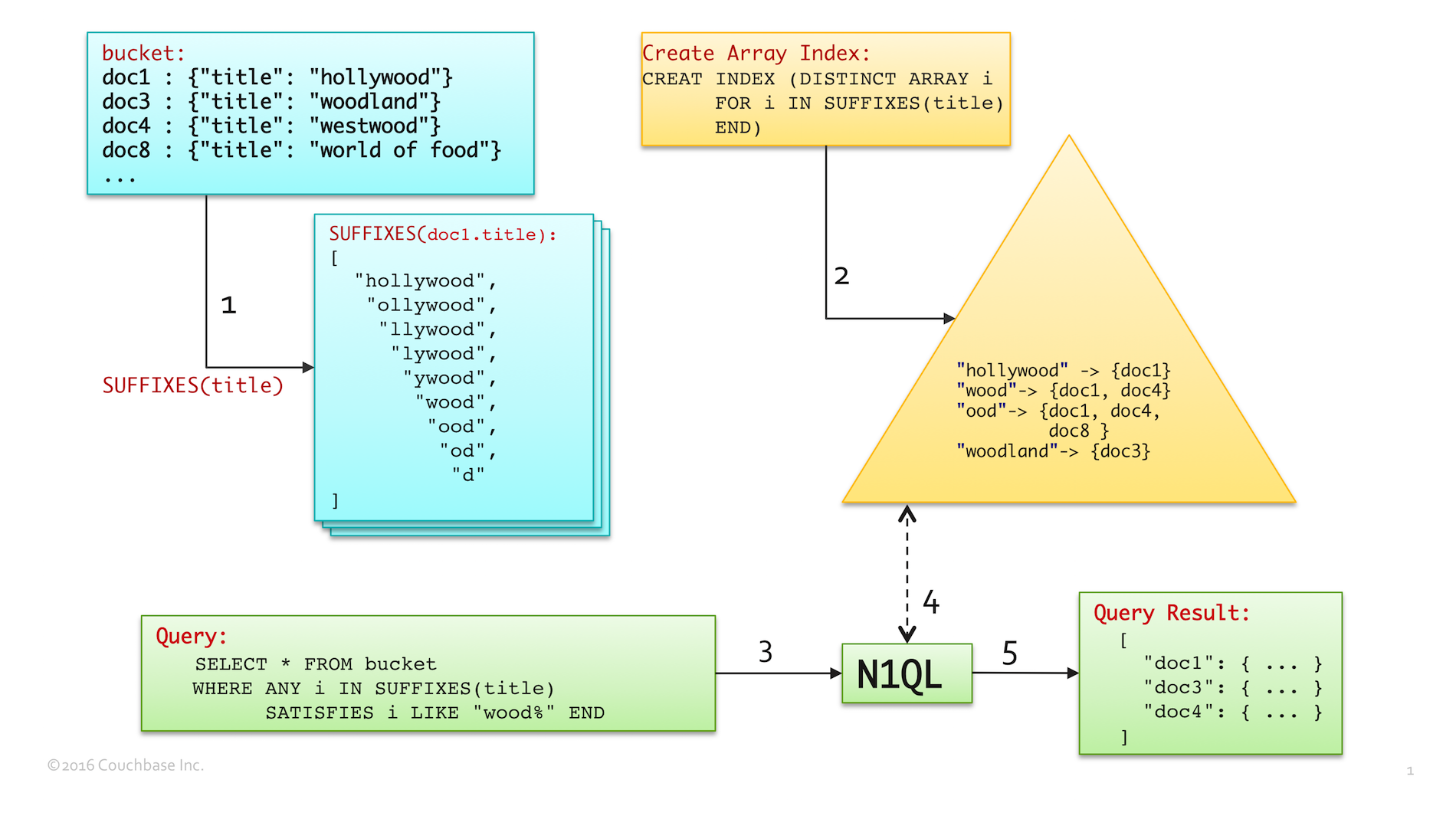
- Step1 (in blue) shows the array of suffix substrings generated by
SUFFIXES()fordoc1.title - Step2 (in yellow) shows the Array Index created with the suffix substrings generated in step1. Note that the index-entry for
"wood"points todoc1anddoc4, as that is one of the suffix substrings of titles of both the documents. Similarly,"ood"points todoc1,doc4, anddoc8. - Step3 (in green) runs a query equivalent to
SELECT title FROM bucket WHERE title LIKE "%wood%". The LIKE predicate is transformed to use the Array Index using the ANY construct. See documentation for more details on using array indexing.- Note that, the leading wildcard is removed in the new
LIKE "wood%"predicate. - This is accurate transformation, because the array index lookup for
"wood"points to all documents whose title has trailing substring"wood"
- Note that, the leading wildcard is removed in the new
- In Step4, N1QL looks-up in the Array Index to find all documents matching
"wood%". That returns{doc1, doc3, doc4}, because- the index lookup produces a span, which gets documents from
"wood"to"wooe" doc1anddoc4are matched because of index entry “wood” that is generated by the SUFFIXES() when creating the array index.doc3is matched because of its corresponding index-entry for"woodland"
- the index lookup produces a span, which gets documents from
- Finally, in step5, N1QL returns the query results.
Let’s see a working example with the travel-sample documents, which showed a 12x boost in performance for the query.
- Assume a document with a string field whose value is few words of text or a phrase. For example, title of a landmark, address of a place, name of restaurant, full name of a person/place etc., For this explanation, we consider
titleoflandmarkdocuments intravel-sample. - Create secondary index on
titlefield usingSUFFIXES()as:
123CREATE INDEX idx_title_suffixON `travel-sample`(DISTINCT ARRAY s FOR s IN SUFFIXES(title) END)WHERE type = "landmark";
SUFFIXES(title)generates all possible suffix substrings oftitle, and the index will have entries for each of those substrings, all referencing to corresponding documents. - Now consider following query, which finds all docs with substring
"land"intitle. This query produces following plan, and runs in roughly 120ms in my laptop. You can clearly see, it fetches alllandmarkdocuments, and then applies theLIKE "%land%"predicate to find all matching documents.
12345678910111213141516171819202122232425262728293031323334353637383940414243EXPLAIN SELECT * FROM `travel-sample` USE INDEX(def_type) WHERE type = "landmark" AND title LIKE "%land%";[{"plan": {"#operator": "Sequence","~children": [{"#operator": "IndexScan","index": "def_type","index_id": "e23b6a21e21f6f2","keyspace": "travel-sample","namespace": "default","spans": [{"Range": {"High": [""landmark""],"Inclusion": 3,"Low": [""landmark""]}}],"using": "gsi"},{"#operator": "Fetch","keyspace": "travel-sample","namespace": "default"},{"#operator": "Parallel","~child": {"#operator": "Sequence","~children": [{"#operator": "Filter","condition": "(((`travel-sample`.`type`) = "landmark") and ((`travel-sample`.`title`) like "%land%"))"}]} - In Couchbase 4.5.1, this query can be rewritten to leverage the array index
idx_title_suffixcreated in (2) above.
12345678910111213141516171819202122232425262728293031323334353637383940414243444546EXPLAIN SELECT title FROM `travel-sample` USE INDEX(idx_title_suffix) WHERE type = "landmark" ANDANY s IN SUFFIXES(title) SATISFIES s LIKE "land%" END;[{"plan": {"#operator": "Sequence","~children": [{"#operator": "DistinctScan","scan": {"#operator": "IndexScan","index": "idx_title_suffix","index_id": "75b20d4b253214d1","keyspace": "travel-sample","namespace": "default","spans": [{"Range": {"High": [""lane""],"Inclusion": 1,"Low": [""land""]}}],"using": "gsi"}},{"#operator": "Fetch","keyspace": "travel-sample","namespace": "default"},{"#operator": "Parallel","~child": {"#operator": "Sequence","~children": [{"#operator": "Filter","condition": "(((`travel-sample`.`type`) = "landmark") and any `s` in suffixes((`travel-sample`.`title`)) satisfies (`s` like "land%") end)"},
Note that:
- The new query in (4) uses
LIKE “land%”, instead ofLIKE “%land%”. The former predicate with no leading wildcard'%'produces much more efficient index lookup than the later one which can’t pushdown the predicate to index. - the array index
idx_title_suffixis created with all possible suffix substrings oftitle, and hence lookup for any suffix substring of title can find successful match. - in the above 4.5.1 query plan in (4), N1QL pushes down the LIKE predicate to the index lookup, and avoids additional pattern-matching string processing. This query ran in 18ms.
- Infact, with following covering Array Index, the query ran in 10ms, which is 12x faster.
|
1 2 3 |
CREATE INDEX idx_title_suffix_cover ON `travel-sample`(DISTINCT ARRAY s FOR s IN SUFFIXES(title) END, title) WHERE type = "landmark"; |
See this blog for details on a real-world application of this feature.
Enhancements to UPDATE to work with Nested Arrays
Enterprise applications often have complex data, and need to model JSON documents with multiple levels of nested objects and arrays. N1QL supports complex expressions and language constructs to navigate and query such documents with nested arrays. N1QL also supports Array Indexing, with which secondary indexes can be created on array elements, and subsequently queried.
In Couchbase Server 4.5.1, the UPDATE statement syntax is improved to navigate nested arrays in documents, and update specific fields in nested array elements. The FOR-clause of the UPDATE statement is enhanced to evaluate functions and expressions, and the new syntax supports multiple nested FOR expressions to access and update fields in nested arrays.
Consider following document with nested array like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
{ items: [ { subitems: [ { name: "N1QL" }, { name: "GSI" } ] } ], docType: "couchbase" } |
The new UPDATE syntax in 4.5.1 can be used in different ways to access & update nested arrays:
-
12UPDATE default SET s.newField = 'newValue'FOR s IN ARRAY_FLATTEN(items[*].subitems, 1) END;
-
123UPDATE defaultSET s.newField = 'newValue'FOR s IN ARRAY_FLATTEN(ARRAY i.subitems FOR i IN items END, 1) END;
-
123UPDATE defaultSET i.subitems = ( ARRAY OBJECT_ADD(s, 'newField', 'newValue')FOR s IN i.subitems END ) FOR i IN items END;
Note that:
- The
SET-clause evaluates functions such asOBJECT_ADD()andARRAY_FLATTEN() FORconstructs can be used in nested fashion with expressions to process array elements at different nest-levels.
For a working example, consider the sample bucket travel-sample shipped with 4.5.1.
- First, let’s add a nested array of special flights to the array schedule in
travel-samplebucket, for some documents.
123456UPDATE `travel-sample`SET schedule[0] = {"day" : 7, "special_flights" :[ {"flight" : "AI444", "utc" : "4:44:44"},{"flight" : "AI333", "utc" : "3:33:33"}] }WHERE type = "route" AND destinationairport = "CDG" AND sourceairport = "TLV"; - following UPDATE statement adds a 3rd field to each special flight:
12345678910111213141516171819202122232425262728UPDATE `travel-sample`SET i.special_flights = ( ARRAY OBJECT_ADD(s, 'newField', 'newValue' )FOR s IN i.special_flights END )FOR i IN schedule ENDWHERE type = "route" AND destinationairport = "CDG" AND sourceairport = "TLV";SELECT schedule[0] from `travel-sample`WHERE type = "route" AND destinationairport = "CDG" AND sourceairport = "TLV" LIMIT 1;[{"$1": {"day": 7,"special_flights": [{"flight": "AI444","newField": "newValue","utc": "4:44:44"},{"flight": "AI333","newField": "newValue","utc": "3:33:33"}]}}]
There are many more important N1QL enhanements and Performance features in Couchbase Server 4.5.1 release. Will write about them in my next blog/part2.
Download 4.5.1 and give it a try. Let me know any questions/comments, or just how awesome it is ;-)
Cheers!!