Any modern web application that interacts with users in different localities must contend with varying privacy requirements and user data consent guidelines. These can be overwhelming for any engineering team to handle, regardless whether the team is just you or fifty people.
How do you simplify the process to remove the hassle and decrease the likelihood of non-compliance?
In this guide, we’ll walk through an implementation leveraging AWS services working in tandem with Couchbase to sanitize data before it ever reaches a data store. This simplified implementation can be utilized in any context and can be expanded to fit the use case you are building.
tl;dr Interested in just seeing the code along with a README containing deployment instructions? Find all you need on GitHub.
Overview
Example Scenario
Imagine a small eCommerce platform that sells unique, handmade crafts. This site operates on a one-off purchase model, meaning users are not required to create accounts or log in. Shoppers simply browse the catalog, select items they wish to purchase, and proceed to checkout. During the checkout process, they provide essential information such as full name, mailing address, billing address, payment information, phone number, and email address. This Personally Identifiable Information (PII) is necessary to complete the purchase and ensure the item is shipped to the correct address.
Once the order is placed, the data travels through various microservices. The order processing service validates the details and checks inventory, the payment service securely handles the billing information to process transactions, and the shipping service uses the provided mailing address to arrange delivery.
The site is designed to give users a seamless and easy shopping experience. There are no accounts. No need to go through a lengthy registration process. Simply choose the item to buy, make the payment along with shipping information and it is done. However, while the customer has had a frictionless shopping experience, their personal data cannot have the same frictionless experience in your application. To maintain privacy and comply with regulations, this PII must be sanitized before being stored in the long-term purchase history database.
While this scenario may seem unique, it is actually a situation that may occur in our applications all the time. Every application that collects any aspect of a user’s information must ensure rigorous consent and be in compliance with the laws and regulations of every locality it operates in across the globe. This can be an enormous challenge, and one that carries with it severe ramifications if not done properly.
Solution Workflow
In order to effectively handle privacy requirements for live data, we will need to leverage the real-time data capabilities of AWS and Couchbase to transform the data as soon as it is created. It is legally challenging to store private data even for a moment in a database according to GDPR regulations. As such, not only is it good data practice to add the data only after it has been sanitized, it may even be a legal requirement.
The solution we are crafting will leverage AWS Simple Queue Service (SQS), Elastic Container Registry (ECR), and a Lambda function working in partnership with Couchbase Capella, the fully managed Database as a Service (DBaaS). This workflow can be implemented with any message sender to the queue service, which will initiate the data sanitizing process. In other words, it is plug and play capable.
The following workflow visually demonstrates how the solution operates.
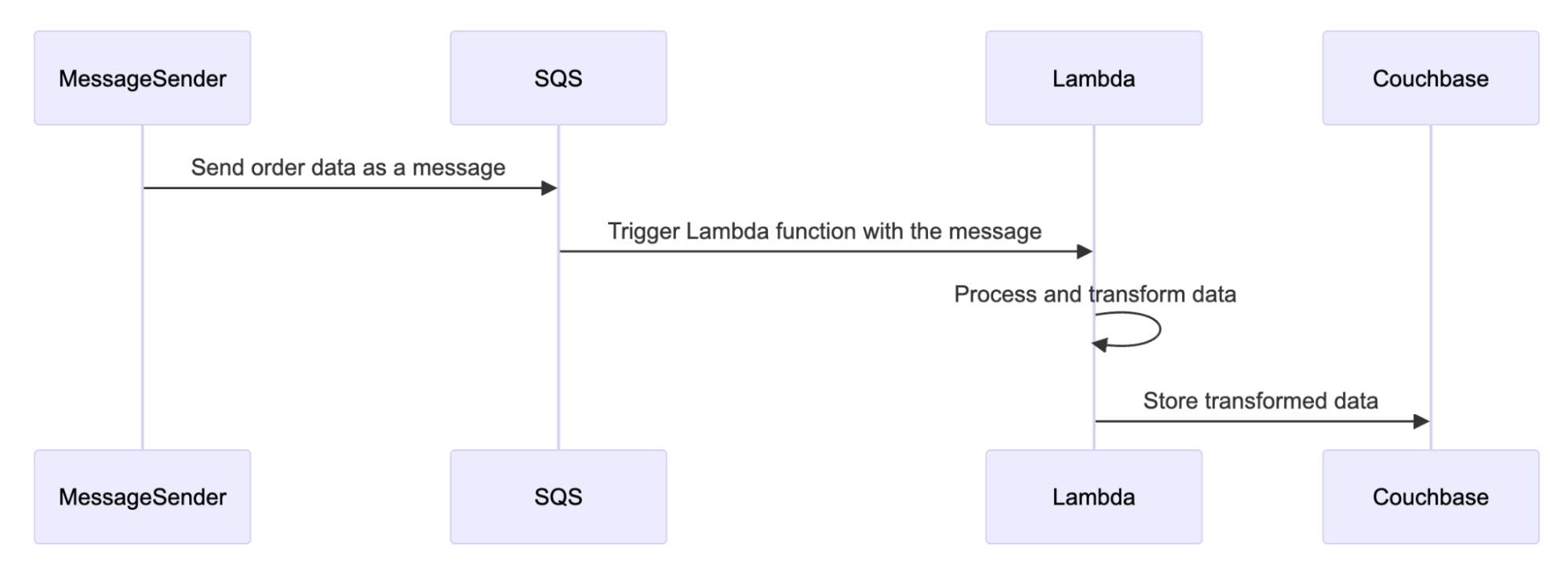
First, any message sender sends data to the queue service. This triggers the Lambda function with the message. The Lambda function processes and transforms the data removing all PII from the message. Finally, the sanitized data is then sent to Couchbase to be safely added to the data store.
Now that we understand the workflow, let’s build it!
Implementation
Configuring Couchbase Capella
It is free to sign up and try Couchbase Capella, and if you have not done so yet, you can do so by navigating to cloud.couchbase.com and creating an account using your GitHub or Google credentials, or by making a new account with an email address and password combination.
 Once you have done so, from within your Capella dashboard, you will create your first database. For the purposes of this walkthrough, let’s name it anonymize_data_example.
Once you have done so, from within your Capella dashboard, you will create your first database. For the purposes of this walkthrough, let’s name it anonymize_data_example.
The summary of your new database will be presented on the left-hand side of the dashboard. Capella is multi-cloud and can work with AWS, Google Cloud or Azure. For this example, you will deploy to AWS.
After you have created your database, you need to create a bucket. A bucket in Couchbase is the container where the data is stored. Each item of data, known as a document, is kept in JSON making its syntax familiar to most developers. You can name your bucket whatever you want. However, for the purposes of this walkthrough, let’s name this bucket anonymized_data_example.
Now that you have created both your database and your bucket, you are ready to create your database access credentials and to fetch your connection URL that you will be using in your Lambda function.
Navigate to the Connect section in the Capella dashboard and take note of the Connection String.
Then, click on the Database Access link under section two. In that section, you will create credentials – a username and password – that your Lambda function will use to authenticate with the database. You can scope the credentials to the specific bucket you created or give it permission for all buckets and databases in your account. You need to make sure it has both read and write access, regardless.
At this point, you are now ready to create the Lambda function that will be invoked each time a message is received by the queue service.
Creating the Lambda Function
Every application will have different PII that it may collect, and depending on the localities the application is operating in, it may also have different requirements of what it must remove before saving the data. In this example, we will remove the IP address and the surname of every message before sending it on to Couchbase.
The function to sanitize the data is itself fairly straightforward:
|
1 2 3 4 5 |
function anonymizeData(data) { data.user.last_name = ''; delete data.user.ip_address; return data; } |
This function, anonymizeData, will be invoked in the handler function of the code. If you are not familiar with a handler function, it is used by AWS Lambda to process incoming messages from the SQS queue, transform the data, and store it in Couchbase. Your main executable code must begin with a exports.handler.
The handler function fetches the Couchbase credentials and connection string from the environment variables set inside the configuration of the Lambda function. Detailed instructions on setting environment variables for a Lambda function can be found in the AWS documentation. Then, the function parses the message it received from SQS and calls the anonymizeData function on it. Lastly, it upserts the data into the Couchbase bucket.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
exports.handler = async (event) => { console.log('Starting Lambda function'); if (!event.Records || !Array.isArray(event.Records)) { throw new TypeError('event.Records is not iterable'); } const connectionString = process.env.COUCHBASE_CONNECTION_STRING; const username = process.env.COUCHBASE_USERNAME; const password = process.env.COUCHBASE_PASSWORD; const bucketName = process.env.COUCHBASE_BUCKET_NAME; try { const cluster = await couchbase.connect(connectionString, { username: username, password: password }); console.log('Connected to Couchbase cluster'); const bucket = cluster.bucket(bucketName); const collection = bucket.defaultCollection(); for (const record of event.Records) { console.log('Processing record:', record); const payload = JSON.parse(record.body); const transformedData = anonymizeData(payload); console.log('Transformed data:', transformedData); await collection.upsert(transformedData.record_id, transformedData); console.log('Data upserted:', transformedData.record_id); } } catch (error) { console.error('Error during processing:', error); throw error; } }; |
To set up the Lambda function using the AWS CLI, you need to create a new Lambda function and specify the necessary IAM role and handler. Here’s how you can do it:
|
1 2 3 4 |
aws lambda create-function --function-name AnonymizeDataExampleFunction \ --package-type Image \ --code ImageUri=<your-account-id>.dkr.ecr.<your-region>.amazonaws.com/anonymize_data_example_image:latest \ --role arn:aws:iam::<your-account-id>:role/<your-lambda-execution-role> |
Make sure to replace <your-account-id>, <your-region>, and <your-lambda-execution-role> with your actual AWS account ID, region, and the ARN of the IAM role you created for the Lambda function. This command sets up the Lambda function to use the Docker image you will publish to AWS ECR.
The Lambda function is now ready to be packaged in a Docker image and published to the AWS ECR service.
Deploying the Docker Image to ECR
To deploy the Docker image to AWS ECR, we start by building the Docker image for the linux/amd64 platform. This ensures compatibility with the x86_64 architecture of our Lambda function. We use a Dockerfile that installs the necessary tools and dependencies, sets the working directory, copies the required files, installs the dependencies, and copies the Lambda function code. The Dockerfile also specifies the command to run the Lambda function.
Here is the Dockerfile:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
FROM public.ecr.aws/lambda/nodejs:18 # Install necessary tools and dependencies RUN yum -y install gcc-c++ tar gzip findutils # Set the working directory WORKDIR /var/task # Copy package.json and package-lock.json COPY package*.json ./ # Install dependencies RUN npm install # Copy the function code COPY index.js ./ # Command to run the Lambda function CMD [ "index.handler" ] |
Once the Dockerfile is ready, we build the Docker image with the specified platform:
|
1 |
docker build --platform linux/amd64 -t anonymize_data_example_image . |
After building the image, we tag it appropriately for the AWS ECR repository:
|
1 |
docker tag anonymize_data_example_image:latest <your-account-id>.dkr.ecr.<your-region>.amazonaws.com/anonymize_data_example_image:latest |
To push the Docker image to ECR, we first log in to the ECR registry using the AWS CLI to obtain the login credentials:
|
1 |
aws ecr get-login-password --region <your-region> | docker login --username AWS --password-stdin <your-account-id>.dkr.ecr.<your-region>.amazonaws.com |
With the credentials in place, we push the Docker image to the ECR repository:
|
1 |
docker push <your-account-id>.dkr.ecr.<your-region>.amazonaws.com/anonymize_data_example_image:latest |
Finally, we update the Lambda function named AnonymizeDataExampleFunction to use the new Docker image from ECR. This involves specifying the image URI and ensuring that the Lambda function is configured to run the code from the newly pushed Docker image:
|
1 |
aws lambda update-function-code --function-name AnonymizeDataExampleFunction --image-uri <your-account-id>.dkr.ecr.<your-region>.amazonaws.com/anonymize_data_example_image:latest |
By following these steps, the Docker image is successfully deployed to AWS ECR and the Lambda function is updated to use the new image, allowing the application to sanitize PII before storing it in Couchbase. This setup ensures that data processing complies with privacy requirements while leveraging the power of AWS and Couchbase.
Setting up the SQS Service
To facilitate the flow of data between the message sender and the Lambda function, we need to set up an Amazon SQS queue. The SQS queue will act as a buffer that receives and stores messages until they are processed by the Lambda function. Here’s how you can set up an SQS queue and make it a trigger for the Lambda function using the AWS CLI.
First, create a new SQS queue. This queue will receive messages containing user data from the message sender, which is the application.
|
1 |
aws sqs create-queue --queue-name AnonymizeDataExampleQueue |
After creating the queue, you will receive a URL for the queue. This URL is necessary for sending messages to the queue and configuring it as a trigger for the Lambda function.
Next, we need to get the ARN of the SQS queue, which is required to set up permissions and triggers. Use the following command to retrieve the ARN:
|
1 |
aws sqs get-queue-attributes --queue-url https://sqs.<your-region>.amazonaws.com/<your-account-id>/AnonymizeDataExampleQueue --attribute-names QueueArn |
Replace <your-region> and <your-account-id> with your actual AWS region and account ID.
The output will include the QueueArn, which looks something like this:
|
1 2 3 4 5 |
{ "Attributes": { "QueueArn": "arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue" } } |
Now, we need to grant the Lambda function permission to read messages from the SQS queue. Create a policy file named lambda-sqs-policy.json with the following content:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sqs:ReceiveMessage", "Resource": "arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue" }, { "Effect": "Allow", "Action": "sqs:DeleteMessage", "Resource": "arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue" }, { "Effect": "Allow", "Action": "sqs:GetQueueAttributes", "Resource": "arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue" } ] } |
Apply this policy to the Lambda execution role:
|
1 |
aws iam put-role-policy --role-name <your-lambda-execution-role> --policy-name LambdaSQSPolicy --policy-document file://lambda-sqs-policy.json |
Next, add the SQS queue as a trigger for the Lambda function:
|
1 |
aws lambda create-event-source-mapping --function-name AnonymizeDataExampleFunction --batch-size 10 --event-source-arn arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue |
This command sets up the Lambda function to be triggered by messages arriving in the SQS queue.
Now, your Lambda function is set to receive every message sent to the queue service. The workflow is complete! This setup ensures efficient handling of user data while maintaining compliance with privacy requirements.
Test the Implementation Locally
To ensure that everything works as expected, you can test the workflow by sending a message through to the queue directly yourself. From the command line execute the following:
|
1 |
aws sqs send-message --queue-url https://sqs.<your-region>.amazonaws.com/<your-account-id>/AnonymizeDataExampleQueue --message-body "{\"record_id\": \"purchase_002\", \"item\": \"item_1\", \"user\": {\"first_name\": \"John\", \"last_name\": \"Doe\", \"ip_address\": \"192.168.1.1\"}, \"timestamp\": \"2024-07-01T12:34:56Z\"}" |
The message will trigger the Lambda function, which in turn, will add the data to your Couchbase bucket after sanitizing it. You can view the sample data you sent in the message by either logging into the Capella dashboard or in your VSCode or Jetbrains IDE directly by using their respective Couchbase extension.
Wrapping Up
The work to build, deploy and maintain any modern application today is an enormous task. As much as it is possible, parts of that task that are not directly related to the core business of the application should be simplified and abstracted away to reduce the cognitive load of the engineers, the SREs, and everyone else involved. Privacy regulations is one major item that must both be strictly adhered to and should also not cause any major headaches or increased workload.
Building an automated plug and play workflow that can easily sit between any application that interacts with Personally Identifiable Information and the database that data is stored in will significantly ease the cognitive load, reduce the burden and streamline the development process. With leveraging AWS and Couchbase together, you can make that possible for your real-time data sanitization needs thereby ensuring both user integrity and engineering productivity.