Large Language Models, popularly known as LLMs is one of the most hotly debated topics in the AI industry. We all are aware of the possibilities and capabilities of ChatGPT by OpenAI. Eventually using those LLMs to our advantage discovers a lot of new possibilities using the data.
But you can’t just expect everything from LLMs because of its design limitations and a lot of other factors. But using the concept of Vector Search gives us a new type of app called Retrieval Augmented Generation (RAG) Applications. So let’s see what RAG applications are, how they can be used to tackle new problems, how they can be developed using Couchbase and have a detailed overview of how Vector Search helps in making those applications.
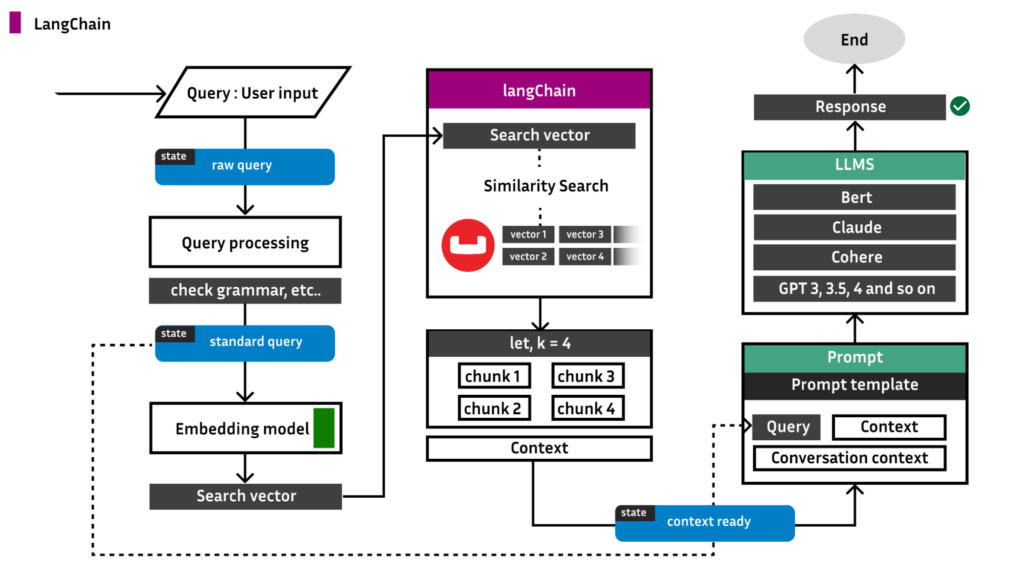
Before we get into the background of the application, here is an architectural diagram of what we are building and how LangChain ties into it:
Retrieval augmented generation (RAG)
RAG provides a way to augment the output of an LLM with targeted information without modifying the underlying model itself such that targeted information can be more up-to-date than the LLM as well as specific to a particular organization and industry. That means the generative AI system can provide more contextually appropriate answers to prompts as well as base those answers on extremely current data. Let’s understand this concept using a real life example.
Let’s say you belong to organization X which has a ton of data stored in their database and you are in charge of developing an application which asks for user input and gives the output based on the data present in your database.
Initially you may think, this looks easy, right? If you are aware of LLMs and how to leverage them to your needs, then it’s a simple task. You just choose OpenAI LLMs or Llama and Mistral models if you want to be cost effective, and simply shoot user questions to the LLM and get the results.
But there is a big problem here…
For example, let’s assume you’re using the Llama 2 LLM 8B type.
Now this model is trained with almost all the data present on the public internet. You ask any questions, even questions about your org X, and it gives you the closest correct answer.

Now let’s make a small change to your problem statement. The ton of data which is present in your database is no longer public data, but private. Which means Llama 2 is unaware of your data and you will no longer give you correct answers.
Having the above scenario in mind, consider the user question, “what are the updates of the component C in org X?”
So, how to solve this?
You might think, why don’t we pass the entire data present in the database, along with the prompt, so the LLM can use the data as context and answer the question. But here is the big problem, all LLMs have a constraint called token limit. Without getting into what are tokens, etc., for now consider 1 token == 1 word.
Sadly, the token size limit of Llama 2 is 4096 tokens (words). Suppose the entire data present in your database has 10M words, then it becomes impossible to pass the entire data for context purposes.

The solution to the above problem is called RAG. In RAG, we select a proportion of data present in your database which is very closely related to the user’s query. The proportion size is such that:
Proportion size < token limit

Now we pass the extracted data as context along with the query and get good results. This is RAG. But how do we get the proportion of data which is closely related to the user query and at the same time the size doesn’t exceed the token size? This is solved using the concept of Vector Search.
What is vector search?
Vector search leverages machine learning (ML) to capture the meaning and context of unstructured data, including text and images, transforming it into a numeric representation. Frequently used for semantic search, vector search finds similar data using approximate nearest neighbor (ANN) algorithms.
Couchbase version 7.6.0 and above comes with this Vector Search feature. The important thing here is, no external libraries, modules and setups are required. Just having at least 1 search node does the job.

Couchbase internally uses the FAISS framework provided by Facebook to perform vector search.
Building a RAG application
Now let’s get to the actual stuff of developing a RAG application end-to-end using the Couchbase Vector Search functionality.
In this walkthrough, we are going to develop a chat with your pdfs application.
Before moving on, there are several ways to create the app. One such way is using the LangChain framework which we will use to develop the RAG application.
App 1: Building using LangChain framework
Step 1: Setting up a Couchbase database
You can set up the Couchbase server in EC2, Virtual Machine, your local machine, etc.
Follow this link to setup the Couchbase cluster. Make sure you have these services enabled, others are optional:
-
- Data
- Search
Note: Make sure you install Couchbase Server version 7.6.0 or above to perform vector search. Also we will develop this application using Python in the Mac OS environment.
Once the cluster is up and running, create a new project <project_name> and create a new Python file call app.py.
Now in the project terminal, execute the below command:
|
1 |
pip install --upgrade --quiet langchain langchain-openai langchain-couchbase sentence-transformers |
Now go to the UI and create a bucket named project. For this walkthrough, we will go with the default scope and collection.
-
- Learn more about the bucket, scope and collections in the docs.
Now there are different ways to generate vector embeddings. The popular one being OpenAI and we will be using that to generate vector embeddings.
Copy the below code to app.py:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import getpass import os from langchain_couchbase.vectorstores import CouchbaseVectorStore from langchain_openai import OpenAIEmbeddings from datetime import timedelta from couchbase.auth import PasswordAuthenticator from couchbase.cluster import Cluster from couchbase.options import ClusterOptions os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:") COUCHBASE_CONNECTION_STRING = "couchbase://localhost" DB_USERNAME = "Administrator" DB_PASSWORD = "Password" BUCKET_NAME = "project" SCOPE_NAME = "_default" COLLECTION_NAME = "_default" SEARCH_INDEX_NAME = "vector-index" auth = PasswordAuthenticator(DB_USERNAME, DB_PASSWORD) options = ClusterOptions(auth) cluster = Cluster(COUCHBASE_CONNECTION_STRING, options) cluster.wait_until_ready(timedelta(seconds=5)) embeddings = OpenAIEmbeddings() |
If you hosted Couchbase in a VM, Then make sure you replace the word localhost to the public ip of the VM.
Step 2: Importing the search index
The vector search feature in Couchbase requires a search index to perform. There are multiple ways to create the index, but to make things easy and fast, below is the index JSON. Copy the below code and paste it in:
- UI > Search > Add index (top right) > Import
Index.json
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
{ "name": "vector-index", "type": "fulltext-index", "params": { "doc_config": { "docid_prefix_delim": "", "docid_regexp": "", "mode": "type_field", "type_field": "type" }, "mapping": { "default_analyzer": "standard", "default_datetime_parser": "dateTimeOptional", "default_field": "_all", "default_mapping": { "dynamic": true, "enabled": true, "properties": { "metadata": { "dynamic": true, "enabled": true }, "embedding": { "enabled": true, "dynamic": false, "fields": [ { "dims": 1536, "index": true, "name": "embedding", "similarity": "dot_product", "type": "vector", "vector_index_optimized_for": "recall" } ] }, "text": { "enabled": true, "dynamic": false, "fields": [ { "index": true, "name": "text", "store": true, "type": "text" } ] } } }, "default_type": "_default", "docvalues_dynamic": false, "index_dynamic": true, "store_dynamic": true, "type_field": "_type" }, "store": { "indexType": "scorch", "segmentVersion": 16 } }, "sourceType": "gocbcore", "sourceName": "project", "sourceParams": {}, "planParams": { "maxPartitionsPerPIndex": 103, "indexPartitions": 10, "numReplicas": 0 } } |
Step 3: Loading the data
Now it’s time to store all the PDFs data as chunks along with its vector embeddings in the database.
Note: Read this detailed blog on chunking, data gathering, etc. It’s highly recommended to go through the blog to have a clear understanding of what we will be covering in the later steps.
There are libraries for different types of documents you want to upload. For example, if your source data is in .txt format then add the following code to your app.py:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from langchain_community.document_loaders import TextLoader from langchain_text_splitters import CharacterTextSplitter loader = TextLoader("path of your text file") documents = loader.load() text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=0) docs = text_splitter.split_documents(documents) vector_store = CouchbaseVectorStore.from_documents( documents=docs, embedding=embeddings, cluster=cluster, bucket_name=BUCKET_NAME, scope_name=SCOPE_NAME, collection_name=COLLECTION_NAME, index_name=SEARCH_INDEX_NAME, ) |
But suppose say your source type is PDF, then:
|
1 |
pip install pypdf |
|
1 2 3 4 |
from langchain_community.document_loaders import PyPDFLoader loader = PyPDFLoader("path to your pdf file") pages = loader.load_and_split() |
Not only PDFs are support, LangChain offers support for multiple types such as:
-
- CSV
- HTML
- JSON
- Markdown, and more
Learn more about Langchain document loaders.
Step 4: Inferring results
Now we are ready to send queries to our application:
|
1 2 3 |
query = "<your question>" results = vector_store.similarity_search(query) print(results[0]) |
App 2: Creating the app from scratch
Before starting, as described in the previous section, spin up your cluster with a bucket named project. Also, follow Step 2 of the previous section, making sure to import the search index.
Step 1: Setting up Couchbase
If you are going with defaults, then your app.py should look something like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from couchbase.auth import PasswordAuthenticator from couchbase.cluster import Cluster from couchbase.options import (ClusterOptions, ClusterTimeoutOptions,QueryOptions) from datetime import timedelta username = "Administrator" password = "password" bucket_name = "project" scope_name = "_default" collection_name = "_default" auth = PasswordAuthenticator( username, password, ) cluster = Cluster(f'couchbase://localhost}', ClusterOptions(auth)) cluster.wait_until_ready(timedelta(seconds=5)) cb = cluster.bucket(bucket_name) cb_coll = cb.scope(scope_name).collection(collection_name) |
Now that the Couchbase collection links and search index are ready, let’s move to the data loading part.
Step 2: Data loading
To keep things modularized, create a new Python file named load.py.
There are multiple ways to extract data from PDFs. To make it easy, lets use the pypdf package from Langchain:
load.py
|
1 2 3 4 |
from langchain_community.document_loaders import PyPDFLoader loader = PyPDFLoader("path to your pdf") pages = loader.load_and_split() |
Now this pages variable is a list of text blocks extracted from the pdf. Let’s merge all the content into one variable:
|
1 2 3 |
text = "" for page in pages: text += page['page_content'] |
Before chunking, we need to set up the embedding model. In this case, let’s go with the sentence-transformers/paraphrase-distilroberta-base-v1 from hugging face.
This model gives you vector embeddings of 768 dimensions.
load.py
|
1 2 |
from sentence_transformers import SentenceTransformer model = SentenceTransformer('sentence-transformers/paraphrase-distilroberta-base-v1') |
Now our model is ready. Let’s push the documents. We can use the package recursive character text splitter from Langchain.
This package gives you chunks of the provided size, then we will find the vector embedding for each chunk using the above model and push the document into the database.
So, the document will have two fields:
|
1 2 3 4 |
{ “Data” : <chunk>, “Vector_data” : <vector embedding of the chunk> } |
load.py
|
1 2 3 4 5 6 7 8 9 |
from langchain_text_splitters import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=20, length_function=len, is_separator_regex=False, ) chunks = text_splitter.create_documents(text) |
Now that our chunks are ready, we can find the embeddings for each chunk and push it to the database.
load.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
from json import JSONEncoder from FlagEmbedding import BGEM3FlagModel from sentence_transformers import SentenceTransformer import numpy as np import json import ast class NumpyEncoder(JSONEncoder): def default(self, obj): if isinstance(obj, np.ndarray): return obj.tolist() return JSONEncoder.default(self, obj) docid_counter = 1 for sentence in chunks: emb = model.encode(str(sentence.page_content)) embedding = np.array(emb) np.set_printoptions(suppress=True) json_dump = json.dumps(embedding, cls=NumpyEncoder) document = { "data":str(sentence.page_content), "vector_data":ast.literal_eval(json_dump) } docid = 'docid:' + str(name) + str(docid_counter) docid_counter+=1 try: result = cb_coll.upsert(docid, document) print(result.cas) except Exception as e: print(e) |
Wonder where the cb_coll came from? It’s the collection connector we created in app.py. To pass it, let’s wrap this entire thing in load.py to a function which accepts cb_coll as parameter.
So, finally your load.py should look like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
from langchain_community.document_loaders import PyPDFLoader from langchain_text_splitters import RecursiveCharacterTextSplitter from json import JSONEncoder from FlagEmbedding import BGEM3FlagModel from sentence_transformers import SentenceTransformer import numpy as np import json import ast class NumpyEncoder(JSONEncoder): def default(self, obj): if isinstance(obj, np.ndarray): return obj.tolist() return JSONEncoder.default(self, obj) def Load_data(cb_coll): loader = PyPDFLoader("path to your pdf") pages = loader.load_and_split() text = "" for page in pages: text += page['page_content'] text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=20, length_function=len, is_separator_regex=False, ) chunks = text_splitter.create_documents(text) docid_counter = 1 for sentence in chunks: emb = model.encode(str(sentence.page_content)) embedding = np.array(emb) np.set_printoptions(suppress=True) json_dump = json.dumps(embedding, cls=NumpyEncoder) document = { "data":str(sentence.page_content), "vector_data":ast.literal_eval(json_dump) } docid = 'docid:' + str(name) + str(docid_counter) docid_counter+=1 try: result = cb_coll.upsert(docid, document) print(result.cas) except Exception as e: print(e) |
Now let’s go to app.py, import this and call the load_data function.
app.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
from couchbase.auth import PasswordAuthenticator from couchbase.cluster import Cluster from couchbase.options import (ClusterOptions, ClusterTimeoutOptions,QueryOptions) from datetime import timedelta from ./load import Load_data username = "Administrator" password = "password" bucket_name = "project" scope_name = "_default" collection_name = "_default" auth = PasswordAuthenticator( username, password, ) cluster = Cluster(f'couchbase://localhost}', ClusterOptions(auth)) cluster.wait_until_ready(timedelta(seconds=5)) cb = cluster.bucket(bucket_name) cb_coll = cb.scope(scope_name).collection(collection_name) Load_data(cb_coll) |
Now this will push the docs in the required format and our search index will also get mutated. Now it’s time to do vector search.
Step 3: Vector Search
In Couchbase you have multiple ways to do it, one of them being the Curl method.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
import subprocess import json from config import COUCHBASE_URL def vector_search_chat1(index_name, search_vector, k, cb_coll,query): print("query :",query) args = {"index_name":index_name, "search_vector":search_vector,"k":k,"query":query,"couchbase_url":COUCHBASE_URL} curl_command = """ curl -XPOST -H "Content-Type: application/json" -u Administrator:password \ http://{couchbase_url}:8094/api/bucket/project/scope/_default/index/{index_name}/query \ -d '{{ "query": {{ "match_none":{} }}, "size": 6, "knn": [ {{ "field": "vector_data", "k": {k}, "vector":{search_vector} }} ], "from": 0 }}' """.format(**args) try: result = subprocess.run(curl_command, shell=True, check=True,stdout=subprocess.PIPE) return result.stdout |
The result.stdout contains the k nearest Doc IDs. You can extend the script to perform a get request on all the IDs returned and combine the results to get the final context. Then we pass this context along with the prompt to the LLM to get the desired results.