Ensuring a seamless flow of data is crucial for effective analysis and decision-making. Today, with data often being unstructured and nested, the choice of database plays a significant role in optimizing processing efficiency and query performance.
In this blog post, we’ll explore the process of data ingestion from MongoDB, a NoSQL database into both ClickHouse, a relational database, and Couchbase Capella Columnar, a NoSQL analytical database. We’ll focus on the preprocessing needed, query efficiency for joins after ingestion, and how each handles real-time data changes. We will show how Capella Columnar simplifies working with nested data, making it easier to store and query compared to the complexities in relational databases like ClickHouse.
TL;DR
ClickHouse requires extensive preprocessing for data ingestion due to the unnesting of nested data, and adding new fields can necessitate the creation of additional tables. Data from a single MongoDB collection must be split into separate tables, which means joins are required for querying—these can be resource-intensive. Moreover, adding a new nested field in real-time involves re-creating separate tables and updating schemas, leading to potential pipeline breaks and requiring manual intervention. In contrast, Capella Columnar simplifies the process by not requiring preprocessing for nested data. It allows direct ingestion from MongoDB collections without the need for separate tables or joins, and it automatically reflects real-time changes like adding new nested fields without additional processing.
What is Capella Columnar?
Before diving into this migration demo, you may want to watch our in-depth overview of Capella Columnar video or read our recent announcement that introduce this new technology that converges operational and real-time analytic workloads:
Sample MongoDB data
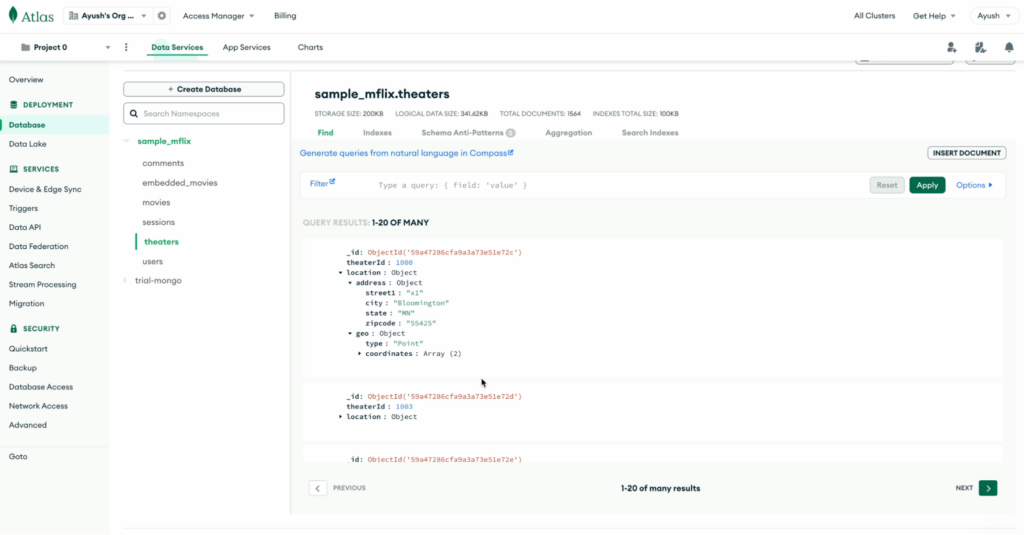
For the scope of this demo, we have used the sample MongoDB collection theaters of the sample_mflix database.
Here is a sample document from the theaters collection:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ "_id": { "$oid": "59a47286cfa9a3a73e51e72c" }, "theaterId": 1000, "location": { "address": { "street1": "x1", "city": "Bloomington", "state": "MN", "zipcode": "55425" }, "geo": { "type": "Point", "coordinates": [ -93.24565, 44.85466 ] } } } |
Data ingestion from MongoDB to Capella Columnar
We can utilize Kafka Links in Capella Columnar to ingest data from Kafka topics, where data from MongoDB collections has already been published. To make this happen, users need to set up their Kafka pipeline, where MongoDB data is funneled into Kafka topics.
Step 1 – connect MongoDB to Kafka
-
- Download the Debezium MongoDB source connector
- Run Kafka Connect – in either standalone or distributed mode
- Send a POST request with the required connection properties to link up with
MongoDB
|
1 2 3 4 5 6 7 8 9 10 11 |
curl -X POST -H "Content-Type: application/json" http://localhost:8083/connectors -d '{"name": "<name>","config": { "connector.class": "io.debezium.connector.mongodb.MongoDbConnector", "capture.mode": "change_streams_update_full", "mongodb.ssl.enabled": "true", "topic.prefix": "<topic_prefix>", "value.converter": "org.apache.kafka.connect.json.JsonConverter", "value.converter.schemas.enable": "false", "key.converter.schemas.enable": "false", "key.converter": "org.apache.kafka.connect.json.JsonConverter", "collection.include.list": "sample_mflix.theaters", "mongodb.connection.string":<mongo connection string>}}'¯ |
Please replace the placeholders in the curl request (indicated by the angle brackets, e.g., <value>) with the appropriate values for your specific use case.
After that, your data will find its way into the Kafka topic. The data will be present in the Confluent Kafka topic mongo_columnar_topic.sample_mflix.theaters:
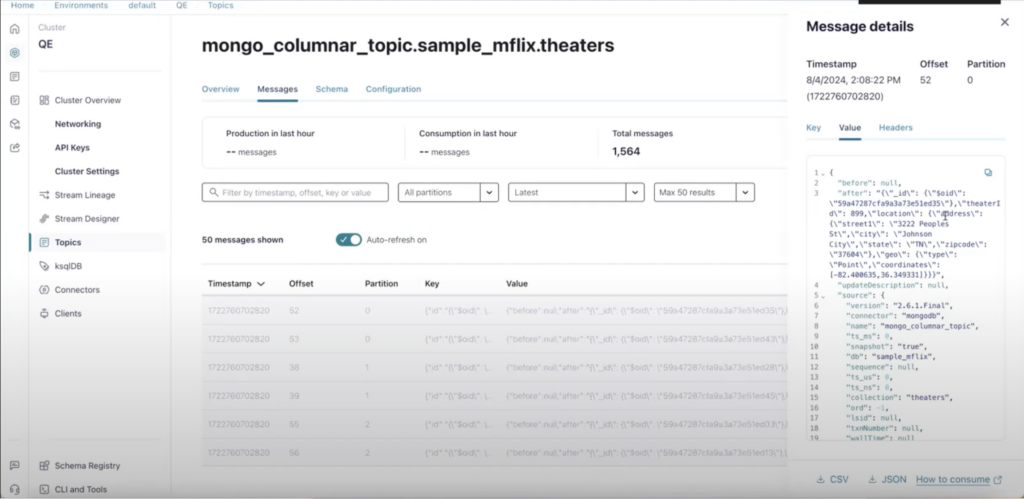
Once the data in the Kafka topic, now we can use Capella Columnar to pull data from the Kafka topic into collections.
Step 2 – create a link in Capella Columnar
In this example we are using Confluent Kafka as the Kafka flavor, Capella Columnar also supports Amazon MSK as well.


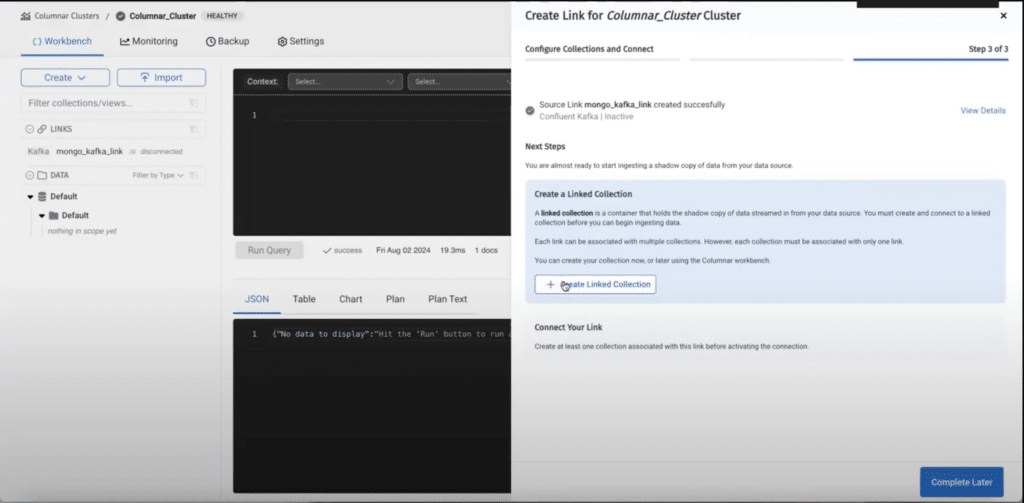
Step 3 – create a linked collection
After creating a link, we need to create a linked collection where data will be stored:
The fields are self explanatory, the field primary key is the path of the primary key in the MongoDB document residing in Kafka topic. In the given example the primary key for the MongoDB document is objectId:
|
1 |
_id`$oid`: String |
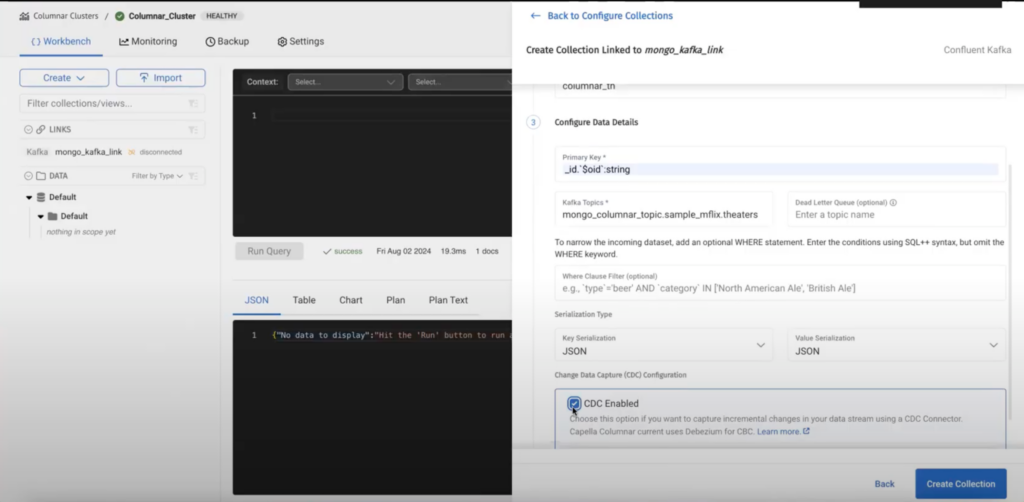
Enabling CDC creates an agreement on the format of the document which the Capella Columnar engine understands. Currently we only support Debezium as a source connector.
Step 4 – connect the link
After creating the collection we have to connect the link.
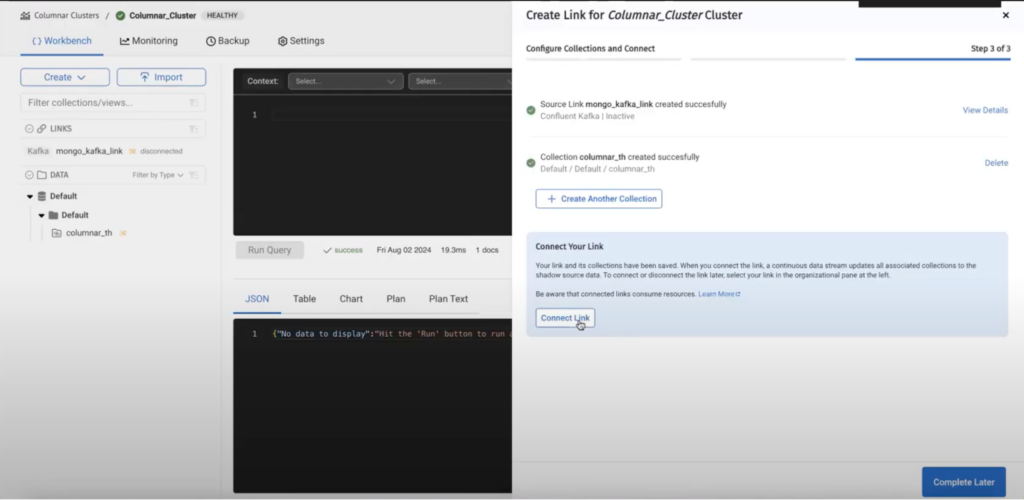
Once the link has been connected, the data should be flowing in, as we can see from the below query.

The data ingestion from MongoDB to Capella Columnar was seamless and intuitive. Now, let’s turn our attention to the challenges we encounter with relational databases like ClickHouse.
Data migration from MongoDB to ClickHouse
ClickHouse is a relational database, we can’t migrate data directly from MongoDB due to its document-based and nested data structures. This requires an additional data transformation step. The complexity of this transformation increases if the MongoDB data is highly nested or if additional fields are introduced, requiring adjustments, such as creating extra tables to manage these changes.
Creating a table in ClickHouse for MongoDB collections
To create a table in ClickHouse that maps to a MongoDB collection, we use the following syntax:
|
1 2 3 4 5 6 |
CREATE TABLE [IF NOT EXISTS] [db.]table_name ( name1 [type1], name2 [type2], ... ) ENGINE = MongoDB(host:port, database, collection, user, password [, options]); |
The MongoDB collection referenced here should be unnested before pointing to it.
We have a theaters collection in MongoDB, and our goal is to represent this data in a structured, relational format in ClickHouse.
Since ClickHouse does not support nested fields, we’ll need to create three tables to handle the theaters data with these schemas:
-
- theaters: _id, theaterId
- theaters_location_address: Street1, city, state, zipcode
- theaters_location_geo: type, coordinates
Preprocessing
To prepare the data, we first perform preprocessing on the MongoDB side to unnest the necessary fields. This involves creating MongoDB pipelines to extract and flatten the nested fields into separate collections for Address and Geo, while the Theaters table can be created directly.
Pipelines for MongoDB Address collection:

Pipeline for Geo collection:
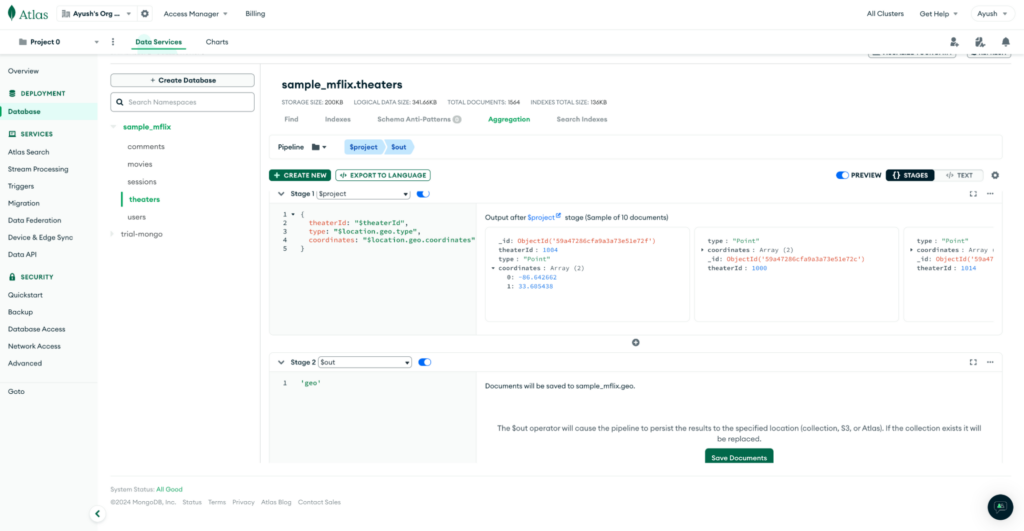
Creating tables in ClickHouse
Once preprocessing is complete, we create three corresponding tables in ClickHouse:
Query to create theaters:
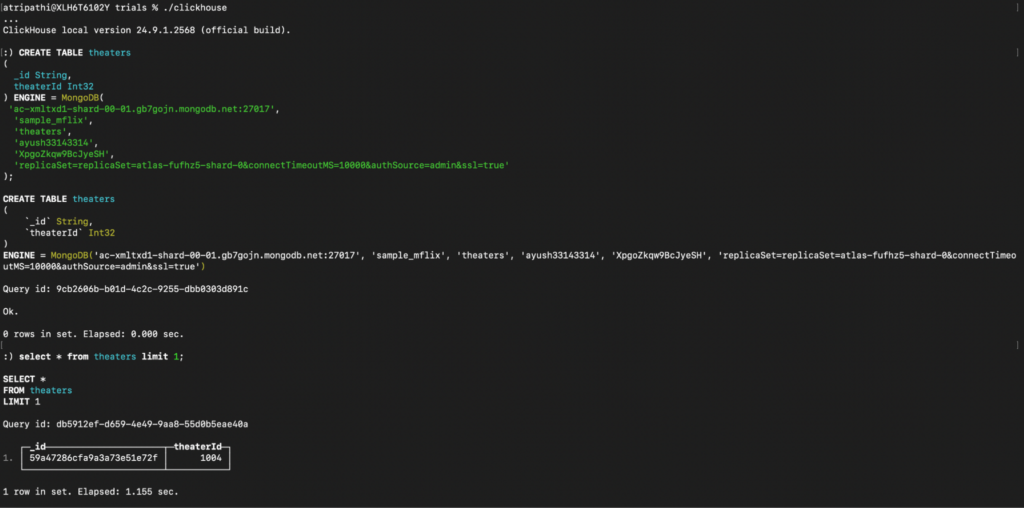
Query to create theaters_location_address:

Query to create theaters_location_geo:
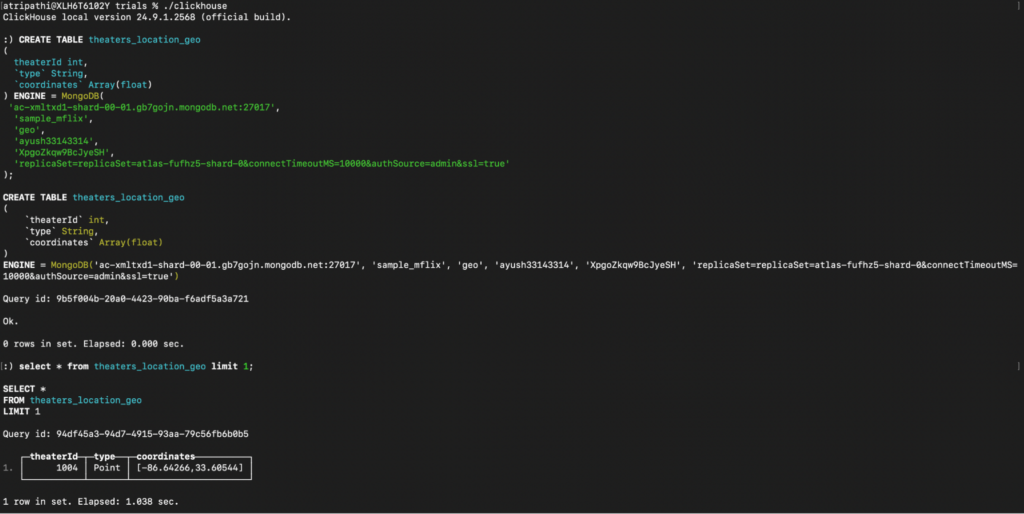
Having completed the data ingestion from MongoDB to ClickHouse, let us explore how real-time data changes are handled in both systems. We’ll examine the ease of managing these changes in Capella Columnar compared to the challenges faced with ClickHouse.
How are real-time changes handled?
Modification on the MongoDB side
Let’s change one document on MongoDB and add a nested owner field.
|
1 2 3 4 5 6 |
{ "Owner": { "name": "John", "age": 50 } } |
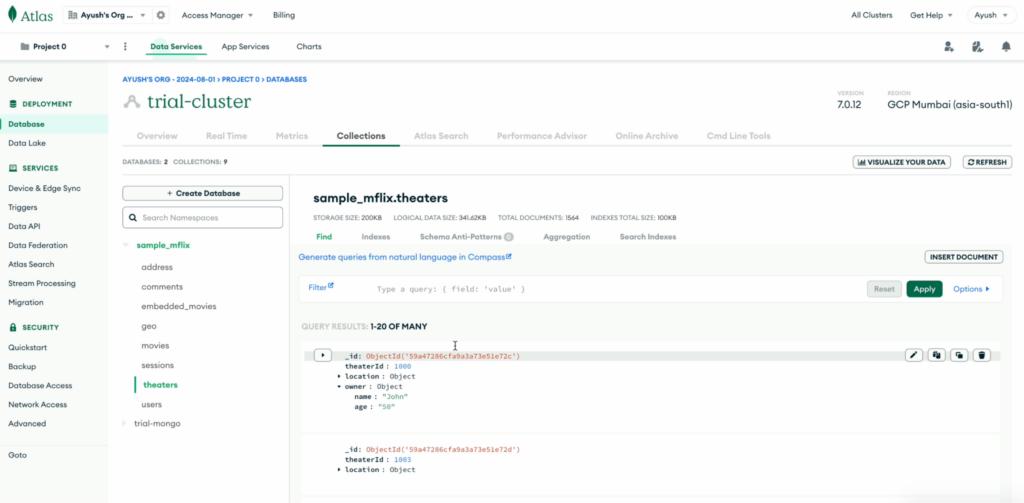
Live CDC changes in Capella Columnar
No extra step is required. On querying the particular document, we can see the change getting reflected:
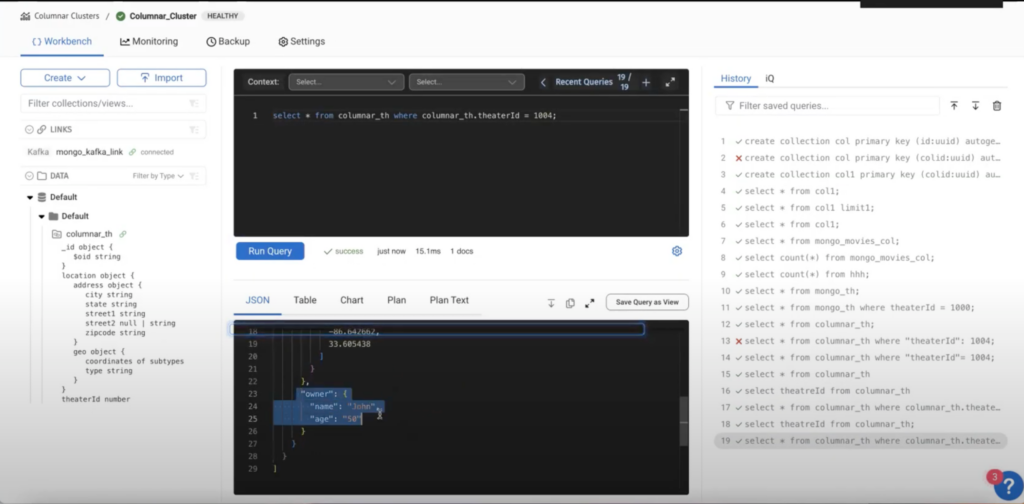
Setting up ClickHouse
ClickHouse faces challenges for real-time changes, as the pipeline breaks when attempting to bring in changes directly.
To fetch the updated data containing the Owner field, you’ll need to create another table in ClickHouse. First, create a new MongoDB collection where the Owner field is unnested, and then define a corresponding table in ClickHouse.
Pipeline on MongoDB to create owner collection:

Creating the owner table in ClickHouse:
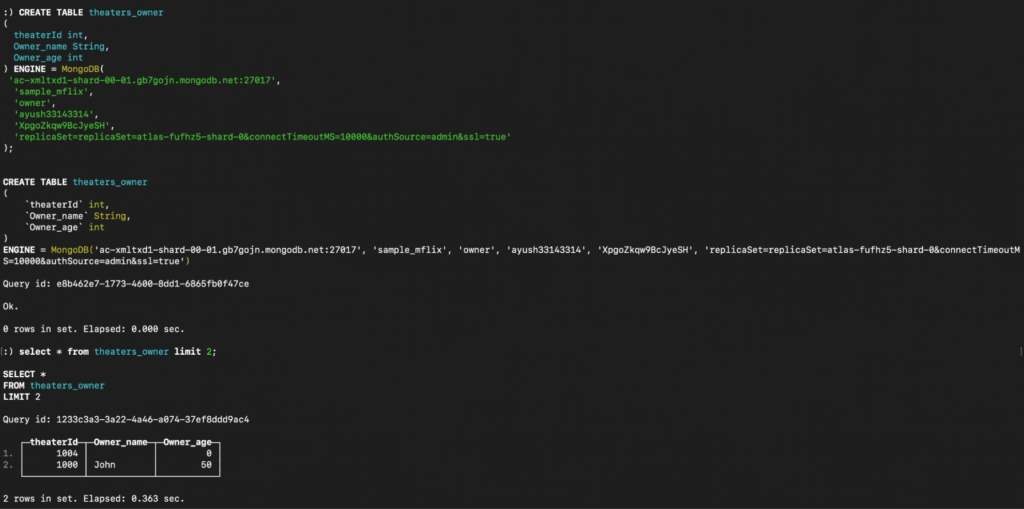
Now, as we transition to querying the data, it’s important to note that in ClickHouse, executing even simple queries requires stitching the data together, as we created different tables to unnest the original data. In contrast, Capella Columnar handles these queries effortlessly, requiring no additional steps.
Querying data in Capella Columnar vs. ClickHouse
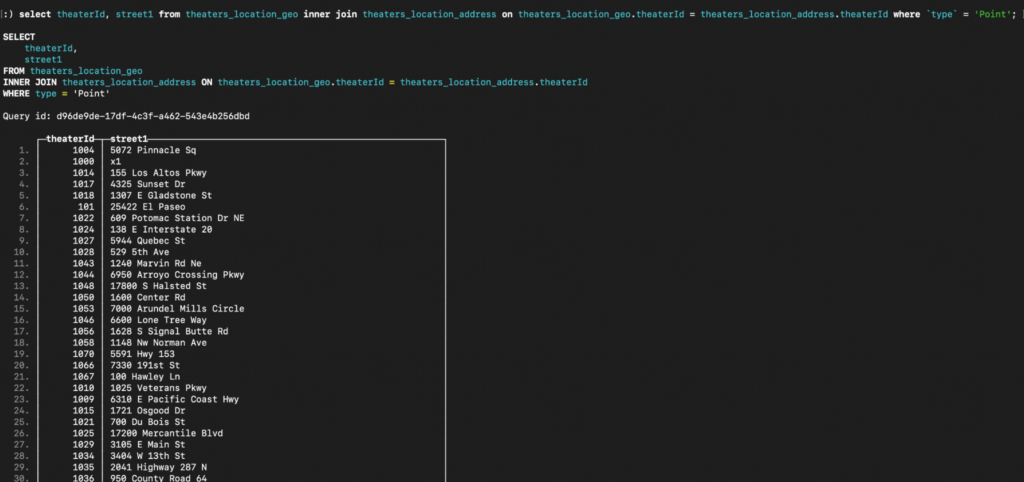
Let’s retrieve all the theaterId and street1 where the geo type is Point in both ClickHouse and Capella Columnar.
Query for Capella Columnar:
|
1 |
select theaterId, address.street1 from columnar_th where geo.type = 'Point'; |
Query for ClickHouse:
|
1 |
select theaterId, street1 from theaters_location_geo inner join theaters_location_address on theaters_location_geo.theaterId = theaters_location_address.theaterId where `type` = 'Point'; |
Comparison of ClickHouse and Capella Columnar
| Parameter | ClickHouse | Capella Columnar |
| Data Ingestion | Extensive preprocessing is required due to the unnesting of nested data, and the addition of fields into columns can necessitate the creation of additional tables. | No preprocessing required for nested data. |
| Schema and Data Transformation | Data from a single MongoDB collection needs to be split into separate tables, with joins required for querying, which can be expensive. | Data can be ingested directly from the MongoDB collection without the need for separate tables or joins. |
| Real-Time Data Changes | Adding a new nested field requires re-creating separate tables to unnest the data, necessitating schema updates and potentially complex transformations.
This leads to pipeline breaks and requires manual intervention. |
Real-time changes, like adding a new nested field, are automatically reflected without additional processing. |
Conclusion
In summary, Couchbase Capella offers a more streamlined approach to ingesting and querying nested MongoDB data, minimizing preprocessing and handling real-time changes with ease. In contrast, ClickHouse requires extensive data transformation and schema adjustments, making it less efficient for managing complex, nested structures. For environments dealing with real-time data and nested formats, Capella Columnar proves to be the more flexible and efficient choice.