User-defined functions put you in the driver’s seat when it comes to querying and analyzing your data.
In the Couchbase ecosystem, user-defined functions (UDFs) are reusable and parameterizable SQL++ queries that enable you to modularize queries and increase code reuse – all while giving you more control over how a particular query interacts with your business logic.
That said, I’m excited to announce that the Couchbase Server 7.0 release now supports User-Defined Functions (UDFs) in the Analytics Service.
Check out yesterday’s blog post for more information on user-defined functions in the SQL++ query language.
User-Defined Functions 101
Within Couchbase Analytics, user-defined functions have two parts:
- The Function Signature: The signature consists of the function name plus its number of parameters. A function takes zero, one, or more parameters. Each function belongs to a dataverse (or Scope in 7.0 terminology) and must have a unique signature within that dataverse. This means you could create two functions within the same dataverse that have the same name but have a different number of parameters. Because the function signature is distinct (name + number of parameters), it’s allowed.
- Function Body: A function body can be either an expression or a subquery and can refer to existing datasets or to other functions within the same dataverse or in a different dataverse.
Here are two examples showing the function signature – my_dataverse.GetOrders(...) – and the function body (everything between the curly braces below):
|
1 2 3 4 5 |
CREATE OR REPLACE ANALYTICS FUNCTION my_dataverse.GetOrders(customer_id) { SELECT o FROM Orders AS o WHERE o.customer_id = customer_id } |
|
1 2 3 4 5 6 |
CREATE OR REPLACE ANALYTICS FUNCTION my_dataverse.GetOrders(customer_id, year) { SELECT o FROM Orders AS o WHERE o.customer_id = customer_id AND o.year = year } |
If the CREATE ANALYTICS FUNCTION statement doesn’t provide a dataverse name, then the function is created within the active dataverse. If a dataverse is not specified, then the function is created in the “Default” dataverse.
A dataverse can be provided via a USE <<dataverse>> statement in the query or via a query_context REST API parameter.
Background: Scopes & Collections in Couchbase Analytics
Before I show you the full lifecycle of a Couchbase Analytics UDF, let’s first catch up on some important context.
Diagram A below represents sample data that could be used by a travel business to manage airline and hotel bookings.
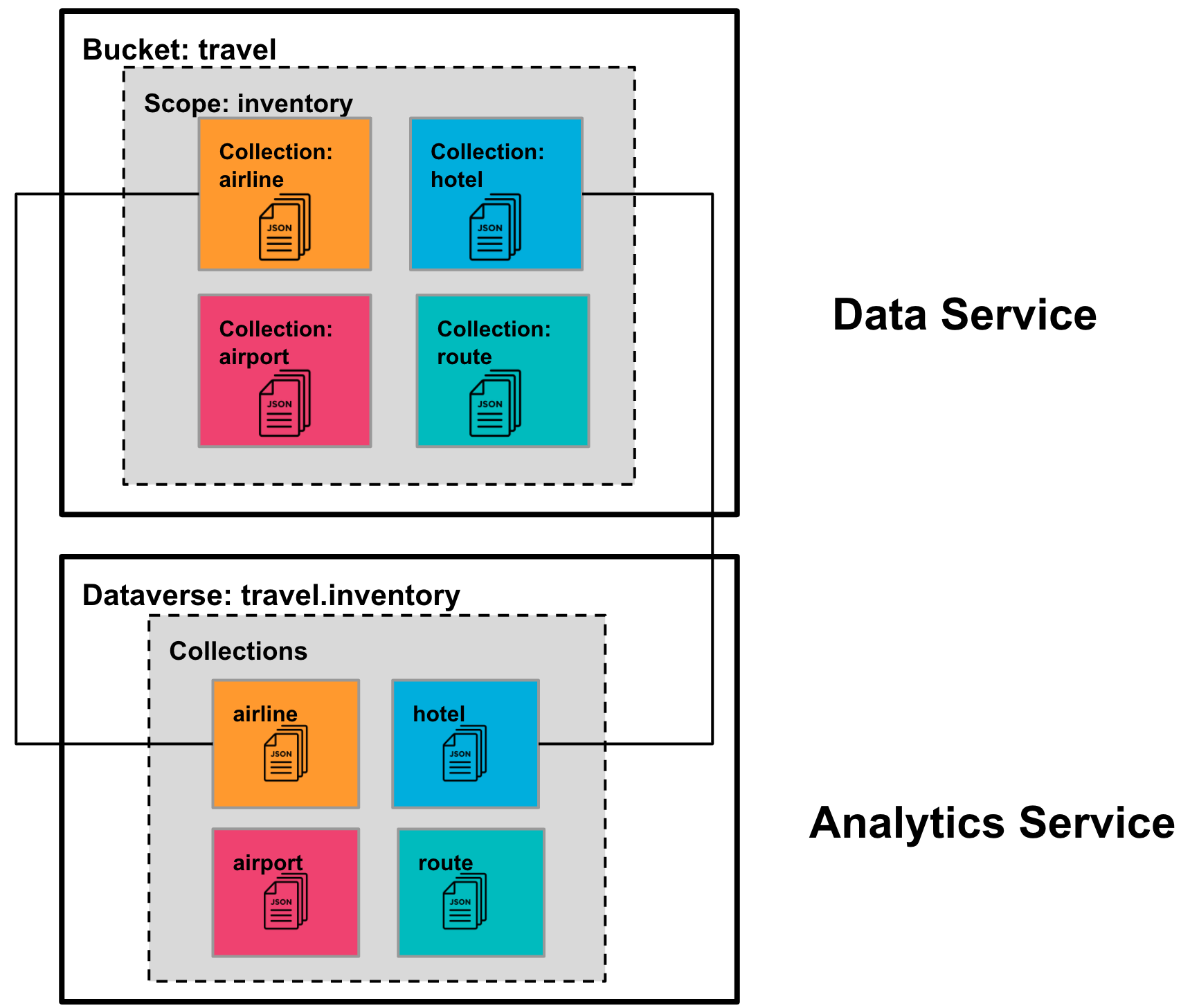
Diagram A
In this architecture, we have a Bucket named travel (similar to a database in a relational database), which contains a Scope called inventory (similar to a schema in an RDBMS), and four Collections named airline, airport, hotel and route (similar to tables in an RDBMS). For each of these Collections, we have four corresponding Analytics Collections (a.k.a. datasets) and organize them within the travel.inventory Scope (a.k.a. dataverse).
A UDF Example Using Couchbase Analytics
For this example, let’s assume your data analytics team needs to frequently query which airlines within a given country fly the most routes and what their percentile ranks are.
Here’s how UDFs help out your team when completing these complex queries.
How to Manage Your UDFs
Your first step is to create the user-defined function in the Analytics Scope (or dataverse) designated as travel.inventory.
Below is the Data Definition Language (DDL) statement to create a UDF that makes your query more succinct:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE OR REPLACE ANALYTICS FUNCTION travel.inventory.getAirlineRank(in_country) { SELECT a.id, a.name AS airline, count(r.id) AS routecount, PERCENT_RANK() OVER (ORDER BY count(r.id)) AS `rank` FROM travel.inventory.airline a JOIN travel.inventory.route r ON a.id = r.airlineid WHERE a.country = in_country GROUP BY a.id, a.name } |
The UDF above takes the parameter in_country as input for the country name and uses it as a filter for the query. Then, the query performs a JOIN between the airline and route Collections and performs aggregations for each airline in order to:
- Count the number of airline routes
- Calculate the percentile rank of route counts using the
PERCENT_RANKfunction with theOVERclause.
(The OVER clause retrieves a specific set of rows relative to the current row and performs an aggregation over the id field. Learn more about window functions in this blog post.)
How to Evaluate Your UDFs
Next, let’s try out your brand-new UDF.
The following query determines the top three airlines for a given country (“United States” in this example).
|
1 2 3 4 5 6 |
SELECT ar.airline as Airline, ROUND(ar.rank*100,2) as Rank, ar.routecount as RouteCount FROM travel.inventory.getAirlineRank("United States") ar ORDER BY ar.route_count desc LIMIT 3; |
The result of evaluating this query shows the top three airlines flying with most routes along with their percentile ranks:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[ { "Rank": 100, "RouteCount": 2354, "Airline": "AMERICAN" }, { "Rank": 96.97, "RouteCount": 2180, "Airline": "UNITED" }, { "Rank": 93.94, "RouteCount": 1981, "Airline": "DELTA" } ] |
How to Drop Your UDFs
Once you no longer need your UDF, you can drop it using this DDL statement below:
|
1 |
DROP ANALYTICS FUNCTION travel.inventory.getAirlineRank(in_country) |
Easy, right?
Conclusion
Reusable user-defined functions are helpful to streamline and modularize your code while also providing more flexibility for your system. I hope you find this new UDF functionality useful for your work with Couchbase Analytics.
I’d love to hear your thoughts and comments below on how you like the new UDF feature and how you’re using it. Or, get a conversation started on the Couchbase Forums. I look forward to hearing from you.
Test drive Couchbase 7 today