XDCR is a high performance asynchronous data replication system used primarily to replicate data between your Couchbase clusters deployed in different data centers. Several Fortune 500 enterprises rely on XDCR for their mission-critical applications. High availability, disaster recovery and data locality are primary applications where XDCR is the go to solution.
XDCR is designed to deliver high throughput and resilient performance for most use cases but there could be cases where it needs to be tuned for optimal performance. We introduced the advanced settings to enable this performance tuning and customization.
The following content is intended to provide generic guidance on XDCR tuning through Advanced Settings that are accessible through Couchbase Administrator Console and supported APIs.
When you first add a replication, you can click on “Show advanced settings” to display the options as shown below:
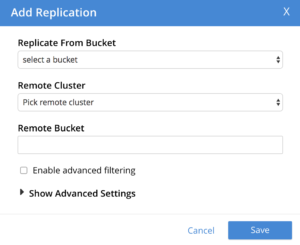
A subset of XDCR settings most relevant to tuning is indicated below. These settings can be used for improving throughput or for conserving network bandwidth.
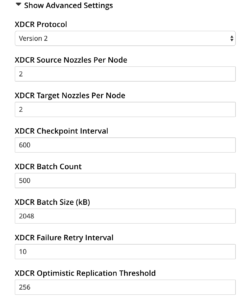
Advanced XDCR Settings
|
Performance Tuning
Some factors influencing performance can be nature of data, data mutation rate, workload on the clusters, network configuration etc., Based on these parameters, replication should be tuned for desired performance.
Some of the best practices for improving throughput or conserving bandwidth are indicated below:
a.Improving throughput:
- Given the resource headroom on source and target clusters, we recommend a range higher than default for Source Nozzle and Target Nozzle
- If your data is composed of documents of size larger than 10K, we recommend tuning your Batch Count and Batch Size to be higher than default
b.Network bandwidth conservation:
- Use an Optimistic Replication Threshold value that is higher than your average document size.
We conducted a bunch of experiments to demonstrate the behavior, which is captured below.
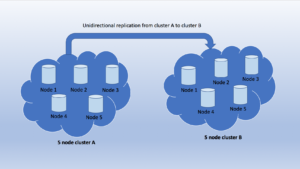
Experiment set up : Cluster A and cluster B are two clusters with unidirectional replication in progress (active data gets replicated from the source cluster to the destination cluster).
Test Environment configuration:
- Two Couchbase clusters running in AWS
- Source cluster : West1 region, target cluster : East1 region
- Average network latency between the clusters at the time of testing : 72ms
- Cluster size : 5 nodes running in dedicated m4.4xlarge instances
- Couchbase Bucket configuration : Bucket Type – Couchbase; Bucket memory quota per node = 60GB; (default settings for replicas, conflict resolution and ejection method)
- Couchbase Server Enterprise R5.0 running on Amazon Linux
- Unidirectional XDCR replication created going from source bucket to target bucket
Test1: Establish baseline
Configuration : Default values for all advanced settings
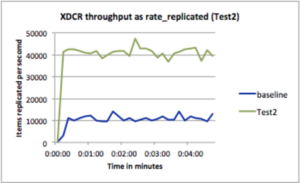
Test2: Demonstrate increased throughput via parallelization
Configuration : Source Nozzle = 8, Target Nozzle = 8 (both 4x), average doc size=1KB
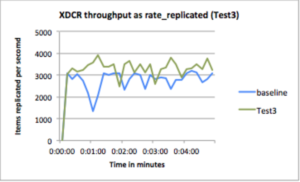
Test3: Demonstrate increased throughput with bigger network payloads
Configuration : Batch Count = 4000, Batch Size = 8192, average doc size=20KB
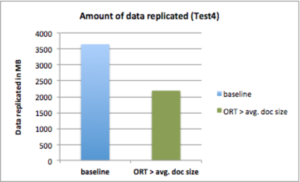
Test4: Demonstrate reduced bandwidth utilization
Configuration : Optimistic Replication Threshold > average document size
Note :
- Test results shown in the charts should not be treated as absolute because a variance of 3-5% could be seen in repetitions of these tests in identical setup due to vagaries of AWS’ cloud environments.
- CPU utilization averaged at or below 40% in all tests.
While we want you to experiment and tune the replication for your desired performance needs, we do advise that you consult with Couchbase before changing XDCR settings for use cases that are highly specialized or highly critical to your business.
Nirvair Singh is the Solution Engineer who has conducted this experiment, please feel free to reach out to me or Nirvair for any further guidance or clarification.
As always, we look forward to learn more about your experiments and experiences.