Ratnopam Chakrabarti is a software developer currently working for Ericsson Inc. He has been focused on IoT, machine-to-machine technologies, connected cars, and smart city domains for quite a while. He loves learning new technologies and putting them to work. When he’s not working, he enjoys spending time with his 3-year-old son.
Full-text based search is a feature that allows users to search based on texts and keywords, and is very popular among users and the developer community. So it’s a no-brainer that there are lots of APIs and frameworks that offer full-text search, including Apache Solr, Lucene, and Elasticsearch, just to name a few. Couchbase, one of the leading NoSQL giants, started rolling out this feature in their Couchbase Server 4.5 release.
In this post, I am going to describe how to integrate the full-text search service into their application using the Couchbase Java SDK.
Set Up
Go to start.spring.io and select Couchbase as a dependency into your Spring boot application.
Once you have the project set up, you should see the following dependency in your project object model (pom.xml) file. It ensures that all Couchbase libraries are in place for the app.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-couchbase</artifactId>
</dependency>
You need to set up a Couchbase bucket to house your sample dataset to search on.
I have created a bucket named “conference” in the Couchbase admin console.
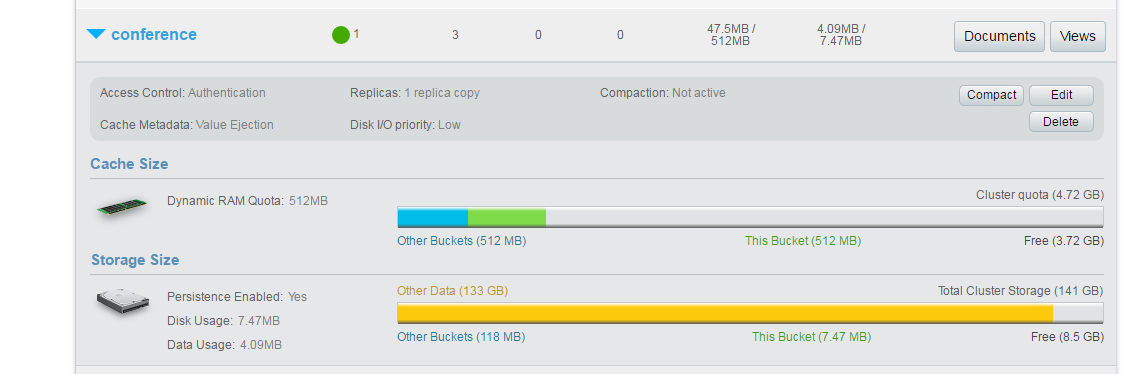
The “conference” bucket has three documents currently, and they hold data about different conferences held across the world. You can extend this data model or create your own if you would like to experiment. For instance, résumés, product catalogs, or even tweets make a good use case for full-text search. For case in point though, let’s stick to the conference data as shown below:
{
“title”: “DockerCon”,
“type”: “Conference”,
“location”: “Austin”,
“start”: “04/17/2017”,
“end”: “04/20/2017”,
“topics”: [
“containers”,
“devops”,
“microservices”,
“product development”,
“virtualization”
],
“attendees”: 20000,
“summary”: “DockerCon will feature topics and content covering all aspects of Docker and it’s ecosystem and will be suitable for Developers, DevOps, System Administrators and C-level executives”,
“social”: {
“facebook”: “https://www.facebook.com/dockercon”,
“twitter”: “https://www.twitter.com/dockercon”
},
“speakers”: [
{
“name”: “Arun Gupta”,
“talk”: “Docker with couchbase”,
“date”: “04/18/2017”,
“duration”: “2”
},
{
“name”: “Laura Frank”,
“talk”: “Opensource”,
“date”: “04/19/2017”,
“duration”: “2”
}
]
}
In order to use full-text search on the above dataset, you need to create a full-text search index first. Do the following steps:
In the Couchbase admin console, click on the Indexes tab.
Click on the Full Text link, which will list the current full text indexes.
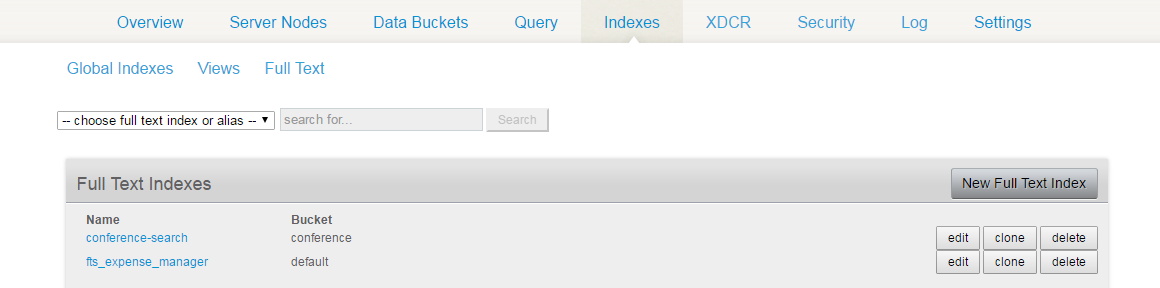
As you can guess, I have created an index named “conference-search” which I would use from the Java code to search the conference-related data.
Click on the New Full Text Index button to create a new index.
Yes, it’s that easy. Once you have created the index, you are ready to use the index from the app you are building.
Before we dive into the code, let’s have a look at the other two documents that are already in the bucket.
Conference::2
{
“title”: “Devoxx UK”,
“type”: “Conference”,
“location”: “Belgium”,
“start”: “05/11/2017”,
“end”: “05/12/2017”,
“topics”: [
“cloud”,
“iot”,
“big data”,
“machine learning”,
“virtual reality”
],
“attendees”: 10000,
“summary”: “Devoxx UK returns to London in 2017. Once again we will welcome amazing speakers and attendees for the very best developer content and awesome experiences”,
“social”: {
“facebook”: “https://www.facebook.com/devoxxUK”,
“twitter”: “https://www.twitter.com/devoxxUK”
},
“speakers”: [
{
“name”: “Viktor Farcic”,
“talk”: “Cloudbees”,
“date”: “05/11/2017”,
“duration”: “2”
},
{
“name”: “Patrick Kua”,
“talk”: “Thoughtworks”,
“date”: “05/12/2017”,
“duration”: “2”
}
]
}
Conference::3
{
“title”: “ReInvent”,
“type”: “Conference”,
“location”: “Las Vegas”,
“start”: “11/28/2017”,
“end”: “11/30/2017”,
“topics”: [
“aws”,
“serverless”,
“microservices”,
“cloud computing”,
“augmented reality”
],
“attendees”: 30000,
“summary”: “Aamazon web services reInvent 2017 promises a larger venue, more sessions and a focus on technologies like microservices and Lambda.”,
“social”: {
“facebook”: “https://www.facebook.com/reinvent”,
“twitter”: “https://www.twitter.com/reinvent”
},
“speakers”: [
{
“name”: “Ryan K”,
“talk”: “Amazon Alexa”,
“date”: “11/28/2017”,
“duration”: “2.5”
},
{
“name”: “Anthony J”,
“talk”: “Lambda”,
“date”: “11/29/2017”,
“duration”: “1.5”
}
]
}
Invoking Full-Text Search from Java Code
Connect to Couchbase bucket from code
Spring boot offers a convenient way to connect to the Couchbase environment by allowing us to specify certain Couchbase environment details as a Spring configuration. We normally specify the following parameters in the application.properties file:
spring.couchbase.bootstrap-hosts=127.0.0.1
spring.couchbase.bucket.name=conference
spring.couchbase.bucket.password=
Here, I have specified my localhost ip since I am running Couchbase Server on my laptop. Note: You can run Couchbase as a Docker container by providing the IP address of the container.
The bucket-name has to match with the name of the bucket created using the Couchbase console.
We can also specify a cluster of IP addresses as bootstrap-hosts. Spring will provide a Couchbase environment cluster with all the nodes running Couchbase on them. If a password was set up when the bucket was created, then we can specify that as well; otherwise, leave that field empty. In our case, we leave it empty.
In order to run query against our desired bucket, first we need to have a reference to the bucket object. And the spring-couchbase configuration does all the heavy lifting behind the scenes for us. All we have to do is inject the bucket from the constructor within the Spring service bean class.
Here is the code:
@Service
public class FullTextSearchService {
private Bucket bucket;
public FullTextSearchService(Bucket bucket) {
this.bucket = bucket;
log.info(“******** Bucket :: = ” + bucket.name());
}
public void findByTextMatch(String searchText) throws Exception {
SearchQueryResult result = getBucket().query(
new SearchQuery(FtsConstants.FTS_IDX_CONF, SearchQuery.matchPhrase(searchText)).fields(“summary”));
for (SearchQueryRow hit : result.hits()) {
log.info(“****** score := ” + hit.score() + ” and content := ”
+ bucket.get(hit.id()).content().get(“title”));
}
}
We can also customize some of the CouchbaseEnvironment settings parameters. For a detailed list of parameters we can customize, take a look at the following reference guidelines:
At this point, we can invoke the service from the CommandLineRunner bean.
@Configuration
public class FtsRunner implements CommandLineRunner {
@Autowired
FullTextSearchService fts;
@Override
public void run(String… arg0) throws Exception {
fts.findByTextMatch(“developer”);
}
}
Using Full-Text Search Service
At the core of the Java SDK, Couchbase offers query() method as a way querying on a specified bucket. If you are familiar with N1QL Query or View Query, then the query() method offers a similar pattern; the only difference for Search is that it accepts a SearchQuery parameter as an argument.
Following is the code that searches for a given text in the “conference” bucket. getBucket() method returns a handle of the bucket.
When creating a SearchQuery, you need to supply the name of the index that you created in the Set Up section above. Here, I am using “conference-search” as the index which is specified in the FtsConstants.FTS_IDX_CONF. By the way, the full source code of the app is uploaded in GitHub and available for download. The link is at the end of the post.
public static void findByTextMatch(String searchText) throws Exception {
SearchQueryResult result = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, SearchQuery.matchPhrase(searchText)).fields(“summary”));
log.info(“****** total hits := “+ result.hits().size());
for (SearchQueryRow hit : result.hits()) {
log.info(“****** score := ” + hit.score() + ” and content := “+ bucket.get(hit.id()).content().get(“title”));
}
}
The above code is searching on the “summary” field of the documents in the bucket by using the matchPhrase(searchText) method.
The code is invoked by a simple call:
findByTextMatch(“developer”);
So, the full-text search should return all documents in the conference bucket that have the text “developer” in their summary field. Here’s the output:
Opened bucket conference
****** total hits := 1
****** score := 0.036940739161339185 and content := Devoxx UK
The total hits represent the total number of matches found. Here it’s 1 and the corresponding scoring of that match can also be found. The code doesn’t print the entire document, just outputs the conference title. You can print the other attributes of the document if you wish to.
There are other ways of using the SearchQuery which are discussed next.
Fuzzy Text Search
You can perform fuzzy query by specifying a maximum Levenshtein distance as the maximum fuzziness() to allow on the term. The default fuzziness is 2.
For example, let’s say I want to find the conference where “sysops” is one of the “topics”. From the dataset above, you can see there’s no “sysops” topics present in any of the conferences. The closest match is “devops”; however, that is 3 Levenshtein distance away. So, if I run the following code with fuzziness 1 or 2 it shouldn’t bring back any result, which it doesn’t.
SearchQueryResult resultFuzzy = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, SearchQuery.match(searchText).fuzziness(2)).fields("topics"));
log.info(“****** total hits := “+ resultFuzzy.hits().size());
for (SearchQueryRow hit : resultFuzzy.hits()) {
log.info(“****** score := ” + hit.score() + ” and content := “+ bucket.get(hit.id()).content().get(“topics”));
}
findByTextFuzzy(“sysops”); gives the following output:
total hits := 0
Now, if I change the fuzziness to “3” and invoke the same code again, I get a document back. Here goes:
****** total hits := 1
****** score := 0.016616112953992054 and content := [“containers”,”devops“,”microservices”,”product development”,”virtualization”]
Since “devops” matches “sysops” with a fuzziness of 3, the search is able to find the document.
Regular Expression Query
You can do regular expression-based queries using SearchQuery. The following code makes use of the RegExpQuery to search on “topics” based on a supplied pattern.
RegexpQuery rq = new RegexpQuery(regexp).field("topics");
SearchQueryResult resultRegExp = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, rq));
log.info(“****** total hits := “+ resultRegExp.hits().size());
for (SearchQueryRow hit : resultRegExp.hits()) {
log.info(“****** score := ” + hit.score() + ” and content := “+ bucket.get(hit.id()).content().get(“topics”));
}
When invoked as
findByRegExp(“[a-z]*\\s*reality”);
It returns the following 2 documents:
****** total hits := 2
****** score := 0.11597946228887497 and content := [“aws”,”serverless”,”microservices”,”cloud computing”,”augmented reality“]
****** score := 0.1084888528694293 and content := [“cloud”,”iot”,”big data”,”machine learning”,”virtual reality“]
Querying by Prefix
Couchbase enables you to query based on a “prefix” of a text element. The API searches for texts that start with the specified prefix. The code is simple to use; it searches on the “summary” field of the document for the texts that have the supplied prefix.
PrefixQuery pq = new PrefixQuery(prefix).field("summary");
SearchQueryResult resultPrefix = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, pq).fields(“summary”));
log.info(“****** total hits := “+ resultPrefix.hits().size());
for (SearchQueryRow hit : resultPrefix.hits()) {
log.info(“****** score := ” + hit.score() + ” and content := “+ bucket.get(hit.id()).content().get(“summary”));
}
If you invoke the code as findByPrefix(“micro”);
You get the following output:
****** total hits := 1
****** score := 0.08200986407165835 and content := Aamazon web services reInvent 2017 promises a larger venue, more sessions and a focus on technologies like microservices and Lambda.
Query by Phrase
The following code lets you query a phrase in a text.
MatchPhraseQuery mpq = new MatchPhraseQuery(matchPhrase).field("speakers.talk");
SearchQueryResult resultPrefix = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, mpq).fields(“speakers.talk”));
log.info(“****** total hits := “+ resultPrefix.hits().size());
for (SearchQueryRow hit : resultPrefix.hits()) {
log.info(“****** score := ” + hit.score() + ” and content := “+ bucket.get(hit.id()).content().get(“title”) + ” speakers = “+bucket.get(hit.id()).content().get(“speakers”));
}
Here, the query is looking for a phrase in the “speakers.talk” field and returns the match if found.
A sample invocation of the above code with
findByMatchPhrase(“Docker with couchbase”) gives the following expected output:
****** total hits := 1
****** score := 0.25054427342401087 and content := DockerCon speakers = [{“duration”:”2″,”date”:”04/18/2017″,”talk”:”Docker with couchbase“,”name”:”Arun Gupta”},{“duration”:”2″,”date”:”04/19/2017″,”talk”:”Opensource”,”name”:”Laura Frank”}]
Range Query
Full-ext search is also pretty useful when it comes to range-based searching – be it a numeric range or even a date range. For example, if you want to find out the conference(s) where the number of attendees fall within a range, you can easily do that by,
findByNumberRange(5000, 30000);
Here, the first argument is the min of the range and the second argument is the max of the range.
Here’s the code that gets triggered:
NumericRangeQuery nrq = new NumericRangeQuery().min(min).max(max).field("attendees");
SearchQueryResult resultPrefix = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, nrq).fields(“title”, “attendees”, “location”));
log.info(“****** total hits := “+ resultPrefix.hits().size());
for (SearchQueryRow hit : resultPrefix.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info(“****** score := ” + hit.score() + ” and title := “+ row.content().get(“title”) + ” attendees := “+ row.content().get(“attendees”) + ” location := ” + row.content().get(“location”));
}
And it gives the following output – the conferences that have attendees falling between the supplied range are returned.
****** total hits := 2
****** score := 5.513997563179222E-5 and title := DockerCon attendees := 20000 location := Austin
****** score := 5.513997563179222E-5 and title := Devoxx UK attendees := 10000 location := Belgium
Combination Query
Couchbase full-text search service allows you to use a combination of queries according to your need. To demonstrate this, let’s first invoke the API by supplying two arguments.
findByMatchCombination(“aws”, “containers”);
Here, the client code is trying to use the combination search based on “aws” and “containers”. Let’s look at the query API now.
MatchQuery mq1 = new MatchQuery(text1).field("topics");
MatchQuery mq2 = new MatchQuery(text2).field(“topics”);
SearchQueryResult match1Result = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, mq1).fields(“title”, “attendees”, “location”, “topics”));
log.info(“****** total hits for match1 := “+ match1Result.hits().size());
for (SearchQueryRow hit : match1Result.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info(“****** scores for match 1 := ” + hit.score() + ” and title := “+ row.content().get(“title”) + ” attendees := “+ row.content().get(“attendees”) + ” topics := ” + row.content().get(“topics”));
}
SearchQueryResult match2Result = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, mq2).fields(“title”, “attendees”, “location”, “topics”));
log.info(“****** total hits for match2 := “+ match2Result.hits().size());
for (SearchQueryRow hit : match2Result.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info(“****** scores for match 2:= ” + hit.score() + ” and title := “+ row.content().get(“title”) + ” attendees := “+ row.content().get(“attendees”) + ” topics := ” + row.content().get(“topics”));
}
ConjunctionQuery conjunction = new ConjunctionQuery(mq1, mq2);
SearchQueryResult result = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, conjunction).fields(“title”, “attendees”, “location”, “topics”));
log.info(“****** total hits for conjunction query := “+ result.hits().size());
for (SearchQueryRow hit : result.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info(“****** scores for conjunction query:= ” + hit.score() + ” and title := “+ row.content().get(“title”) + ” attendees := “+ row.content().get(“attendees”) + ” topics := ” + row.content().get(“topics”));
}
DisjunctionQuery dis = new DisjunctionQuery(mq1, mq2);
SearchQueryResult resultDis = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, dis).fields(“title”, “attendees”, “location”, “topics”));
log.info(“****** total hits for disjunction query := “+ resultDis.hits().size());
for (SearchQueryRow hit : resultDis.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info(“****** scores for disjunction query:= ” + hit.score() + ” and title := “+ row.content().get(“title”) + ” attendees := “+ row.content().get(“attendees”) + ” topics := ” + row.content().get(“topics”));
}
BooleanQuery bool = new BooleanQuery().must(mq1).mustNot(mq2);
SearchQueryResult resultBool = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, bool).fields(“title”, “attendees”, “location”, “topics”));
log.info(“****** total hits for booelan query := “+ resultBool.hits().size());
for (SearchQueryRow hit : resultBool.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info(“****** scores for resultBool query:= ” + hit.score() + ” and title := “+ row.content().get(“title”) + ” attendees := “+ row.content().get(“attendees”) + ” topics := ” + row.content().get(“topics”));
}
First, individual matches are found based on the texts. We find the result set document/s matching “aws” as one of the topics of the conference. In the same way, we find the documents having “containers” as topics.
Next, we start combining the individual results to form combination queries.
Conjunction Query
Conjunction query would return all matching conferences that have both “aws” and “containers” listed as topics. Our current dataset doesn’t have such a conference yet; so as expected, when we run the query we don’t get back any matching documents.
****** total hits for match1 := 1 — this matches “aws”
****** scores for match 1 := 0.11597946228887497 and title := ReInvent attendees := 30000 topics := [“aws”,”serverless”,”microservices”,”cloud computing”,”augmented reality”]
****** total hits for match2 := 1 — this matches “containers”
****** scores for match 2:= 0.12527214351929328 and title := DockerCon attendees := 20000 topics := [“containers”,”devops”,”microservices”,”product development”,”virtualization”]
****** total hits for conjunction query := 0
Disjunction Query
Disjunction query would return all matching conferences if any one of the candidate queries return a match. Since each of the individual match queries return one conference each, when we run our disjunction query, we get back both those results.
****** total hits for disjunction query := 2
****** scores for disjunction query:= 0.018374455634478874 and title := DockerCon attendees := 20000 topics := [“containers“,”devops”,”microservices”,”product development”,”virtualization”]
****** scores for disjunction query:= 0.01701143945069833 and title := ReInvent attendees := 30000 topics := [“aws“,”serverless”,”microservices”,”cloud computing”,”augmented reality”]
Boolean Query
Using bBoolean query, we can combine different combinations of match queries. For example, BooleanQuery bool = new BooleanQuery().must(mq1).mustNot(mq2) returns all conferences that must match the first term query result which is mq1 and at the same time it must not match mq2. You can flip the combination around.
The output of our code is as follows:
****** total hits for booelan query := 1
****** scores for resultBool query:= 0.11597946228887497 and title := ReInvent attendees := 30000 topics := [“aws“,”serverless”,”microservices”,”cloud computing”,”augmented reality”]
It returns the conference that has a topic named “aws” (which, by the way, is the same as mq1) and does not have a topic named “containers” (i.e., mq2). The only conference that satisfies both the these conditions is titled “ReInvent” and that gets returned as output.
I hope you found the post useful. The source code can be found online. For a general idea about the Couchbase full-text search service, refer to the following blog post for some useful insights: