Vector embeddings are a critical component in machine learning that convert “high-dimensional” information, such as text or images, into a structured vector space. This process enables the ability to process and identify related data more effectively by representing it as numerical vectors. In this post, you’ll learn how to create vector embeddings, their types, and their deployment in various use cases.
Vector Embeddings Explained
Vector embeddings are like translating information we understand into something a computer understands. Imagine you’re trying to explain the concept of “Valentine’s Day” to a computer. Since computers don’t understand concepts like holidays, romance, and the cultural context the way we do, we have to translate them into something they DO understand: numbers. That’s what vector embeddings do. They represent words, pictures, or any kind of data in a list of numbers that represent what those words or images are all about.
For example, with words, if “cat” and “kitten” are similar, when processed through a (large) language model, their number lists (i.e., vectors) will be pretty close together. It’s not just about words, though. You can do the same thing with photos or other types of media. So, if you have a bunch of pictures of pets, vector embeddings help a computer see which ones are similar, even if it doesn’t “know” what a cat is.
Let’s say we’re turning the words “Valentine’s Day” into a vector. The string “Valentine’s Day” would be given to some model, typically an LLM (large language model), which would produce an array of numbers to be stored alongside the words.
|
1 2 3 4 |
{ "word": "Valentine's Day", "vector": [0.12, 0.75, -0.33, 0.85, 0.21, ...etc...] } |
Vectors are very long and complex. For instance, OpenAI’s vector size is typically 1536, which means each embedding is an array of 1536 floating point numbers.
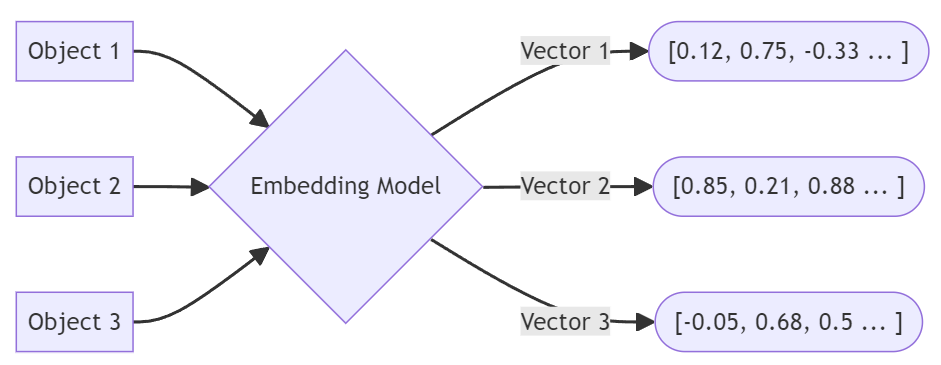
By itself, this data doesn’t really mean much: it’s all about finding other embeddings that are close.
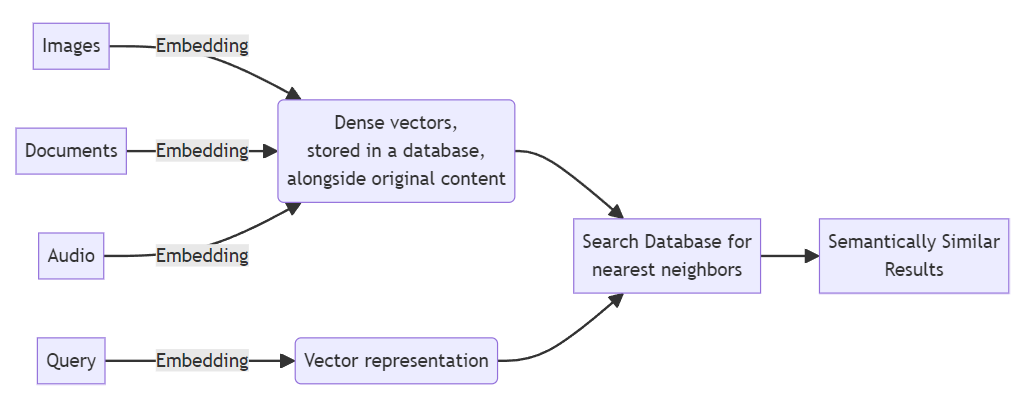
In this diagram, a nearest neighbor algorithm can find data with vectors close to the vectorized query. These results are returned in a list (ordered by their proximity).
Types of Vector Embeddings
There are several types of embeddings, each with its unique way of understanding and representing data. Here’s a rundown of the main types you might come across:
Word Embeddings: Word embeddings translate single words into vectors, capturing the essence of their meaning. Popular models like Word2Vec, GloVe, and FastText are used to create these embeddings. These can help to show the relationship between words, like understanding that “king” and “queen” are related in the same way as “man” and “woman.”
Here’s an example of Word2Vec in action:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from gensim.models import Word2Vec sentences = [ "Couchbase is a distributed NoSQL database.", "Couchbase Capella provides flexibility and scalability.", "Couchbase supports SQL++ for querying JSON documents.", "Couchbase Mobile extends the database to the edge.", "Couchbase has a built-in Full Text Search Engine" ] # Preprocess the sentences: tokenize and lower case processed_sentences = [sentence.lower().split() for sentence in sentences] # Train the Word2Vec model model = Word2Vec(sentences=processed_sentences, vector_size=100, window=5, min_count=1, workers=4) # Get the vector for a word word_vector = model.wv['couchbase'] # Print the vector print(word_vector) This Python code would output something like: [-0.00053675, 0.000236998, 0.00510486, 0.00900848, ..., 0.000901757, 0.00639282] |
Sentence and Document Embeddings: Moving beyond single words, sentence and document embeddings represent larger pieces of text. These embeddings can capture the context of an entire sentence or document, not just individual words. Models like BERT and Doc2Vec are good examples. They’re used in tasks that require understanding the overall message, sentiment, or topic of texts.
Image Embeddings: These convert images into vectors, capturing visual features like shapes, colors, and textures. Image embeddings are created using deep learning models (like CNNs: Convolutional Neural Networks). They enable tasks such as image recognition, classification, and similarity searches. For example, an image embedding might help a computer recognize whether a given picture is a hot dog or not.
Graph Embeddings: Graph embeddings are used to represent relationships and structures, such as social networks, org charts, or biological pathways. They turn the nodes and edges of a graph into vectors, capturing how items are connected. This is useful for recommendations, clustering, and detecting communities (clusters) within networks.
Audio Embeddings: Similar to image embeddings, audio embeddings translate sound into vectors, capturing features like pitch, tone, and rhythm. These are used in voice recognition, music analysis, and sound classification tasks.
Video Embeddings: Video embeddings capture both the visual and temporal dynamics of videos. They’re used for activities like video search, classification, and understanding scenes or activities within the footage.
How to Create Vector Embeddings
Generally speaking, there are four steps:
-
- Choose Your Vector Embedding Model: Decide on the type of model based on your needs. Word2Vec, GloVe, and FastText are popular for word embeddings, while BERT and GPT-4 are used for sentence and document embeddings, etc.
- Prepare Your Data: Clean and preprocess your data. For text, this can include tokenization, removing “stopwords,” and possibly lemmatization (reducing words to their base form). For images, this might include resizing, normalizing pixel values, etc.
- Train or Use Pre-trained Models: You can train your model on your dataset or use a pre-trained model. Training from scratch requires a significant amount of data, time, and computational resources. Pre-trained models are a quick way to get started and can be fine-tuned (or augmented) with your specific dataset.
- Generate Embeddings: Once your model is ready, feed your data through it (via SDK, REST, etc.) to generate embeddings. Each item will be transformed into a vector that represents its semantic meaning. Typically, the embeddings are stored in a database, sometimes right alongside the original data.
Applications of Vector Embeddings
So, what’s the big deal with vector? What problems can I attack with it? Here are several use cases that are enabled by using vector embeddings to find semantically similar items (i.e., “vector search”):
Natural Language Processing (NLP)
-
- Semantic Search: Improving search relevance and user experience by better utilizing the meaning behind search terms, above and beyond traditional text-based searching.
- Sentiment Analysis: Analyzing customer feedback, social media posts, and reviews to gauge sentiment (positive, negative, or neutral).
- Language Translation: Understanding the semantics of the source language and generating appropriate text in the target language.
Recommendation Systems
-
- E-commerce: Personalizing product recommendations based on browsing and purchase history.
- Content Platforms: Recommending content to users based on their interests and past interactions.
Computer Vision
-
- Image Recognition and Classification: Identifying objects, people, or scenes in images for applications like surveillance, tagging photos, identifying parts, etc.
- Visual Search: Enabling users to search with images instead of text queries.
Healthcare
-
- Drug Discovery: Helping to identify interactions.
- Medical Image Analysis: Diagnosing diseases by analyzing medical images such as X-rays, MRIs, and CT scans.
Finance
-
- Fraud Detection: Analyzing transaction patterns to identify and prevent fraudulent activities.
- Credit Scoring: Analyzing financial history and behavior.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation is an approach that combines the strengths of pre-trained generative language models (like GPT-4) with information retrieval capabilities (like vector search) to enhance the generation of responses.
RAG can augment a query to an LLM like GPT-4 with up-to-date and relevant domain information. There are two steps:
-
- Query for relevant documents.
Vector search is particularly good at identifying relevant data, but any querying can work, including analytical queries that Couchbase columnar makes possible. - Pass the results of the query as context to the generative model, along with the query itself.
- Query for relevant documents.
This approach allows the model to produce more informative, accurate, and contextually relevant answers.
Use cases for RAG include:
-
- Question Answering: Unlike closed-domain systems that rely on a fixed dataset, RAG can access up-to-date information from its knowledge source.
- Content Creation: RAG can augment content with relevant facts and figures, ensuring better accuracy.
- Chatbots/Assistants: Bots like Couchbase Capella iQ can provide more detailed and informative responses across a wide range of topics.
- Educational Tools: RAG can provide detailed explanations or supplemental information on a wide array of subjects tailored to the user’s queries.
- Recommendation Systems: RAG can generate personalized explanations or reasons behind recommendations by retrieving relevant information that matches the user’s interests or query context.
Vector Embeddings and Couchbase
Couchbase is a multi-purpose database that excels in managing JSON data. This flexibility applies to vector embeddings, as Couchbase’s schemaless nature allows for the efficient storage and retrieval of complex, multi-dimensional vector data alongside traditional JSON documents (as shown earlier in this blog post)
|
1 2 3 4 |
{ "word": "Valentine's Day", "vector": [0.12, 0.75, -0.33, 0.85, 0.21, ...etc...] } |
Couchbase’s strength lies in its ability to handle a wide range of data types and use cases within a single platform, contrasting with specialized, single-purpose vector databases (like Pinecone) focused solely on vector search and similarity. Benefits of Couchbase’s approach include:
Hybrid Query: With Couchbase, you can combine SQL++, key/value, geospatial, and full-text search into a single query to reduce post-query processing and more quickly build a rich set of application features.
Versatility: Couchbase supports key-value, document, and full-text search, as well as real-time analytics and eventing, all within the same platform. This versatility allows developers to use vector embeddings for advanced search and recommendation features without needing a separate system.
Scalability and Performance: Designed for high performance and scalability, Couchbase ensures that applications using vector embeddings can scale out efficiently to meet growing data and traffic demands.
Unified Development Experience: Consolidating data use cases into Couchbase simplifies the development process. Teams can focus on building features rather than managing multiple databases, integrations, and data pipelines.
Next Steps
Give Couchbase Capella a try, and see how a multi-purpose database can help you build powerful, adaptive applications. You can also download the on-prem server version of Couchbase Server 7.6, complete with vector search integration.
You can get up and running in minutes with a free trial (no credit card needed). Capella iQ’s generative AI is built right in and can help you start writing your first queries.
Vector Embedding FAQs
What is the difference between text vectorization and embedding?
Text vectorization is a way to count the occurrences of words in a document. Embedding represents the semantic meaning of words and their context.
What is the difference between indexing and embedding?
Embedding is the process of generating the vectors. Indexing is the process that enables the retrieval of the vectors and their neighbors.
What content types can be embedded?
Words, text, images, documents, audio, video, graphs, networks, etc.
How do vector embeddings support generative AI?
Vector embeddings can be used to find context to augment the generation of responses. See the above section on RAG.
What are embeddings in machine learning?
A mathematical representation of data used to represent the data compactly and to find similarities between data.