What is Vector Search?
Developers are flocking to vector search to make their applications more adaptive to their users. As the term search implies, vector search is for finding and comparing objects using a concept known as vectors. Put simply, it helps you find similarity between objects, allowing you to find complex, contextually-aware relationships within your data. It’s a technology that sits behind and powers next-gen search-related applications.
Vector search is an AI-powered search feature in modern data platforms, such as vector databases, that helps users build more flexible applications. No longer are you limited to basic keyword searching; instead, you can find semantically similar information across any kind of digital media.
At its core, it’s one of many machine learning systems powered by large language models (LLMs) of various sizes and complexity. These are available through databases and traditional platforms and are even being pushed to the edge to run on mobile devices.
To learn more about vector search, related terms, capabilities, and how it applies to modern database technology innovations in artificial intelligence (AI), continue reading.
What Does Vector Mean?
A vector is a data structure that holds an array of numbers. In our case, this refers to vectors that store a digital summary of the data set they were applied to. It can be thought of as a fingerprint or a summary but formally is called an embedding. Here’s a quick example of how one might look:
|
1 |
"blue t-shirts": [-0.02511234 0.05473123 -0.01234567 ... 0.00456789 0.03345678 -0.00789012] |
Benefits of Vector Search
Vector search gives a range of new capabilities to databases and the applications that use them. In a nutshell, vector search helps users find more contextually-aware matches within a large collection of information (aka corpus). The idea of closeness is important–vector search statistically groups items together to show how similar or related they are. This applies across much more than just text, though many of our examples are text-based to help compare to traditional search systems.
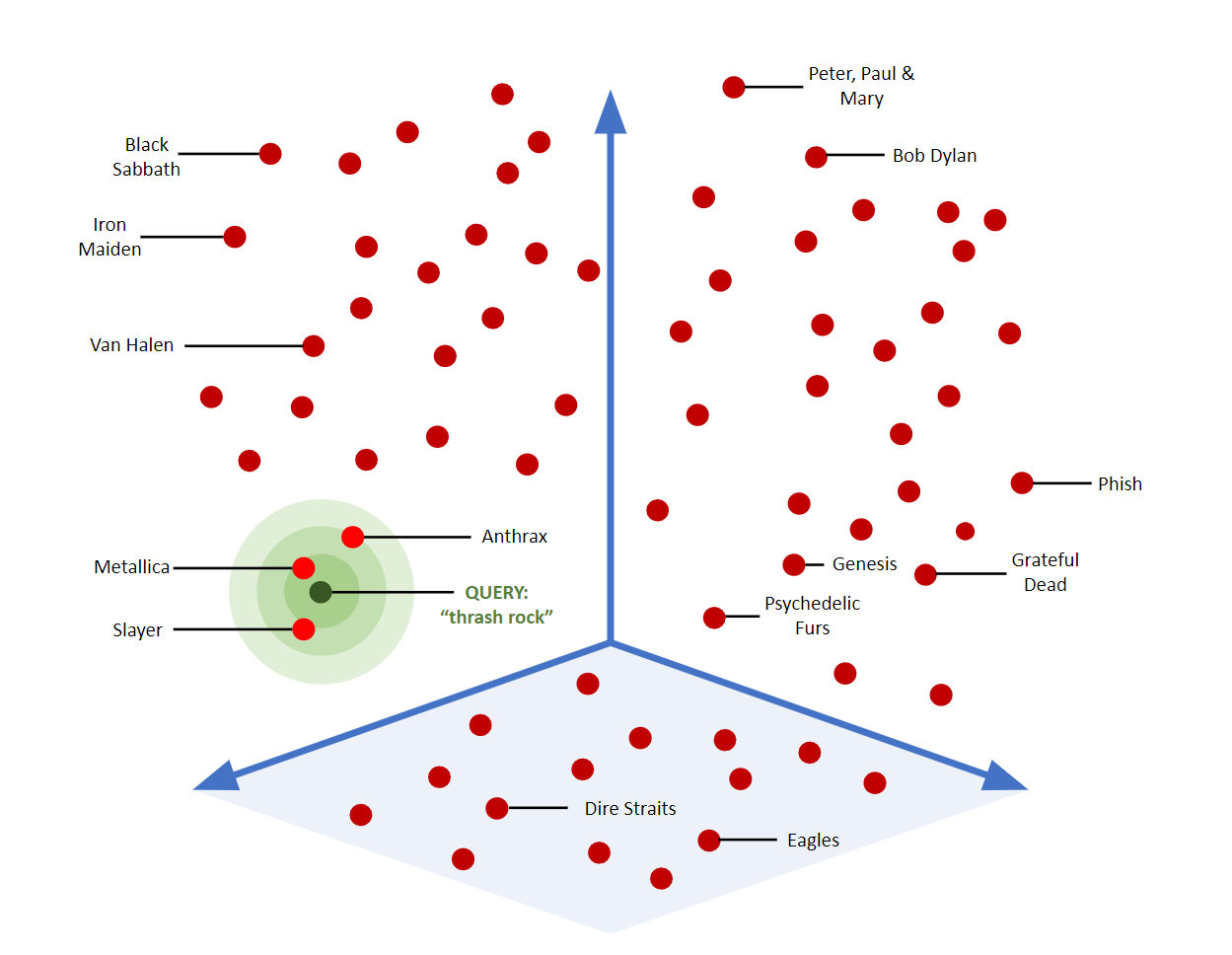
This graph shows a visual example of how vector searching can map, find, and group “similar” objects in 3D space.
Access to Vast General Knowledge
Vector search is also a great strategy for introducing artificial intelligence tooling into an application, giving adaptive flexibility impossible with traditional search tooling alone. Due to the large volume of public LLMs available, any company can adopt one and use it as a basis for search in their applications. Because LLMs store a lot of information, the results from searching them can add exponential value to your application without having to write any complex code. It’s one way many applications are being updated with new powerful features.
Superpowered vs. Traditional Search
Fortunately, vector search is also a faster search approach in more complex scenarios. Traditional keyword-based search systems can be optimized to find matching text in documents, but once you need to apply complex fuzzy matching algorithms or extreme Boolean predicate workarounds (many WHERE clauses, for example), it starts to be slower and more complex.
The various tradeoffs needed to search in complex environments successfully can be avoided with vector search. However, the tradeoff will need a service-level API (e.g., OpenAI) with adequate resources to help you interface applications to an LLM. You will also have choices and limitations depending on the LLM sitting behind your vector search system.
What is the Difference Between Traditional Search and Vector Search?
The above benefits overlap with some of the technical differences between traditional and vector search approaches. In this section, we investigate what really matters between these different approaches.
Context and Semantic Search
Many different search-related systems have used keyword or phrase searching optimized to find precise textual matches or to find documents that use a keyword most often. The challenge is that these can lack context and flexibility. For example, a text search for “tree” may never match data with actual tree species’ names, even though it would be highly relevant. This kind of contextual matching is a form of semantic search–where context and relationship between words matter.
Similarity
Vector search isn’t only about semantic relationships, though. For example, in a text-based application it goes beyond using single words and phrases to finding similar matching documents by using input words, sentences, paragraphs, or more–looking for text examples that match semantics and context on a very deep level.
Searching for similarity works for images as well. If you were to write an application that compares two images together, how would you do it? If you just compared each pixel in one to each pixel in another, you would only find images that are identical in color, resolution, encoding, etc. But if you could analyze your images and produce a vector embedding for the content, you can compare them and find matches. Applied to the images example, a vector embedding describes the content in each image and then lets you compare them–a much more robust way of comparing and finding “nearness” between them.
You can learn more about vector embedding in our other blog post in detail, or read on to get a basic overview.
How Vector Search Works
Vector search creates and compares vector embeddings. It works on the principle that data can be turned into a numeric vector representation (embedding) and compared to other data cataloged with a similar digital representation (using LLMs).
It indexes different types of digital content (text, audio, video, etc.) into a common language that neural networks understand. See our guide to generative AI that discusses generative adversarial networks (GANs) to learn more about neural network approaches.
Models created by LLMs hold the vectors representing the data the model was trained on. For example, each paragraph from Wikipedia could be summarized and indexed as vectors. Then, a user can submit a vector of their own data (usually created through an embedding process) to a vector search system to find similar paragraphs.
There is a lot of heavy lifting behind those steps, but that is the essence.
Three Steps to Building a Vector Search Application
There are three stages to building or using a vector search application. These include:
-
- Creating embeddings for your custom data or query
- Comparing results with a vector engine trained on large language models (LLMs) to find the best semantic data match to the corpus of data in the model
- Comparing LLM results to your custom application data or database to find more relevant matches
Step 1 – Create Embeddings of a Request
Embeddings act like the fingerprint of a piece of data in vector applications, much like a key that can be used in an index later on. A piece of data (text, images, video, etc.) gets sent to a vector embedding application that turns it into a numerical representation as a list of numbers (a vector). This vector embedding represents the object that was supplied to the embedding application. Behind the scenes, a large language model (LLM) engine is used to create the embedding so that it can then be used to retrieve matches from the same LLM in the next step.
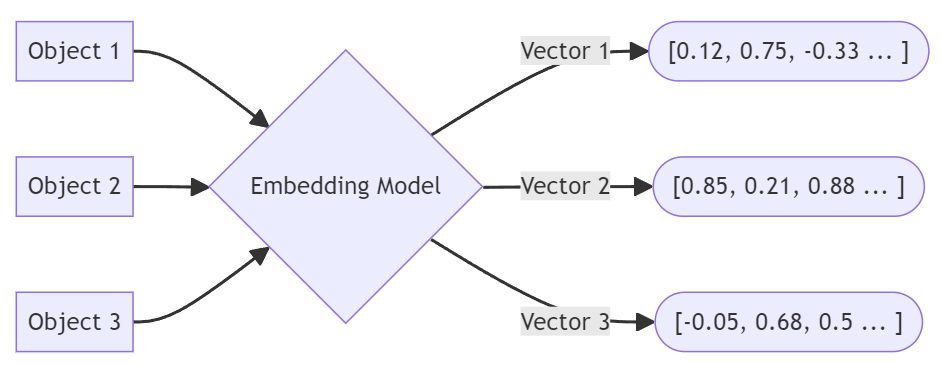
Objects are put through a vector embedding process.
In the database world, text from a table column could be run through the embedding engine, and the vector object could be saved in a property for that row or JSON object. The embeddings for each document or record are then indexed for future internal comparisons during a search request.
Let’s consider a web app that lets you search a retail catalog. A user might enter text describing a type of clothing and color to search for availability. From there, the app sends the user request to an LLM as part of the vector embedding process. The LLM is used to compute a vector representation for use in the next step. “Blue t-shirts” may become a vector that looks like this in a high-dimensional array, as shown here stored in JSON:
|
1 2 3 4 |
{ "word": "blue t-shirt", "embedding": [0.72, -0.45, 0.88, 0.12, -0.65, 0.31, 0.55, 0.76] } |
This is an overly simplified example, but at its root, vector embeddings are simply multidimensional arrays summarizing a piece of data analyzed by a particular machine learning process. Embeddings come in different types and sizes and are based on a wide range of different LLMs, but that is beyond the scope of this article.
Step 2 – Find Matches from an LLM
Now, consider that an LLM has essentially created embeddings for all the pieces of data that it was built upon. If Wikipedia was used to train the LLM, then perhaps each paragraph might have produced its own embeddings. Lots of embeddings!
The searching stage is the process of finding embeddings that most closely match each other. A vector search engine may take an existing embedding or create one on the fly from a search query. For example, it may take user text input in an application or database query and use the LLM to find similar content from the model. Then, it returns the most relevant matches to the application.
Continuing our retail example, the “blue t-shirts” vector embedding can be used as a key to find similar pieces of data. The app would send that vector to a central LLM to find the most similar and semantically related content based on the text descriptions or images analyzed when building the LLM.
For example, you may get back a list of five documents that matched for similarity in their vector embeddings. As you can see, each has its own vector representation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{ "embeddings": [ { "word": "blue t-shirt", "embedding": [0.72, -0.45, 0.88, 0.12, -0.65, 0.31, 0.55, 0.76] }, { "word": "navy shirt", "embedding": [0.71, -0.42, 0.85, 0.15, -0.68, 0.29, 0.53, 0.78] }, { "word": "azure top", "embedding": [0.73, -0.46, 0.87, 0.11, -0.64, 0.33, 0.56, 0.74] }, { "word": "cobalt blouse", "embedding": [0.75, -0.41, 0.89, 0.14, -0.67, 0.28, 0.54, 0.77] }, { "word": "sapphire tee", "embedding": [0.72, -0.44, 0.86, 0.13, -0.66, 0.30, 0.55, 0.76] }, { "word": "denim shirt", "embedding": [0.70, -0.43, 0.84, 0.16, -0.69, 0.27, 0.52, 0.79] } ] } |
Step 3 – Find Matches to Your Own Data
If all you’re looking for are matches to information that was stored in an LLM, then you’re done. However, truly adaptive applications will want to draw matches and information from internal data sources like a corporate database.
Assume the documents or records in the database have vector embeddings saved in them already, plus you have the matches from the LLM. Now, you can take those, send them to your database vector search capability, and find related database documents. Operationally, it would look like another indexed field but give a more qualitative feel to the search results.
How Does Vector Search Find Matches?
Vector search combines three concepts: user-generated data (a request), an LLM corpus that includes models representing a data source (a model), and custom data in a database (custom matching). Vector search allows these three factors to work together.
What Can Vector Search Support?
Vector search will find similarity between any kind of data as long as it can create embeddings and compare them with others created the same way (from the same LLM).
Depending on the LLM used, results can vary dramatically because of the source data on which the LLM was trained. For example, if you want to search for similar images but use an LLM that only includes classical literature, you’ll get unusable responses (though if they were pictures of classical writers, there might be some hope).
Likewise, if you are building a legal case and your LLM is only trained on Reddit data, you’ll be setting yourself up for a unique scenario that might make a great movie someday (after you’re disbarred, of course).
This is why making sure that the LLM powering your experience is targeting the correct vector search use case and information you require is important. Very large general LLMs will have more context, but specialized LLMs for your industry will have more accurate and nuanced information for your business.
How Vector Search is Conducted at Scale
Any enterprise system that performs vector search must be able to scale when it goes into production (see our guide to cloud data replication). This makes vector search systems that can replicate and shard their indexes particularly crucial.
When the system needs to search the index to find matches, the workload can then be distributed across multiple nodes.
Likewise, creating new embeddings and indexing them will also benefit from resource isolation, so other application functions are not impacted. Resource isolation means that vector search-related functions have their own memory, CPU, and storage resources.
In a database context, it is essential that all services are properly allocated resources so services do not compete. For example, table queries, real-time analytics, logging, and data storage services all need their own room to breathe in addition to vector search services.
Distributed APIs for LLM access are important, too. As many other services may be calling for embeddings, the APIs and systems producing the embeddings must also be able to grow with more traffic. For cloud-based LLM services, make sure that your production requirements can be met by their service level agreements before you start prototyping.
The use of external services can often scale quickly and efficiently but will require additional funding as it scales higher. Ensure sliding price scales are clearly understood when evaluating options.
The Future of Vector Search
Adaptive application development will be powered by hybrid search scenarios. A single search or query method will no longer be sufficient for the flexibility needed going forward. Hybrid search capabilities mean you can use vector search to get semantic matches but narrow down results using basic SQL predicates and even geographic queries using a spatial index.
Coupling these into a single hybrid search experience will make it easier for developers to extract maximum flexibility from their applications. This will include extending all vector search capabilities to the edge with mobile database integration as well as in the cloud and on-prem.
Retrieval-augmented generation (RAG) will allow the developer to add even more customized contextual awareness on top of the LLM. This will reduce the need to retrain an LLM while giving developers the flexibility to keep embedding and matching up to date.
Vector search will also be defined by a type of pluggable knowledge module that allows businesses to bring in a wide range of information based on LLMs from various sources. Imagine a mobile field application that helps maintain power poles. A semantic image search might help identify problems with a pole’s physical structure, but with another knowledge module about plants, it might also warn the user of a toxic plant seen nearby.
AI Resources from Couchbase
To keep reading about vector search, strategies, and other topics related to artificial intelligence, check out the following resources:
-
- What are Vector Embeddings?
- Unlocking Next-Level Search: The Power of Vector Databases
- An Overview of Retrieval-Augmented Generation
- Couchbase Introduces a New AI Cloud Service, Capella iQ
- Large Language Models Explained
- A Guide to Generative AI Development
- How Generative AI Works with Couchbase
- GenAI: A New Tool in the Developer Toolbox
- Get hands-on with vector search:
Vector Search FAQ
Why is vector search important?
Vector search is important because it provides a novel way to find similarity and context between digital data, using the latest in machine learning and AI techniques.
What are vector search embeddings?
Vector embeddings are vectors that store a unique numeric representation of a piece of analyzed data. Large language models (LLMs) are used by machine learning (ML) tools to analyze input data and produce the vector embeddings that describe the data. The vector embedding is then stored in a database or file for another time.
What is the difference between traditional search and vector search?
The primary difference is that traditional search is optimized for finding precise and exact keyword or phrase matches, whereas vector search is designed to find similar concepts in a more defined context of meaning.
What are the challenges that come with vector search?
The primary challenge is that applications must rely on large language models (LLMs) to help create embeddings and find contextual matches. This is a new piece in today’s information architecture and requires careful security, performance, and scalability assessment.