Cross Data Center Replication (XDCR) is a database essential.
XDCR ensures database High Availability (HA), disaster recovery, and geo-locality. With the Couchbase Server 7.0 release, XDCR also supports new individual namespaces called Scopes and Collections within each database Bucket. Support for Scopes and Collections includes major architectural improvements for Cross Data Center Replication as well.
With Scopes and Collections, you can now use XDCR for data replication for specific microservices or tenant-specific data replication for multi-tenant applications. This article introduces a new Collections replication management feature and describes a behind-the-scenes XDCR architectural improvement.
These improvements to XDCR enable a whole new dimension of replication use cases. XDCR positions Couchbase Server 7.0 to support many more microservices or multi-tenant application use cases both today and into the future.
Before we dive into specifics, here is some important background reading if you’re not familiar with Cross Data Center Replication or related features:
-
- A quick refresher on XDCR architecture basics
- A deep dive into XDCR Advanced Filtering which I’ll touch on below
- An informative article on XDCR Replication Priority – a 6.5 feature that I’ll mention briefly below
Okay, let’s dive in.
Mapping Data Replication between Scopes & Collections for XDCR
If you only have a single cluster, managing Scopes and Collections is relatively straightforward. However, since XDCR involves multidimensional scaling, mapping and managing these new namespaces becomes more complex.
A single unique replication can still exist between a source and a target Bucket. This requirement isn’t changing.
But with the introduction of Scopes and Collections, there are two types of mappings to support
managing Collections within a Bucket-to-Bucket replication. These two types are implicit mapping and explicit mapping.
A mapping is a link between two namespaces of the same level, and it exists in the context of a Bucket-to-Bucket replication. A mapping can be between Scopes, or it can be between Collections.
Each Bucket-to-Bucket replication uses either implicit or explicit mapping to perform replication between source and target Collections. Replications use implicit mapping unless otherwise explicitly (pun intended) specified.
Implicit Mapping between Collections
Implicit mapping is the concept that a linkage should be established if the same named namespace exists in both the source and target Buckets.
If both the source and target Bucket contain identically named Scopes and/or Collections, then they are implicitly mapped. For example, under implicit mapping, if a source Bucket contains a namespace Scope1.Collection1, then replication will take place if the target Bucket also contains Scope1.Collection1.
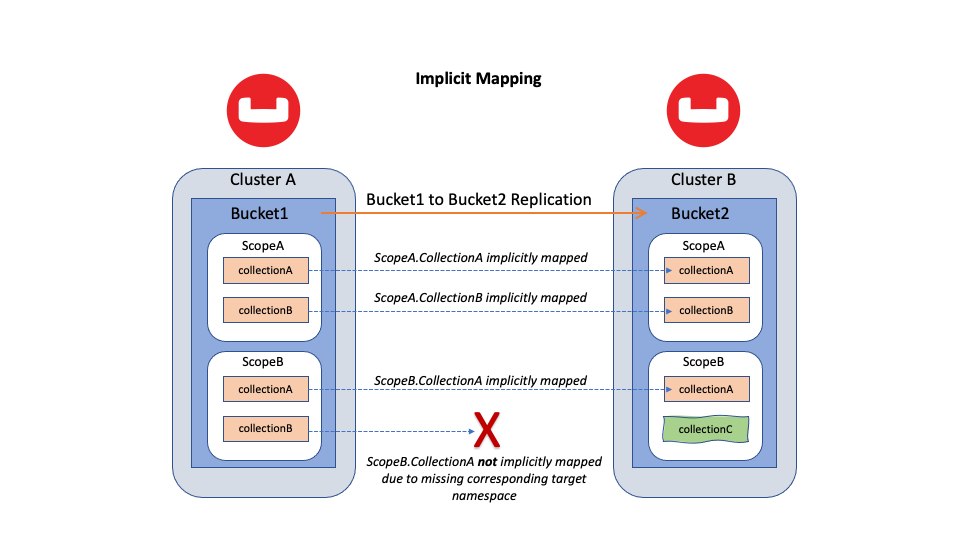
Figure 1: Cross Data Center Replication (XDCR) between two Buckets given implicit mapping
Figure 1 above shows a Bucket-to-Bucket replication using implicit mapping. Note that source default Collections and target default Collections are mapped together (not shown in the figure).
Any unmapped namespaces will not be replicated. If the unmapped namespaces are created later, then XDCR catches up on missing data using a backfill replication. (I will explain the backfill pipeline in a later section.)
Explicit Mapping between Collections
For you need more granular control over your data replication, you should try explicit mapping.
Explicit mapping requires users to explicitly define namespace relationships. Mapping a Scope to another Scope means all Collections within that Scope are implicitly mapped. However, mapping one Collection to another Collection does not affect any other namespaces.
Explicit mapping is accomplished via the use of mapping rules via the command-line interface (CLI). The XDCR Console UI provides an abstraction so you don’t have to enter mapping rules manually.
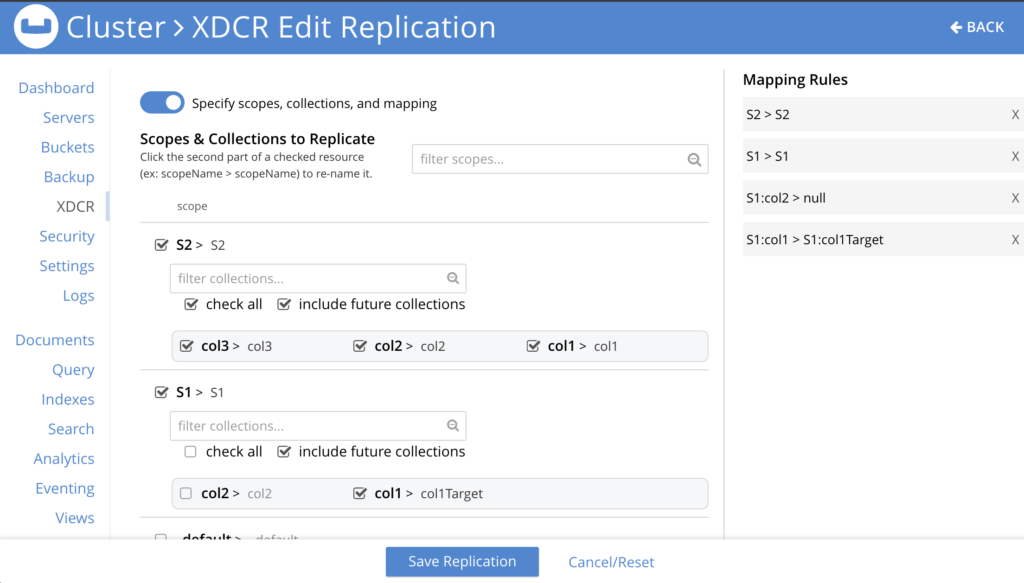
Figure 3: XDCR UI provides an easy-to-use experience for setting up explicit mapping and hides the need to manually enter mapping rules
The Couchbase Server documentation includes a detailed explanation of the mapping rules and how to use them. Mapping rules programmatically tell XDCR how to match the namespaces by name.
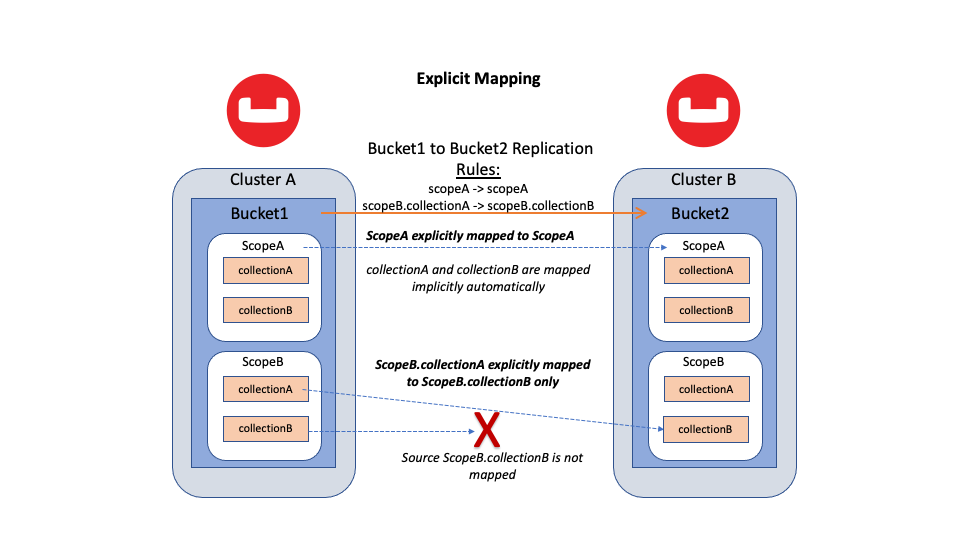
Figure 2: Replication between two Buckets using explicit mapping with two rules specified: a Scope-to-Scope mapping rule and a Collection-to-Collection mapping rule
Explicit mapping rules give you a new level of flexibility in mapping Collections. You can also change the rules on the fly. XDCR takes any new rules and then intelligently ensures that all data is replicated. We’ll
Using Migration Mode to Migrate to Collections
When you upgrade to Couchbase Server 7.0, all of your data resides in the (new) default Collection within your existing Bucket(s).
Using migration mode in Cross Data Center Replication (XDCR), you can migrate data to individual Collections on a target Bucket without any application downtime. Migration mode is a specialized version of the explicit mapping. It utilizes the XDCR Advanced Filtering engine to perform stream-based filtering as documents are being streamed from the source Bucket. Depending on the migration rules you specify, the document is then replicated to the specified target Collection.
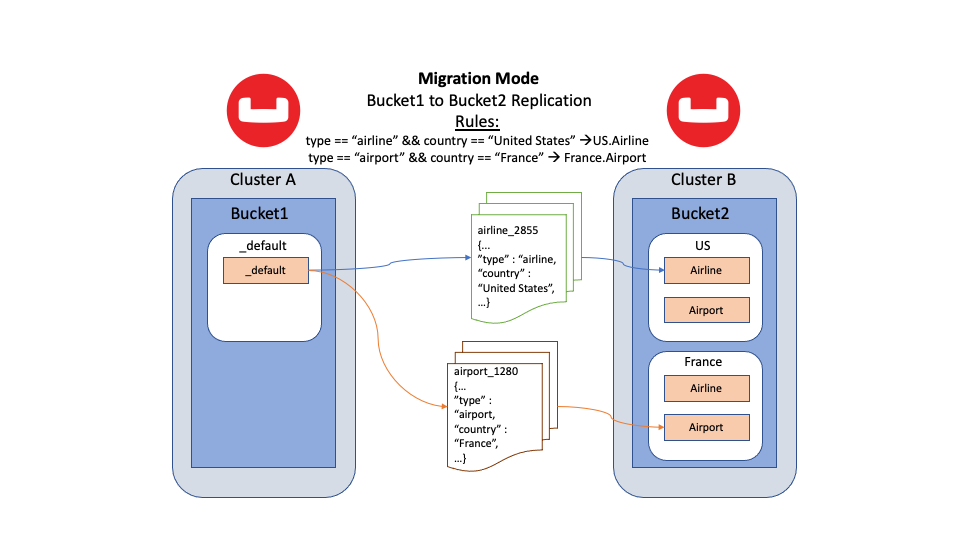
Figure 4: Migration mode using different migration rules to route documents to their respective locations
Couchbase Server documentation has more details and examples covering migration mode.
Behind the Scenes of XDCR with Scopes & Collections
Main Pipeline
When a replication is created, it is translated into a replication specification and stored internally. XDCR then reads the replication spec (and its settings) and creates a pipeline that requests data from the source Bucket. The pipeline faithfully replicates each document to the target Bucket (barring any Advanced Filtering in place).
The above process remains the same in Couchbase Server 7.0. So if one of your source Buckets contains multiple source Collections, XDCR requests them all. This behavior is called a main pipeline. The main pipeline replicates a source document to the target using implicit or explicit mapping. If the target cluster does not contain the mapped namespace, XDCR drops the document “on the floor”. It then continues to replicate the next mutation.
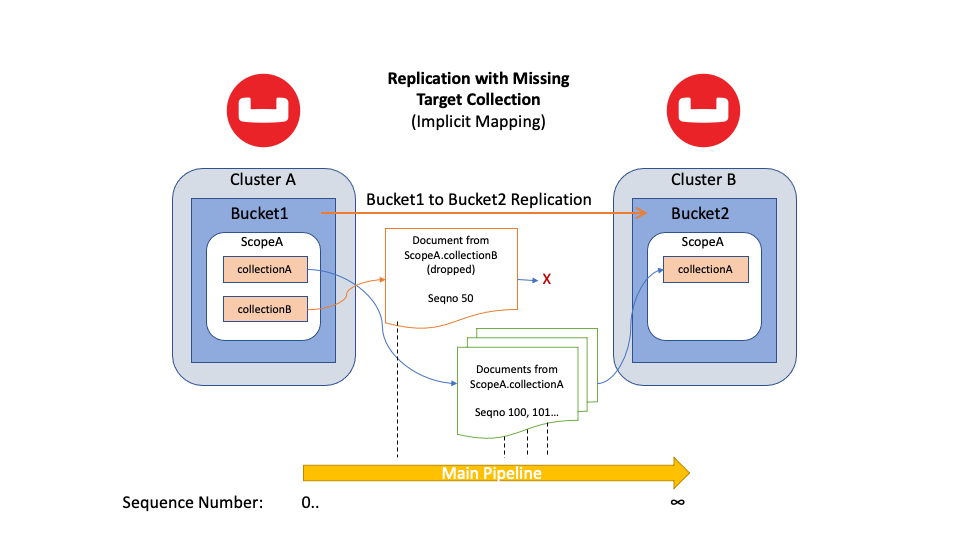
Figure 5: Replicating all documents from source Bucket with a missing target Collection
During replication, XDCR continuously watches for new or removed target Collections. When XDCR detects a new target Collection, it checks if a new mapping can be established. If a new mapping is possible, then the main pipeline successfully replicates the data to the target namespace.
It’s important to understand that a replication stream is sequential. If XDCR previously dropped a document, a sequence stream cannot “rewind” to an earlier point for the missed document. XDCR needs to replicate any missed mutations; otherwise, there will be missing data.
One side note: This inability to rewind (without Collections) is exactly why there is an option called “Save and Restart Replication” when editing the Advanced Filtering Expression in Couchbase Server 6.5. When you use “Save and Restart Replication”, the pipeline starts over and streams from sequence 0 to ensure that all documents are replicated. This solution won’t work for Collections.
Backfill Pipeline
In Couchbase Server 7.0, XDCR now includes the concept of a backfill pipeline.
The backfill pipeline’s purpose is to stream data that the main pipeline dropped earlier. This approach ensures that all the data from a namespace is replicated.
When a new target Collection is detected, XDCR automatically creates a backfill pipeline and streams the missing data. In the meantime, the main pipeline remains responsible for streaming any ongoing mutations to the new target Collection.
The backfill pipelines always start in low-priority mode to minimize the performance impact on the main pipelines. Once the backfill pipeline has finished streaming missing data – based on a definite end sequence number – then the backfill pipeline is automatically torn down.
The whole backfill replication construction and teardown process is completely automated, so it happens behind the scenes without alerting users. However, it’s important that you understand the architecture since your users might notice that some documents created later in time on the source Buckets arrive prior to the earlier mutations.
Figure 6 below illustrates how the backfill replication pipeline works.
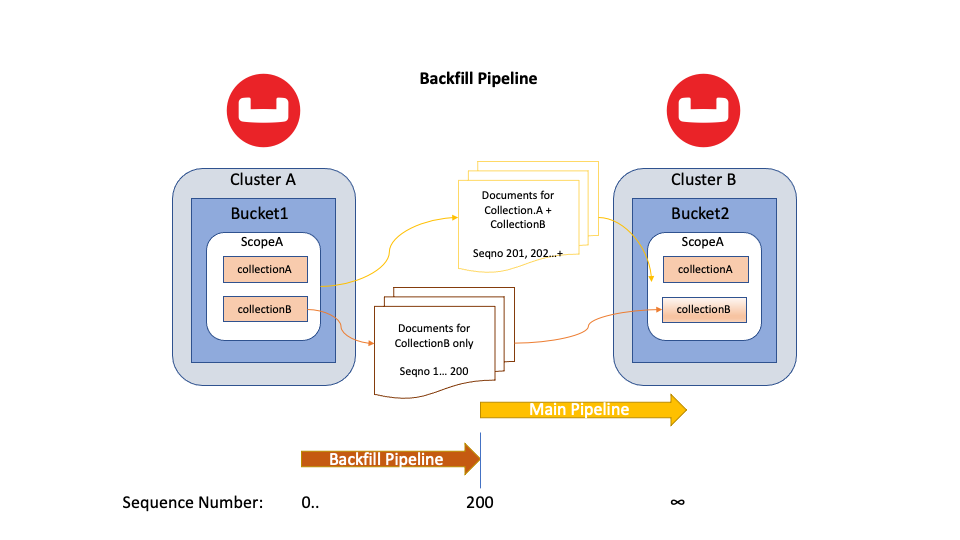
Figure 6: Backfill Pipeline streaming data for collectionB only for previously missed sequence numbers
In the above diagram, a new collectionB was created on the target Bucket. XDCR on Cluster A detected the new Collection when its main pipeline was streaming out mutations at sequence number 200. It then created a backfill pipeline, which is responsible for collectionB mutations from sequence number 0 to 200. All ongoing collectionB mutations (201+) will go through the main pipeline.
In summary, the main pipeline enables XDCR to continue to replicate the latest mutations continuously; the backfill pipeline allows a lower priority replication stream to replicate any previously missed data.
Conclusion
In summary, XDCR Collections Replication intelligently monitors both source and target Collections management changes. It can replicate either dynamically (via implicit mapping) or programmatically (via explicit mapping). XDCR Collections allows you to dynamically change modes between implicit and explicit mapping, as well as to modify explicit mapping rules on the fly without the need to restart replication from sequence 0.
Scopes and Collections in Couchbase Server 7.0 open up a whole new world of use cases for Couchbase users and customers. With XDCR’s support of Scopes and Collections – and the flexibility it provides – Couchbase Server addresses even more customer needs than any previous releases.