I have the following setup:
- couchbase/server 4.6.2 docker container
- 1 cluster, 4 nodes
- 4 Amazon m3.xlarge instances, 1 node per instance
- Persistent drives
- One bucket, with 1 sync gateway node hooked up
- Two replicas per node
The problem is every 30 seconds a node or two keeps going down and the CPU usage goes to 100%. This is essentially a staging environment with very little load.
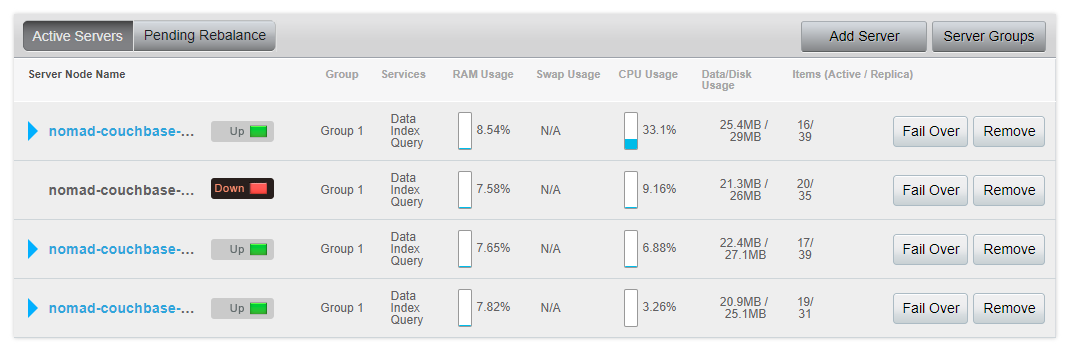
I have looked at the logs on the machine but nothing is really telling me what the problems is. Eventually, the situation deteriorates and all nodes go down:

Is there something wrong with my setup?