Hi everybody,
I’m working on a Couchbase 6 cluster with 5 nodes.
I have a Bucket with 10M documents (14GB disk used) and 16GB ram quota.
I perform an aggregation query using python sdk over an index.
Aggregation query example:
SELECT SPLIT(meta().id, "::")[0] as uuid,
sum(views) as views
from hit_counter
where "visit" in tags
and owner == "pippo"
and SPLIT(meta().id, "::")[1] between "2022-05-14T00:00:00" and "2022-05-15T00:00:00"
and SPLIT(meta().id, "::")[0] is not missing
group by SPLIT(meta().id, "::")[0]
Index is defined as follow:
CREATE INDEX `idx_aggregate` ON `hit_counter`((split((meta().`id`), "::")[0]),(split((meta().`id`), "::")[1]),`tags`,`views`) WHERE (`owner` = "pippo")
I increase index scan timeout because 2 minutes was not enough.
I set query timeout to 5 minutes.
Now on first execution the 5 minutes timeout is reached but then when I run this query again it is executed without problem in 90s.
Get 664145 documents in 91.51174807548523 seconds
I think that on first execution it gets stuck for some reason, maybe I should increase timeout because 5 minutes are not enough?
I can solve this problem using a retry but I was looking for an explanation and a more elegant solution, thanks in advance
@amarino This behavior could be due to cache warmup, where the initial query is paying to retrieve index info that was not in memory cache, and subsequent queries then benefit from it already being memory-resident. Have you checked the memory resident ratio for the index in the UI to see whether it is less than 100% resident before issuing the initial “cold” query, then resident ratio increases after that query is run?
Try switch the 0th,1st index key because of predicate of time will quickly eliminate the index entries.
Also if you aways looking visit in tags remove tags as index key and add “visit” in tags in index WHERE clause.
CREATE INDEX `idx_aggregate` ON `hit_counter`((split((meta().`id`), "::")[1]),(split((meta().`id`), "::")[0]),`tags`,`views`)
WHERE (`owner` = "pippo")
Hi @vsr1 and thanks for suggestions.
I update the index in the following way:
CREATE INDEX `idx_aggregate` ON `hit_counter`((split((meta().`id`), "::")[1]), (split((meta().`id`), "::")[0]),`views`) WHERE (`owner` = "pippo" AND "visit" IN `tags`)
But unfortunately the query is 2x slower than before
The new index is smaller than the previous so it is a bit strange, the query executed is the same, I just add the USE INDEX clause to point to the correct index.
Hi @Kevin.Cherkauer and thanks for the explanation.
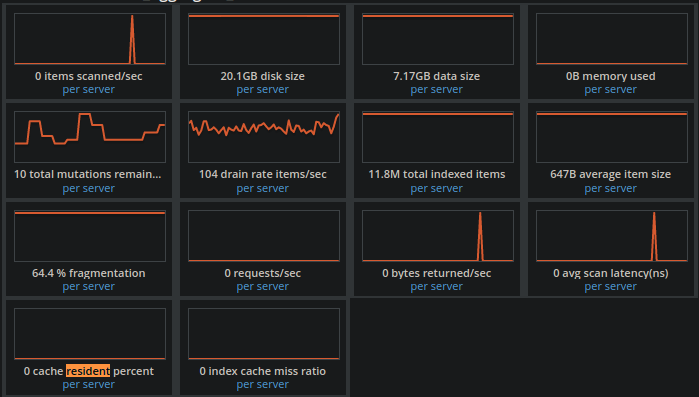
I check bucket statistics on UI and on summary I find 100% active docs resident per server but
on index statistics I see always 0 cache resident percent per server and 0B memory used per server even during query execution. I am using Couchbase community edition.
@amarino That shows global stats, although global 0% resident implies they must all be 0%. What I was referring to is to check the index-specific resident ratios the UI shows. The Capella (cloud) version is shown here:
(see “RESIDENT RATIO” column) and there is a similar page for on-prem.
What I am suspecting is that the index being used by the query has low resident ratio before slow executions but that its resident ratio will increase as a result of an execution, so subsequent executions shortly thereafter will be faster. The resident ratio may fall again when queries are not hitting that index if there is memory pressure (not enough memory to keep all the indexes memory resident).