Hi there,
I wrote similar post long time ago, but it was related to Couchbase Server 4.0 CE. I got a feedback from you it’s probably because of some common bugs and I should wait until 4.1 appear cause it should be already fixed.
So I was waiting and waiting and finally upgraded CB to 4.1 CE. Great! Unfortunately my problem still exist.
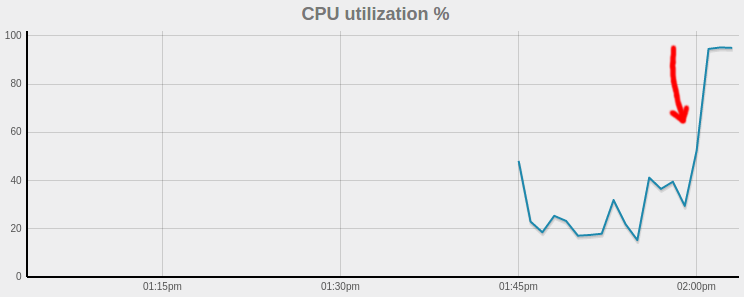
I’m trying to query for limited number of documents (<100) from bucket that has 9000 elements but I can’t get it work… fast (i mean, less than 30 seconds). It’s ok when only 1 worker is executing this query (few ms to get the result) but when I run for example 60, it’s getting very slow (60s per query (CBQ shows: Elapsed 30s, Execution: 7s, Result Size: 71343B)) and I can see 100% CPU usage in Couchbase metrics. What the hell? I tried with different consistency level - without difference.
Some details:
- each document has about 15 properties - it’s basically small, short varchars and integers
- bucket has 9,000 records but there might be >2,000,000 in the future
- I have primary index and 3 secondary indexes on this bucket (filtering the data by one property which is integer - 0, 1 or 2)
- secondary index: CREATE INDEX
queue-test-indexONqueue(service) WHEREservice= 1 USING GSI - query is very simple: SELECT * FROM
queueUSE INDEX (queue-test-indexUSING GSI) WHEREservice= 1 ORDER BYcreatedLIMIT 60 OFFSET 0 - each worker is using different offset but the same secondary index
- machine has 4 core CPU, 32GB RAM
Below you can find EXPLAIN result:
[
{
"#operator": "Sequence",
"~children": [
{
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan",
"index": "queue-test-index",
"keyspace": "queue",
"namespace": "default",
"spans": [
{
"Range": {
"High": [
"1"
],
"Inclusion": 3,
"Low": [
"1"
]
}
}
],
"using": "gsi"
},
{
"#operator": "Parallel",
"~child": {
"#operator": "Sequence",
"~children": [
{
"#operator": "Fetch",
"keyspace": "queue",
"namespace": "default"
},
{
"#operator": "Filter",
"condition": "((`queue`.`service`) = 1)"
},
{
"#operator": "InitialProject",
"result_terms": [
{
"expr": "self",
"star": true
}
]
}
]
}
}
]
},
{
"#operator": "Order",
"sort_terms": [
{
"expr": "(`queue`.`created`)"
}
]
},
{
"#operator": "Offset",
"expr": "0"
},
{
"#operator": "Limit",
"expr": "60"
},
{
"#operator": "FinalProject"
}
]
}
]
Can somebody help me? I can still use views (which are perfect by the way) but it’s not an ideal solution for me…
Cheers